 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised learning of acquisition variability in structural connectomes via hybrid latent space modeling
May 13, 2026Acquisition differences across sites, scanners, and protocols in dMRI introduce variability that complicates structural connectome analysis. This motivates deep learning models that can represent high-dimensional connectomes in a low-dimensional space while explicitly separating acquisition-related effects from biological variation. Conventional dimensionality reduction methods model all variance as continuous, so acquisition effects often get absorbed into a continuous latent space. Recent hybrid latent-space models combine discrete and continuous components to address this, but typically require manual capacity tuning to ensure the discrete component captures the intended variability. We introduce an unsupervised framework that removes this manual tuning by architecturally annealing encoder outputs before decoding, allowing the model to adaptively balance discrete and continuous latent variables during training. To evaluate it, we curated a dataset of N=7,416 structural connectomes derived from dMRI, spanning ages 2 to 102 and 13 studies with 25 unique acquisition-parameter combinations. Of these, 5,900 are cognitively unimpaired, 877 have mild cognitive impairment (MCI), and 639 have Alzheimer's disease (AD). We compare against a standard VAE, PCA with k-means clustering, and hybrid models that anneal only through the loss function. Our architectural annealing produces stronger site learning (ARI=0.53, p<0.05) than these baselines. Results show that a hybrid continuous-discrete latent space, with architectural rather than loss-based annealing, provides a useful unsupervised mechanism for capturing acquisition variability in dMRI: by jointly modeling smooth and categorical structure, the Joint-VAE recovers clusters aligned with scanner and protocol differences.
Harmonizing MR Images Across 100+ Scanners: Multi-site Validation with Traveling Subjects and Real-world Protocols
Apr 21, 2026Reliable harmonization of heterogeneous magnetic resonance~(MR) image datasets, especially those acquired in pragmatic clinical trials, is critical to advance multi-center neuroimaging studies and translational machine learning in healthcare. We present an enhanced and rigorously validated version of the HACA3 harmonization algorithm, which we refer to as HACA3$^+$, incorporating key methodological enhancements: (1)~an improved artifact encoder to better isolate and mitigate image artifacts, (2)~background and foreground-sensitive attention mechanisms to increase harmonization specificity, and (3)~extensive training using data spanning 100+ scanners from 64 independent sites, providing a broader diversity of scanners than other harmonization methods. Our study focuses on four commonly acquired MR image contrasts (T1-weighted, T2-weighted, proton density, \& fluid-attenuated inversion recovery), reflecting realistic clinical protocols. We perform inter-site harmonization experiments using traveling subjects to assess the generalization and robustness of the harmonization model. We compare the results of the publicly available version of HACA3 and our implementation, HACA3$^+$. Downstream relevance is further established through whole brain segmentation and image imputation. Finally, we justify each enhancement through an ablation experiment. Pre-trained weights and code for HACA3$^+$ are made publicly available at https://github.com/shays15/haca3-plus.
Evaluation of neuroCombat and deep learning harmonization for multi-site magnetic resonance neuroimaging in youth with prenatal alcohol exposure
Mar 31, 2026In cases of prevalent diseases and disorders, such as Prenatal Alcohol Exposure (PAE), multi-site data collection allows for increased study samples. However, multi-site studies introduce additional variability through heterogeneous collection materials, such as scanner and acquisition protocols, which confound with biologically relevant signals. Neuroscientists often utilize statistical methods on image-derived metrics, such as volume of regions of interest, after all image processing to minimize site-related variance. HACA3, a deep learning harmonization method, offers an opportunity to harmonize image signals prior to metric quantification; however, HACA3 has not yet been validated in a pediatric cohort. In this work, we investigate HACA3's ability to remove site-related variance and preserve biologically relevant signal compared to a statistical method, neuroCombat, and pair HACA3 processing with neuroCombat to evaluate the efficacy of multiple harmonization methods in a pediatric (age 7 to 21) population across three unique scanners with controls and cases of PAE with downstream MaCRUISE volume metrics. We find that HACA3 qualitatively improves inter-site contrast variations, but statistical methods reduce greater site-related variance within the MaCRUISE volume metrics following an ANCOVA test, and HACA3 relies on follow-up statistical methods to approach maximal biological preservation in this context.
