 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Myocardium Segmentation in Cardiac CT Angiography using Spectral Information
Paper and Code
Sep 27, 2018
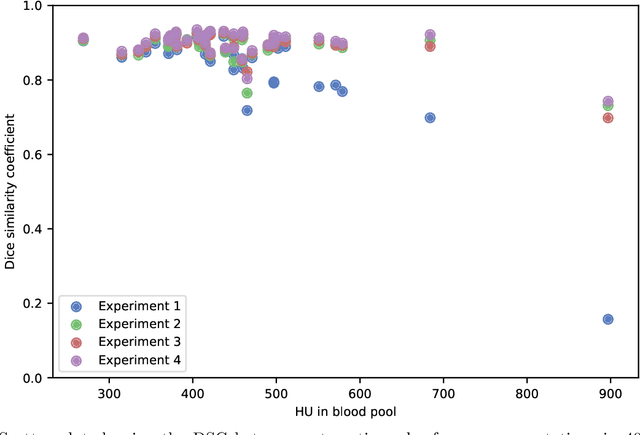
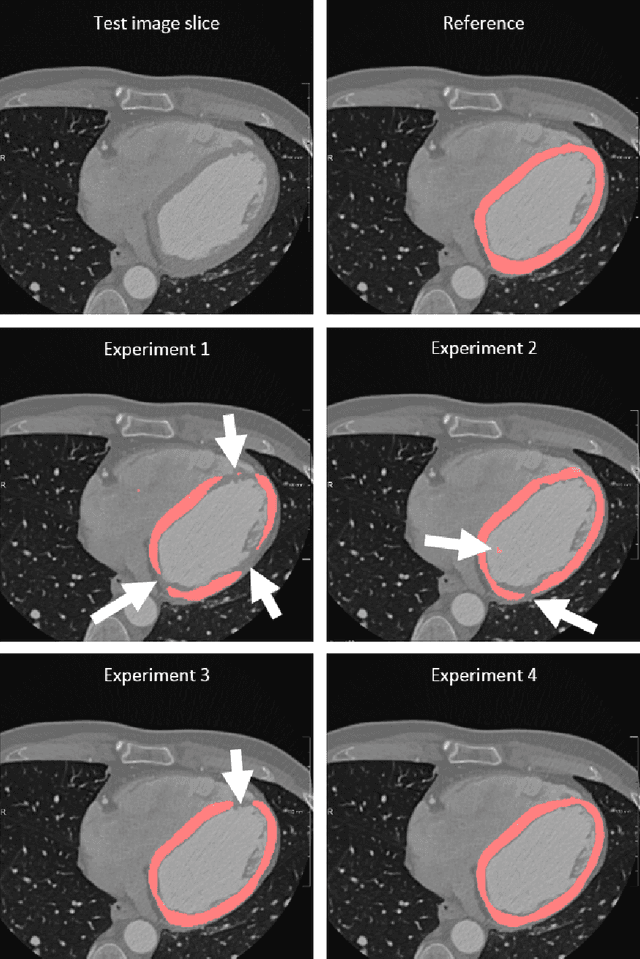
Accurate segmentation of the left ventricle myocardium in cardiac CT angiography (CCTA) is essential for e.g. the assessment of myocardial perfusion. Automatic deep learning methods for segmentation in CCTA might suffer from differences in contrast-agent attenuation between training and test data due to non-standardized contrast administration protocols and varying cardiac output. We propose augmentation of the training data with virtual mono-energetic reconstructions from a spectral CT scanner which show different attenuation levels of the contrast agent. We compare this to an augmentation by linear scaling of all intensity values, and combine both types of augmentation. We train a 3D fully convolutional network (FCN) with 10 conventional CCTA images and corresponding virtual mono-energetic reconstructions acquired on a spectral CT scanner, and evaluate on 40 CCTA scans acquired on a conventional CT scanner. We show that training with data augmentation using virtual mono-energetic images improves upon training with only conventional images (Dice similarity coefficient (DSC) 0.895 $\pm$ 0.039 vs. 0.846 $\pm$ 0.125). In comparison, training with data augmentation using linear scaling improves the DSC to 0.890 $\pm$ 0.039. Moreover, combining the results of both augmentation methods leads to a DSC of 0.901 $\pm$ 0.036, showing that both augmentations lead to different local improvements of the segmentations. Our results indicate that virtual mono-energetic images improve the generalization of an FCN used for myocardium segmentation in CCTA images.