 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSRepaint: Multiple Sclerosis Repaint with Conditional Denoising Diffusion Implicit Model for Bidirectional Lesion Filling and Synthesis
Oct 02, 2025In multiple sclerosis, lesions interfere with automated magnetic resonance imaging analyses such as brain parcellation and deformable registration, while lesion segmentation models are hindered by the limited availability of annotated training data. To address both issues, we propose MSRepaint, a unified diffusion-based generative model for bidirectional lesion filling and synthesis that restores anatomical continuity for downstream analyses and augments segmentation through realistic data generation. MSRepaint conditions on spatial lesion masks for voxel-level control, incorporates contrast dropout to handle missing inputs, integrates a repainting mechanism to preserve surrounding anatomy during lesion filling and synthesis, and employs a multi-view DDIM inversion and fusion pipeline for 3D consistency with fast inference. Extensive evaluations demonstrate the effectiveness of MSRepaint across multiple tasks. For lesion filling, we evaluate both the accuracy within the filled regions and the impact on downstream tasks including brain parcellation and deformable registration. MSRepaint outperforms the traditional lesion filling methods FSL and NiftySeg, and achieves accuracy on par with FastSurfer-LIT, a recent diffusion model-based inpainting method, while offering over 20 times faster inference. For lesion synthesis, state-of-the-art MS lesion segmentation models trained on MSRepaint-synthesized data outperform those trained on CarveMix-synthesized data or real ISBI challenge training data across multiple benchmarks, including the MICCAI 2016 and UMCL datasets. Additionally, we demonstrate that MSRepaint's unified bidirectional filling and synthesis capability, with full spatial control over lesion appearance, enables high-fidelity simulation of lesion evolution in longitudinal MS progression.
UNISELF: A Unified Network with Instance Normalization and Self-Ensembled Lesion Fusion for Multiple Sclerosis Lesion Segmentation
Aug 06, 2025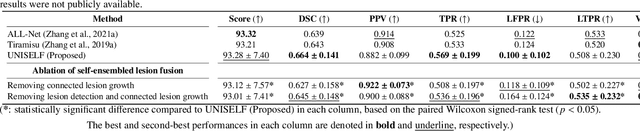
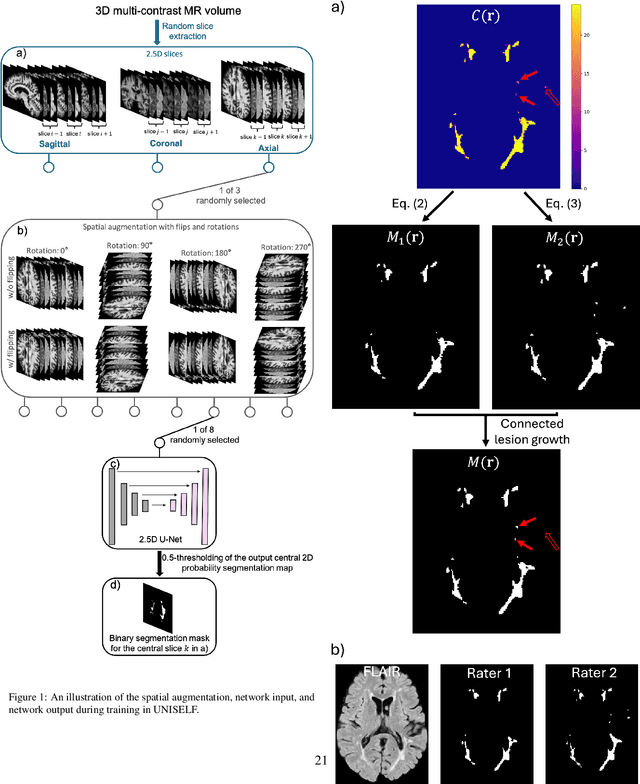
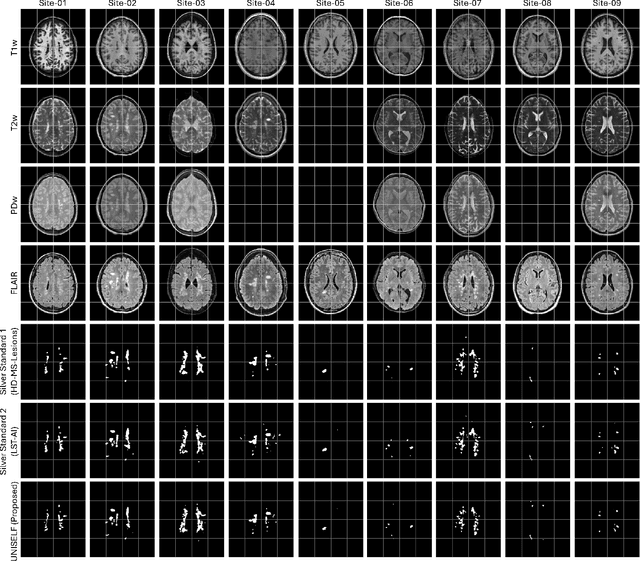