MetaVoxel: Joint Diffusion Modeling of Imaging and Clinical Metadata
Dec 12, 2025Modern deep learning methods have achieved impressive results across tasks from disease classification, estimating continuous biomarkers, to generating realistic medical images. Most of these approaches are trained to model conditional distributions defined by a specific predictive direction with a specific set of input variables. We introduce MetaVoxel, a generative joint diffusion modeling framework that models the joint distribution over imaging data and clinical metadata by learning a single diffusion process spanning all variables. By capturing the joint distribution, MetaVoxel unifies tasks that traditionally require separate conditional models and supports flexible zero-shot inference using arbitrary subsets of inputs without task-specific retraining. Using more than 10,000 T1-weighted MRI scans paired with clinical metadata from nine datasets, we show that a single MetaVoxel model can perform image generation, age estimation, and sex prediction, achieving performance comparable to established task-specific baselines. Additional experiments highlight its capabilities for flexible inference. Together, these findings demonstrate that joint multimodal diffusion offers a promising direction for unifying medical AI models and enabling broader clinical applicability.
Phenotype discovery of traumatic brain injury segmentations from heterogeneous multi-site data
Nov 05, 2025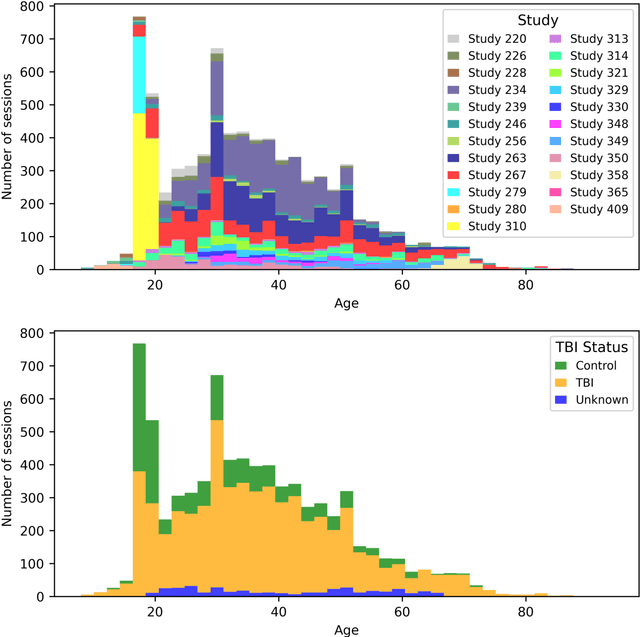
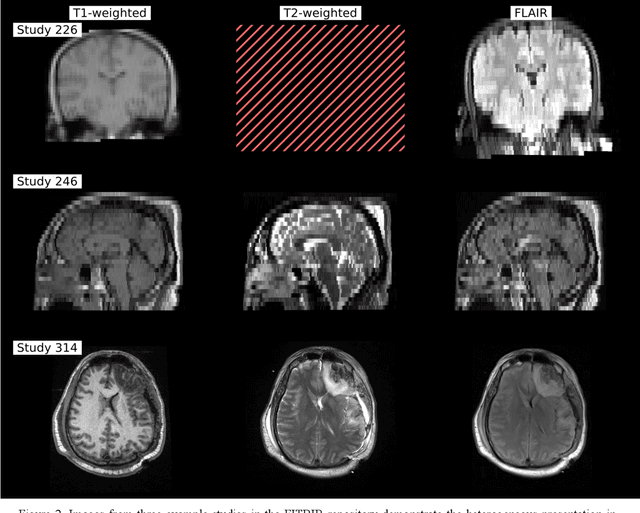
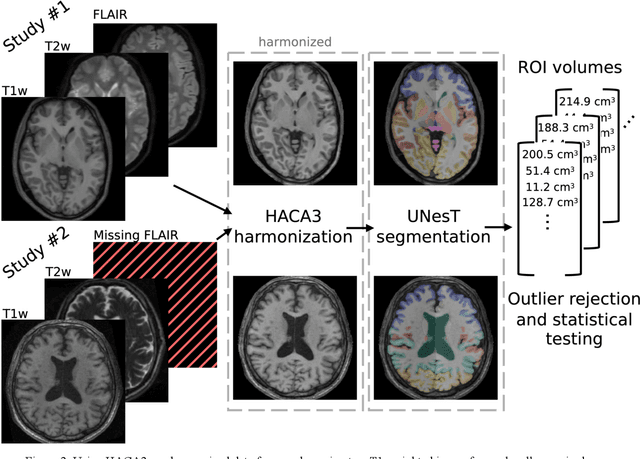
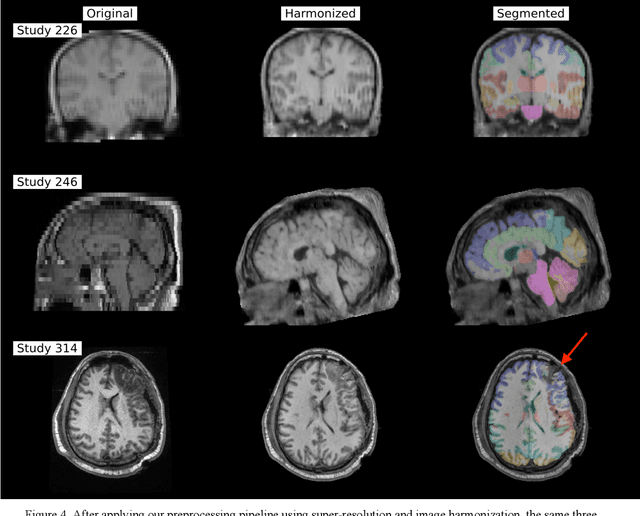
Traumatic brain injury (TBI) is intrinsically heterogeneous, and typical clinical outcome measures like the Glasgow Coma Scale complicate this diversity. The large variability in severity and patient outcomes render it difficult to link structural damage to functional deficits. The Federal Interagency Traumatic Brain Injury Research (FITBIR) repository contains large-scale multi-site magnetic resonance imaging data of varying resolutions and acquisition parameters (25 shared studies with 7,693 sessions that have age, sex and TBI status defined - 5,811 TBI and 1,882 controls). To reveal shared pathways of injury of TBI through imaging, we analyzed T1-weighted images from these sessions by first harmonizing to a local dataset and segmenting 132 regions of interest (ROIs) in the brain. After running quality assurance, calculating the volumes of the ROIs, and removing outliers, we calculated the z-scores of volumes for all participants