 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaVoxel: Joint Diffusion Modeling of Imaging and Clinical Metadata
Dec 12, 2025Modern deep learning methods have achieved impressive results across tasks from disease classification, estimating continuous biomarkers, to generating realistic medical images. Most of these approaches are trained to model conditional distributions defined by a specific predictive direction with a specific set of input variables. We introduce MetaVoxel, a generative joint diffusion modeling framework that models the joint distribution over imaging data and clinical metadata by learning a single diffusion process spanning all variables. By capturing the joint distribution, MetaVoxel unifies tasks that traditionally require separate conditional models and supports flexible zero-shot inference using arbitrary subsets of inputs without task-specific retraining. Using more than 10,000 T1-weighted MRI scans paired with clinical metadata from nine datasets, we show that a single MetaVoxel model can perform image generation, age estimation, and sex prediction, achieving performance comparable to established task-specific baselines. Additional experiments highlight its capabilities for flexible inference. Together, these findings demonstrate that joint multimodal diffusion offers a promising direction for unifying medical AI models and enabling broader clinical applicability.
Lifespan Pancreas Morphology for Control vs Type 2 Diabetes using AI on Largescale Clinical Imaging
Aug 20, 2025Purpose: Understanding how the pancreas changes is critical for detecting deviations in type 2 diabetes and other pancreatic disease. We measure pancreas size and shape using morphological measurements from ages 0 to 90. Our goals are to 1) identify reliable clinical imaging modalities for AI-based pancreas measurement, 2) establish normative morphological aging trends, and 3) detect potential deviations in type 2 diabetes. Approach: We analyzed a clinically acquired dataset of 2533 patients imaged with abdominal CT or MRI. We resampled the scans to 3mm isotropic resolution, segmented the pancreas using automated methods, and extracted 13 morphological pancreas features across the lifespan. First, we assessed CT and MRI measurements to determine which modalities provide consistent lifespan trends. Second, we characterized distributions of normative morphological patterns stratified by age group and sex. Third, we used GAMLSS regression to model pancreas morphology trends in 1350 patients matched for age, sex, and type 2 diabetes status to identify any deviations from normative aging associated with type 2 diabetes. Results: When adjusting for confounders, the aging trends for 10 of 13 morphological features were significantly different between patients with type 2 diabetes and non-diabetic controls (p < 0.05 after multiple comparisons corrections). Additionally, MRI appeared to yield different pancreas measurements than CT using our AI-based method. Conclusions: We provide lifespan trends demonstrating that the size and shape of the pancreas is altered in type 2 diabetes using 675 control patients and 675 diabetes patients. Moreover, our findings reinforce that the pancreas is smaller in type 2 diabetes. Additionally, we contribute a reference of lifespan pancreas morphology from a large cohort of non-diabetic control patients in a clinical setting.
Multipath cycleGAN for harmonization of paired and unpaired low-dose lung computed tomography reconstruction kernels
May 28, 2025Reconstruction kernels in computed tomography (CT) affect spatial resolution and noise characteristics, introducing systematic variability in quantitative imaging measurements such as emphysema quantification. Choosing an appropriate kernel is therefore essential for consistent quantitative analysis. We propose a multipath cycleGAN model for CT kernel harmonization, trained on a mixture of paired and unpaired data from a low-dose lung cancer screening cohort. The model features domain-specific encoders and decoders with a shared latent space and uses discriminators tailored for each domain.We train the model on 42 kernel combinations using 100 scans each from seven representative kernels in the National Lung Screening Trial (NLST) dataset. To evaluate performance, 240 scans from each kernel are harmonized to a reference soft kernel, and emphysema is quantified before and after harmonization. A general linear model assesses the impact of age, sex, smoking status, and kernel on emphysema. We also evaluate harmonization from soft kernels to a reference hard kernel. To assess anatomical consistency, we compare segmentations of lung vessels, muscle, and subcutaneous adipose tissue generated by TotalSegmentator between harmonized and original images. Our model is benchmarked against traditional and switchable cycleGANs. For paired kernels, our approach reduces bias in emphysema scores, as seen in Bland-Altman plots (p<0.05). For unpaired kernels, harmonization eliminates confounding differences in emphysema (p>0.05). High Dice scores confirm preservation of muscle and fat anatomy, while lung vessel overlap remains reasonable. Overall, our shared latent space multipath cycleGAN enables robust harmonization across paired and unpaired CT kernels, improving emphysema quantification and preserving anatomical fidelity.