Automated segmentation of multiple sclerosis (MS) lesions using multicontrast magnetic resonance (MR) images improves efficiency and reproducibility compared to manual delineation, with deep learning (DL) methods achieving state-of-the-art performance. However, these DL-based methods have yet to simultaneously optimize in-domain accuracy and out-of-domain generalization when trained on a single source with limited data, or their performance has been unsatisfactory. To fill this gap, we propose a method called UNISELF, which achieves high accuracy within a single training domain while demonstrating strong generalizability across multiple out-of-domain test datasets. UNISELF employs a novel test-time self-ensembled lesion fusion to improve segmentation accuracy, and leverages test-time instance normalization (TTIN) of latent features to address domain shifts and missing input contrasts. Trained on the ISBI 2015 longitudinal MS segmentation challenge training dataset, UNISELF ranks among the best-performing methods on the challenge test dataset. Additionally, UNISELF outperforms all benchmark methods trained on the same ISBI training data across diverse out-of-domain test datasets with domain shifts and missing contrasts, including the public MICCAI 2016 and UMCL datasets, as well as a private multisite dataset. These test datasets exhibit domain shifts and/or missing contrasts caused by variations in acquisition protocols, scanner types, and imaging artifacts arising from imperfect acquisition. Our code is available at https://github.com/uponacceptance.
Beyond MR Image Harmonization: Resolution Matters Too
Aug 30, 2024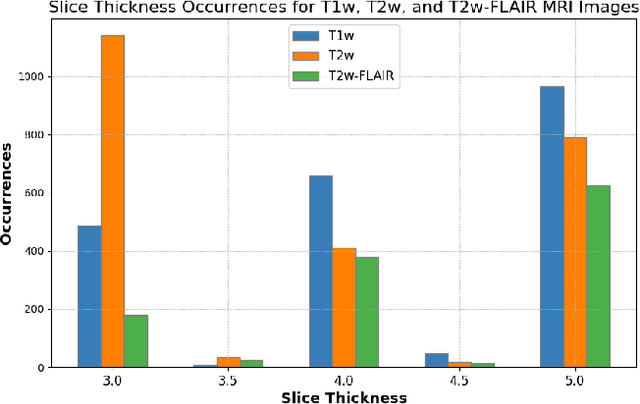
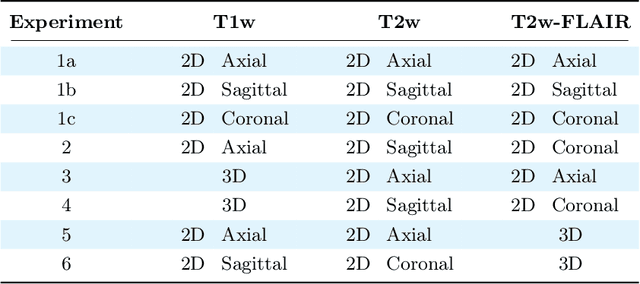
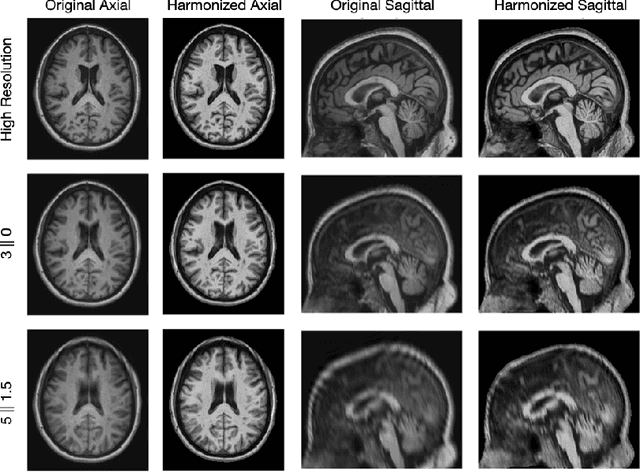
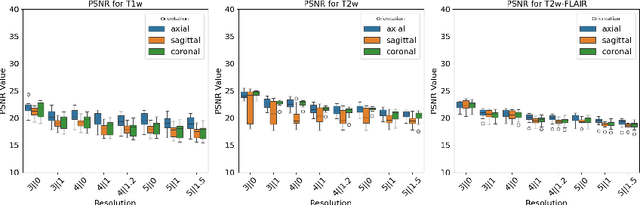
Magnetic resonance (MR) imaging is commonly used in the clinical setting to non-invasively monitor the body. There exists a large variability in MR imaging due to differences in scanner hardware, software, and protocol design. Ideally, a processing algorithm should perform robustly to this variability, but that is not always the case in reality. This introduces a need for image harmonization to overcome issues of domain shift when performing downstream analysis such as segmentation. Most image harmonization models focus on acquisition parameters such as inversion time or repetition