relative to the mean and standard deviation of the controls. We regressed out sex, age, and total brain volume with a multivariate linear regression, and we found significant differences in 37 ROIs between subjects with TBI and controls (p < 0.05 with independent t-tests with false discovery rate correction). We found that differences originated in 1) the brainstem, occipital pole and structures posterior to the orbit, 2) subcortical gray matter and insular cortex, and 3) cerebral and cerebellar white matter using independent component analysis and clustering the component loadings of those with TBI.
MSRepaint: Multiple Sclerosis Repaint with Conditional Denoising Diffusion Implicit Model for Bidirectional Lesion Filling and Synthesis
Oct 02, 2025In multiple sclerosis, lesions interfere with automated magnetic resonance imaging analyses such as brain parcellation and deformable registration, while lesion segmentation models are hindered by the limited availability of annotated training data. To address both issues, we propose MSRepaint, a unified diffusion-based generative model for bidirectional lesion filling and synthesis that restores anatomical continuity for downstream analyses and augments segmentation through realistic data generation. MSRepaint conditions on spatial lesion masks for voxel-level control, incorporates contrast dropout to handle missing inputs, integrates a repainting mechanism to preserve surrounding anatomy during lesion filling and synthesis, and employs a multi-view DDIM inversion and fusion pipeline for 3D consistency with fast inference. Extensive evaluations demonstrate the effectiveness of MSRepaint across multiple tasks. For lesion filling, we evaluate both the accuracy within the filled regions and the impact on downstream tasks including brain parcellation and deformable registration. MSRepaint outperforms the traditional lesion filling methods FSL and NiftySeg, and achieves accuracy on par with FastSurfer-LIT, a recent diffusion model-based inpainting method, while offering over 20 times faster inference. For lesion synthesis, state-of-the-art MS lesion segmentation models trained on MSRepaint-synthesized data outperform those trained on CarveMix-synthesized data or real ISBI challenge training data across multiple benchmarks, including the MICCAI 2016 and UMCL datasets. Additionally, we demonstrate that MSRepaint's unified bidirectional filling and synthesis capability, with full spatial control over lesion appearance, enables high-fidelity simulation of lesion evolution in longitudinal MS progression.