Pitfalls of defacing whole-head MRI: re-identification risk with diffusion models and compromised research potential
Jan 31, 2025Defacing is often applied to head magnetic resonance image (MRI) datasets prior to public release to address privacy concerns. The alteration of facial and nearby voxels has provoked discussions about the true capability of these techniques to ensure privacy as well as their impact on downstream tasks. With advancements in deep generative models, the extent to which defacing can protect privacy is uncertain. Additionally, while the altered voxels are known to contain valuable anatomical information, their potential to support research beyond the anatomical regions directly affected by defacing remains uncertain. To evaluate these considerations, we develop a refacing pipeline that recovers faces in defaced head MRIs using cascaded diffusion probabilistic models (DPMs). The DPMs are trained on images from 180 subjects and tested on images from 484 unseen subjects, 469 of whom are from a different dataset. To assess whether the altered voxels in defacing contain universally useful information, we also predict computed tomography (CT)-derived skeletal muscle radiodensity from facial voxels in both defaced and original MRIs. The results show that DPMs can generate high-fidelity faces that resemble the original faces from defaced images, with surface distances to the original faces significantly smaller than those of a population average face (p < 0.05). This performance also generalizes well to previously unseen datasets. For skeletal muscle radiodensity predictions, using defaced images results in significantly weaker Spearman's rank correlation coefficients compared to using original images (p < 10-4). For shin muscle, the correlation is statistically significant (p < 0.05) when using original images but not statistically significant (p > 0.05) when any defacing method is applied, suggesting that defacing might not only fail to protect privacy but also eliminate valuable information.
Brain age identification from diffusion MRI synergistically predicts neurodegenerative disease
Oct 29, 2024



Estimated brain age from magnetic resonance image (MRI) and its deviation from chronological age can provide early insights into potential neurodegenerative diseases, supporting early detection and implementation of prevention strategies. Diffusion MRI (dMRI), a widely used modality for brain age estimation, presents an opportunity to build an earlier biomarker for neurodegenerative disease prediction because it captures subtle microstructural changes that precede more perceptible macrostructural changes. However, the coexistence of macro- and micro-structural information in dMRI raises the question of whether current dMRI-based brain age estimation models are leveraging the intended microstructural information or if they inadvertently rely on the macrostructural information. To develop a microstructure-specific brain age, we propose a method for brain age identification from dMRI that minimizes the model's use of macrostructural information by non-rigidly registering all images to a standard template. Imaging data from 13,398 participants across 12 datasets were used for the training and evaluation. We compare our brain age models, trained with and without macrostructural information minimized, with an architecturally similar T1-weighted (T1w) MRI-based brain age model and two state-of-the-art T1w MRI-based brain age models that primarily use macrostructural information. We observe difference between our dMRI-based brain age and T1w MRI-based brain age across stages of neurodegeneration, with dMRI-based brain age being older than T1w MRI-based brain age in participants transitioning from cognitively normal (CN) to mild cognitive impairment (MCI), but younger in participants already diagnosed with Alzheimer's disease (AD). Approximately 4 years before MCI diagnosis, dMRI-based brain age yields better performance than T1w MRI-based brain ages in predicting transition from CN to MCI.
