 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld of Forms: Deformable Geometric Templates for One-Shot Surface Meshing in Coronary CT Angiography
Sep 18, 2024Deep learning-based medical image segmentation and surface mesh generation typically involve a sequential pipeline from image to segmentation to meshes, often requiring large training datasets while making limited use of prior geometric knowledge. This may lead to topological inconsistencies and suboptimal performance in low-data regimes. To address these challenges, we propose a data-efficient deep learning method for direct 3D anatomical object surface meshing using geometric priors. Our approach employs a multi-resolution graph neural network that operates on a prior geometric template which is deformed to fit object boundaries of interest. We show how different templates may be used for the different surface meshing targets, and introduce a novel masked autoencoder pretraining strategy for 3D spherical data. The proposed method outperforms nnUNet in a one-shot setting for segmentation of the pericardium, left ventricle (LV) cavity and the LV myocardium. Similarly, the method outperforms other lumen segmentation operating on multi-planar reformatted images. Results further indicate that mesh quality is on par with or improves upon marching cubes post-processing of voxel mask predictions, while remaining flexible in the choice of mesh triangulation prior, thus paving the way for more accurate and topologically consistent 3D medical object surface meshing.
Deep Learning from Dual-Energy Information for Whole-Heart Segmentation in Dual-Energy and Single-Energy Non-Contrast-Enhanced Cardiac CT
Aug 10, 2020



Deep learning-based whole-heart segmentation in coronary CT angiography (CCTA) allows the extraction of quantitative imaging measures for cardiovascular risk prediction. Automatic extraction of these measures in patients undergoing only non-contrast-enhanced CT (NCCT) scanning would be valuable. In this work, we leverage information provided by a dual-layer detector CT scanner to obtain a reference standard in virtual non-contrast (VNC) CT images mimicking NCCT images, and train a 3D convolutional neural network (CNN) for the segmentation of VNC as well as NCCT images. Contrast-enhanced acquisitions on a dual-layer detector CT scanner were reconstructed into a CCTA and a perfectly aligned VNC image. In each CCTA image, manual reference segmentations of the left ventricular (LV) myocardium, LV cavity, right ventricle, left atrium, right atrium, ascending aorta, and pulmonary artery trunk were obtained and propagated to the corresponding VNC image. These VNC images and reference segmentations were used to train 3D CNNs for automatic segmentation in either VNC images or NCCT images. Automatic segmentations in VNC images showed good agreement with reference segmentations, with an average Dice similarity coefficient of 0.897 \pm 0.034 and an average symmetric surface distance of 1.42 \pm 0.45 mm. Volume differences [95% confidence interval] between automatic NCCT and reference CCTA segmentations were -19 [-67; 30] mL for LV myocardium, -25 [-78; 29] mL for LV cavity, -29 [-73; 14] mL for right ventricle, -20 [-62; 21] mL for left atrium, and -19 [-73; 34] mL for right atrium, respectively. In 214 (74%) NCCT images from an independent multi-vendor multi-center set, two observers agreed that the automatic segmentation was mostly accurate or better. This method might enable quantification of additional cardiac measures from NCCT images for improved cardiovascular risk prediction.
Improving Myocardium Segmentation in Cardiac CT Angiography using Spectral Information
Sep 27, 2018
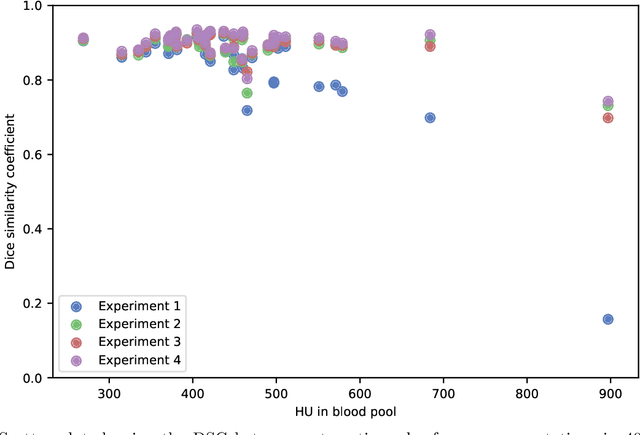
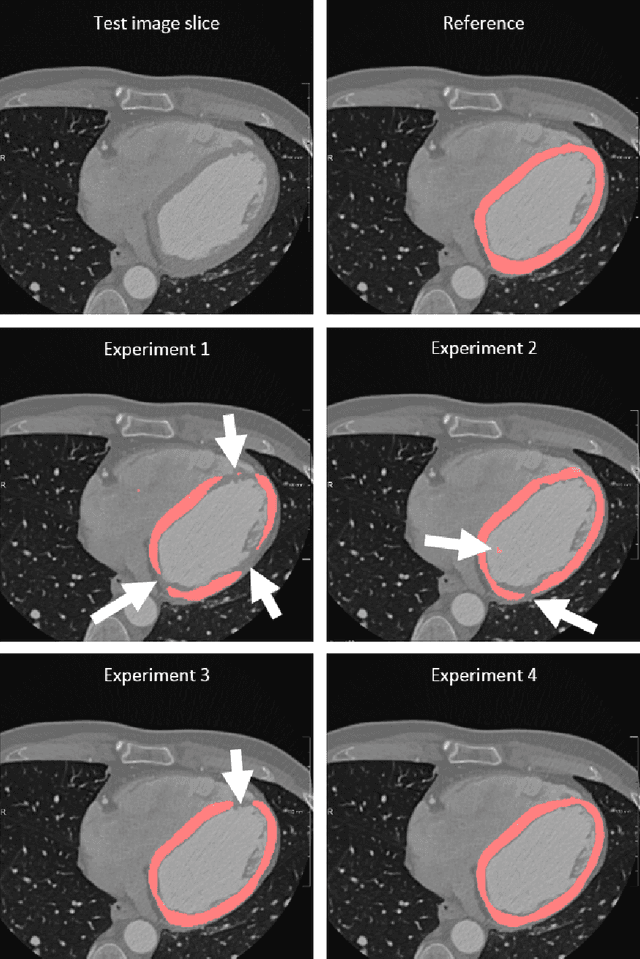
Accurate segmentation of the left ventricle myocardium in cardiac CT angiography (CCTA) is essential for e.g. the assessment of myocardial perfusion. Automatic deep learning methods for segmentation in CCTA might suffer from differences in contrast-agent attenuation between training and test data due to non-standardized contrast administration protocols and varying cardiac output. We propose augmentation of the training data with virtual mono-energetic reconstructions from a spectral CT scanner which show different attenuation levels of the contrast agent. We compare this to an augmentation by linear scaling of all intensity values, and combine both types of augmentation. We train a 3D fully convolutional network (FCN) with 10 conventional CCTA images and corresponding virtual mono-energetic reconstructions acquired on a spectral CT scanner, and evaluate on 40 CCTA scans acquired on a conventional CT scanner. We show that training with data augmentation using virtual mono-energetic images improves upon training with only conventional images (Dice similarity coefficient (DSC) 0.895 $\pm$ 0.039 vs. 0.846 $\pm$ 0.125). In comparison, training with data augmentation using linear scaling improves the DSC to 0.890 $\pm$ 0.039. Moreover, combining the results of both augmentation methods leads to a DSC of 0.901 $\pm$ 0.036, showing that both augmentations lead to different local improvements of the segmentations. Our results indicate that virtual mono-energetic images improve the generalization of an FCN used for myocardium segmentation in CCTA images.