Self-supervised learning of imaging and clinical signatures using a multimodal joint-embedding predictive architecture
Sep 18, 2025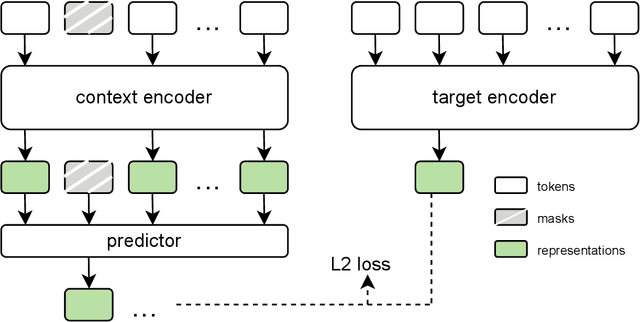

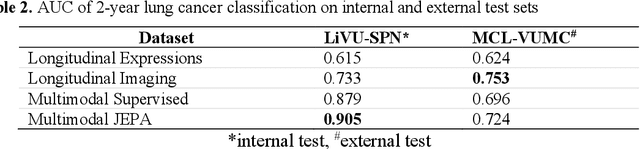
The development of multimodal models for pulmonary nodule diagnosis is limited by the scarcity of labeled data and the tendency for these models to overfit on the training distribution. In this work, we leverage self-supervised learning from longitudinal and multimodal archives to address these challenges. We curate an unlabeled set of patients with CT scans and linked electronic health records from our home institution to power joint embedding predictive architecture (JEPA) pretraining. After supervised finetuning, we show that our approach outperforms an unregularized multimodal model and imaging-only model in an internal cohort (ours: 0.91, multimodal: 0.88, imaging-only: 0.73 AUC), but underperforms in an external cohort (ours: 0.72, imaging-only: 0.75 AUC). We develop a synthetic environment that characterizes the context in which JEPA may underperform. This work innovates an approach that leverages unlabeled multimodal medical archives to improve predictive models and demonstrates its advantages and limitations in pulmonary nodule diagnosis.
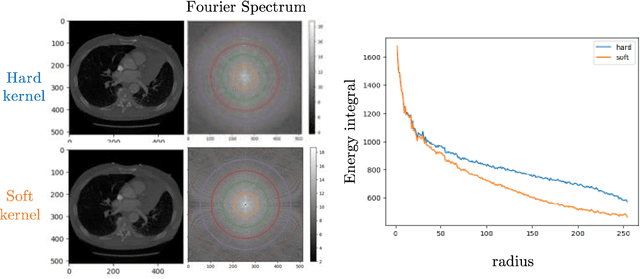
UNISELF: A Unified Network with Instance Normalization and Self-Ensembled Lesion Fusion for Multiple Sclerosis Lesion Segmentation
Aug 06, 2025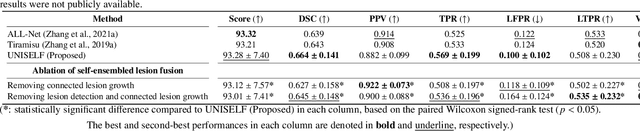
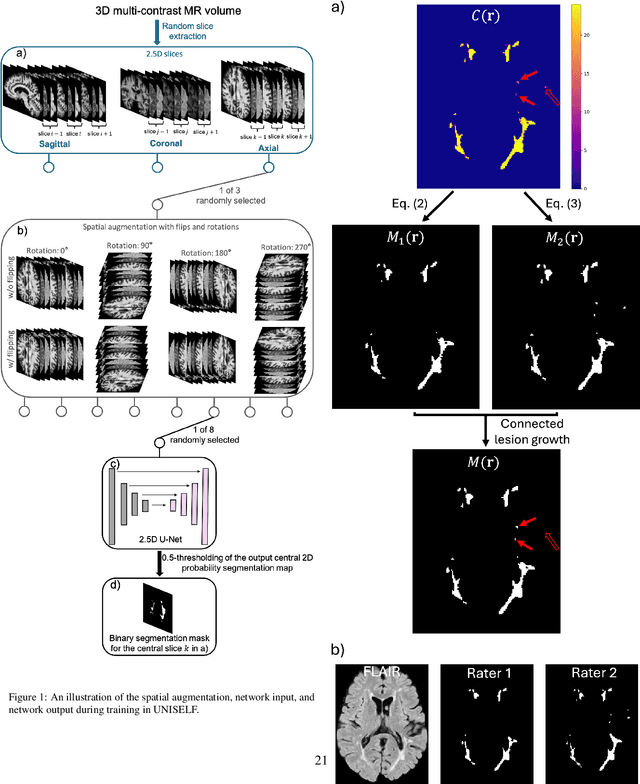
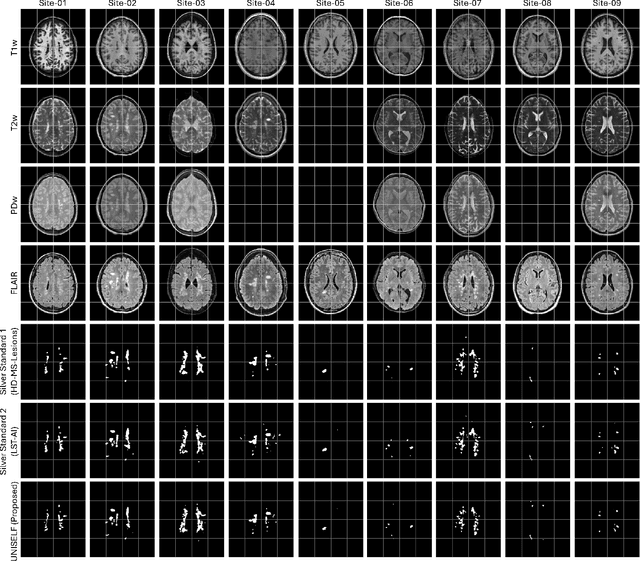

Automated segmentation of multiple sclerosis (MS) lesions using multicontrast magnetic resonance (MR) images improves efficiency and reproducibility compared to manual delineation, with deep learning (DL) methods achieving state-of-the-art performance. However, these DL-based methods have yet to simultaneously optimize in-domain accuracy and out-of-domain generalization when trained on a single source with limited data, or their performance has been unsatisfactory. To fill this gap, we propose a method called UNISELF, which achieves high accuracy within a single training domain while demonstrating strong generalizability across multiple out-of-domain test datasets. UNISELF employs a novel test-time self-ensembled lesion fusion to improve segmentation accuracy, and leverages test-time instance