Multi-Modality Conditioned Variational U-Net for Field-of-View Extension in Brain Diffusion MRI
Sep 20, 2024
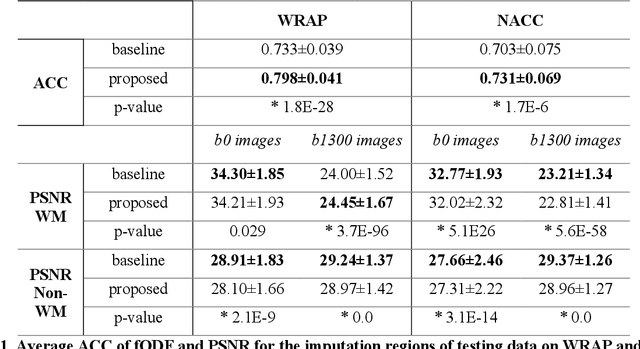

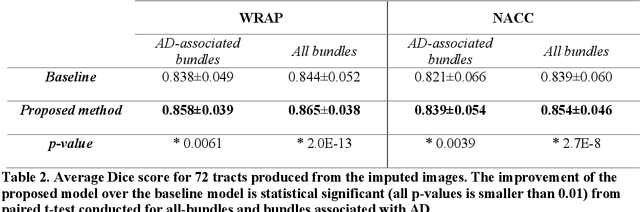
An incomplete field-of-view (FOV) in diffusion magnetic resonance imaging (dMRI) can severely hinder the volumetric and bundle analyses of whole-brain white matter connectivity. Although existing works have investigated imputing the missing regions using deep generative models, it remains unclear how to specifically utilize additional information from paired multi-modality data and whether this can enhance the imputation quality and be useful for downstream tractography. To fill this gap, we propose a novel framework for imputing dMRI scans in the incomplete part of the FOV by integrating the learned diffusion features in the acquired part of the FOV to the complete brain anatomical structure. We hypothesize that by this design the proposed framework can enhance the imputation performance of the dMRI scans and therefore be useful for repairing whole-brain tractography in corrupted dMRI scans with incomplete FOV. We tested our framework on two cohorts from different sites with a total of 96 subjects and compared it with a baseline imputation method that treats the information from T1w and dMRI scans equally. The proposed framework achieved significant improvements in imputation performance, as demonstrated by angular correlation coefficient (p < 1E-5), and in downstream tractography accuracy, as demonstrated by Dice score (p < 0.01). Results suggest that the proposed framework improved imputation performance in dMRI scans by specifically utilizing additional information from paired multi-modality data, compared with the baseline method. The imputation achieved by the proposed framework enhances whole brain tractography, and therefore reduces the uncertainty when analyzing bundles associated with neurodegenerative.
Field-of-View Extension for Diffusion MRI via Deep Generative Models
May 06, 2024



Purpose: In diffusion MRI (dMRI), the volumetric and bundle analyses of whole-brain tissue microstructure and connectivity can be severely impeded by an incomplete field-of-view (FOV). This work aims to develop a method for imputing the missing slices directly from existing dMRI scans with an incomplete FOV. We hypothesize that the imputed image with complete FOV can improve the whole-brain tractography for corrupted data with incomplete FOV. Therefore, our approach provides a desirable alternative to discarding the valuable dMRI data, enabling subsequent tractography analyses that would otherwise be challenging or unattainable with corrupted data. Approach: We propose a framework based on a deep generative model that estimates the absent brain regions in dMRI scans with incomplete FOV. The model is capable of learning both the diffusion characteristics in diffusion-weighted images (DWI) and the anatomical features evident in the corresponding structural images for efficiently imputing missing slices of DWI outside of incomplete FOV. Results: For evaluating the imputed slices, on the WRAP dataset the proposed framework achieved PSNRb0=22.397, SSIMb0=0.905, PSNRb1300=22.479, SSIMb1300=0.893; on the NACC dataset it achieved PSNRb0=21.304, SSIMb0=0.892, PSNRb1300=21.599, SSIMb1300= 0.877. The proposed framework improved the tractography accuracy, as demonstrated by an increased average Dice score for 72 tracts (p < 0.001) on both the WRAP and NACC datasets. Conclusions: Results suggest that the proposed framework achieved sufficient imputation performance in dMRI data with incomplete FOV for improving whole-brain tractography, thereby repairing the corrupted data. Our approach achieved more accurate whole-brain tractography results with extended and complete FOV and reduced the uncertainty when analyzing bundles associated with Alzheimer's Disease.
Tractography with T1-weighted MRI and associated anatomical constraints on clinical quality diffusion MRI
Mar 27, 2024Diffusion MRI (dMRI) streamline tractography, the gold standard for in vivo estimation of brain white matter (WM) pathways, has long been considered indicative of macroscopic relationships with WM microstructure. However, recent advances in tractography demonstrated that convolutional recurrent neural networks (CoRNN) trained with a teacher-student framework have the ability to learn and propagate streamlines directly from T1 and anatomical contexts. Training for this network has previously relied on high-resolution dMRI. In this paper, we generalize the training mechanism to traditional clinical resolution data, which allows generalizability across sensitive and susceptible study populations. We train CoRNN on a small subset of the Baltimore Longitudinal Study of Aging (BLSA), which better resembles clinical protocols. Then, we define a metric, termed the epsilon ball seeding method, to compare T1 tractography and traditional diffusion tractography at the streamline level. Under this metric, T1 tractography generated by CoRNN reproduces diffusion tractography with approximately two millimeters of error.
Evaluation of Mean Shift, ComBat, and CycleGAN for Harmonizing Brain Connectivity Matrices Across Sites
Jan 24, 2024



Connectivity matrices derived from diffusion MRI (dMRI) provide an interpretable and generalizable way of understanding the human brain connectome. However, dMRI suffers from inter-site and between-scanner variation, which impedes analysis across datasets to improve robustness and reproducibility of results. To evaluate different harmonization approaches on connectivity matrices, we compared graph measures derived from these matrices before and after applying three harmonization techniques: mean shift, ComBat, and CycleGAN. The sample comprises 168 age-matched, sex-matched normal subjects from two studies: the Vanderbilt Memory and Aging Project (VMAP) and the Biomarkers of Cognitive Decline Among Normal Individuals (BIOCARD). First, we plotted the graph measures and used coefficient of variation (CoV) and the Mann-Whitney U test to evaluate different methods' effectiveness in removing site effects on the matrices and the derived graph measures. ComBat effectively eliminated site effects for global efficiency and modularity and outperformed the other two methods. However, all methods exhibited poor performance when harmonizing average betweenness centrality. Second, we tested whether our harmonization methods preserved correlations between age and graph measures. All methods except for CycleGAN in one direction improved correlations between age and global efficiency and between age and modularity from insignificant to significant with p-values less than 0.05.
Predicting Age from White Matter Diffusivity with Residual Learning
Nov 06, 2023Imaging findings inconsistent with those expected at specific chronological age ranges may serve as early indicators of neurological disorders and increased mortality risk. Estimation of chronological age, and deviations from expected results, from structural MRI data has become an important task for developing biomarkers that are sensitive to such deviations. Complementary to structural analysis, diffusion tensor imaging (DTI) has proven effective in identifying age-related microstructural changes within the brain white matter, thereby presenting itself as a promising additional modality for brain age prediction. Although early studies have sought to harness DTI's advantages for age estimation, there is no evidence that the success of this prediction is owed to the unique microstructural and diffusivity features that DTI provides, rather than the macrostructural features that are also available in DTI data. Therefore, we seek to develop white-matter-specific age estimation to capture deviations from normal white matter aging. Specifically, we deliberately disregard the macrostructural information when predicting age from DTI scalar images, using two distinct methods. The first method relies on extracting only microstructural features from regions of interest. The second applies 3D residual neural networks (ResNets) to learn features directly from the images, which are non-linearly registered and warped to a template to minimize macrostructural variations. When tested on unseen data, the first method yields mean absolute error (MAE) of 6.11 years for cognitively normal participants and MAE of 6.62 years for cognitively impaired participants, while the second method achieves MAE of 4.69 years for cognitively normal participants and MAE of 4.96 years for cognitively impaired participants. We find that the ResNet model captures subtler, non-macrostructural features for brain age prediction.