normalization (TTIN) of latent features to address domain shifts and missing input contrasts. Trained on the ISBI 2015 longitudinal MS segmentation challenge training dataset, UNISELF ranks among the best-performing methods on the challenge test dataset. Additionally, UNISELF outperforms all benchmark methods trained on the same ISBI training data across diverse out-of-domain test datasets with domain shifts and missing contrasts, including the public MICCAI 2016 and UMCL datasets, as well as a private multisite dataset. These test datasets exhibit domain shifts and/or missing contrasts caused by variations in acquisition protocols, scanner types, and imaging artifacts arising from imperfect acquisition. Our code is available at https://github.com/uponacceptance.
Synthetic multi-inversion time magnetic resonance images for visualization of subcortical structures
Jun 04, 2025Purpose: Visualization of subcortical gray matter is essential in neuroscience and clinical practice, particularly for disease understanding and surgical planning.While multi-inversion time (multi-TI) T$_1$-weighted (T$_1$-w) magnetic resonance (MR) imaging improves visualization, it is rarely acquired in clinical settings. Approach: We present SyMTIC (Synthetic Multi-TI Contrasts), a deep learning method that generates synthetic multi-TI images using routinely acquired T$_1$-w, T$_2$-weighted (T$_2$-w), and FLAIR images. Our approach combines image translation via deep neural networks with imaging physics to estimate longitudinal relaxation time (T$_1$) and proton density (PD) maps. These maps are then used to compute multi-TI images with arbitrary inversion times. Results: SyMTIC was trained using paired MPRAGE and FGATIR images along with T$_2$-w and FLAIR images. It accurately synthesized multi-TI images from standard clinical inputs, achieving image quality comparable to that from explicitly acquired multi-TI data.The synthetic images, especially for TI values between 400-800 ms, enhanced visualization of subcortical structures and improved segmentation of thalamic nuclei. Conclusion: SyMTIC enables robust generation of high-quality multi-TI images from routine MR contrasts. It generalizes well to varied clinical datasets, including those with missing FLAIR images or unknown parameters, offering a practical solution for improving brain MR image visualization and analysis.
Beyond the LUMIR challenge: The pathway to foundational registration models
May 30, 2025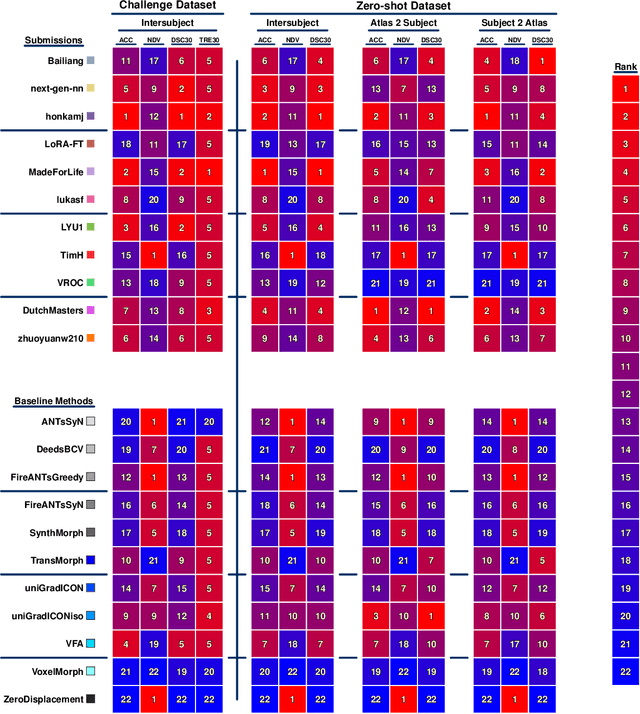
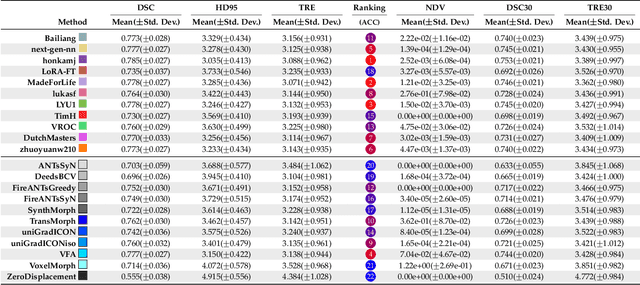

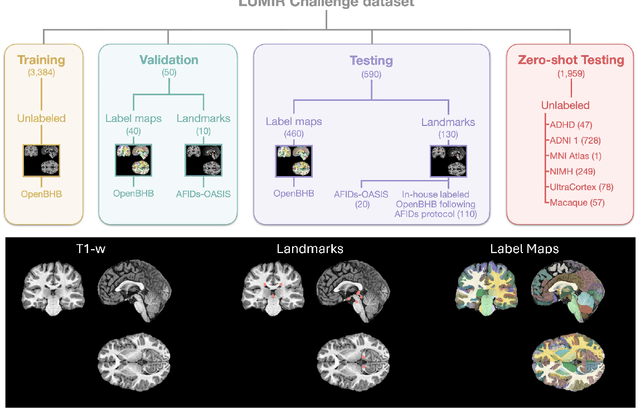
Medical image challenges have played a transformative role in advancing the field, catalyzing algorithmic innovation and establishing new performance standards across diverse clinical applications. Image registration, a foundational task in neuroimaging pipelines, has similarly benefited from the Learn2Reg initiative. Building on this foundation, we introduce the Large-scale Unsupervised Brain MRI Image Registration (LUMIR) challenge, a next-generation benchmark designed to assess and advance unsupervised brain MRI registration. Distinct from prior challenges that leveraged anatomical label maps for supervision, LUMIR removes this dependency by providing over 4,000 preprocessed T1-weighted brain MRIs for training without any label maps, encouraging biologically plausible deformation modeling through self-supervision. In addition to evaluating performance on 590 held-out test subjects, LUMIR introduces a rigorous suite of zero-shot generalization tasks, spanning out-of-domain imaging modalities (e.g., FLAIR, T2-weighted, T2*-weighted), disease populations (e.g., Alzheimer's disease), acquisition protocols (e.g., 9.4T MRI), and species (e.g., macaque brains). A total of 1,158 subjects and over 4,000 image pairs were included for evaluation. Performance was assessed using both segmentation-based metrics (Dice coefficient, 95th percentile Hausdorff distance) and landmark-based registration accuracy (target registration error). Across both in-domain and zero-shot tasks, deep learning-based methods consistently achieved state-of-the-art accuracy while producing anatomically plausible deformation fields. The top-performing deep learning-based models demonstrated diffeomorphic properties and inverse consistency, outperforming several leading optimization-based methods, and showing strong robustness to most domain shifts, the exception being a drop in performance on out-of-domain contrasts.