time, but they ignore an important aspect in MR imaging -- resolution. In this paper, we evaluate the impact of image resolution on harmonization using a pretrained harmonization algorithm. We simulate 2D acquisitions of various slice thicknesses and gaps from 3D acquired, 1mm3 isotropic MR images and demonstrate how the performance of a state-of-the-art image harmonization algorithm varies as resolution changes. We discuss the most ideal scenarios for image resolution including acquisition orientation when 3D imaging is not available, which is common for many clinical scanners. Our results show that harmonization on low-resolution images does not account for acquisition resolution and orientation variations. Super-resolution can be used to alleviate resolution variations but it is not always used. Our methodology can generalize to help evaluate the impact of image acquisition resolution for multiple tasks. Determining the limits of a pretrained algorithm is important when considering preprocessing steps and trust in the results.
Rapid Brain Meninges Surface Reconstruction with Layer Topology Guarantee
Apr 13, 2023



The meninges, located between the skull and brain, are composed of three membrane layers: the pia, the arachnoid, and the dura. Reconstruction of these layers can aid in studying volume differences between patients with neurodegenerative diseases and normal aging subjects. In this work, we use convolutional neural networks (CNNs) to reconstruct surfaces representing meningeal layer boundaries from magnetic resonance (MR) images. We first use the CNNs to predict the signed distance functions (SDFs) representing these surfaces while preserving their anatomical ordering. The marching cubes algorithm is then used to generate continuous surface representations; both the subarachnoid space (SAS) and the intracranial volume (ICV) are computed from these surfaces. The proposed method is compared to a state-of-the-art deformable model-based reconstruction method, and we show that our method can reconstruct smoother and more accurate surfaces using less computation time. Finally, we conduct experiments with volumetric analysis on both subjects with multiple sclerosis and healthy controls. For healthy and MS subjects, ICVs and SAS volumes are found to be significantly correlated to sex (p<0.01) and age (p<0.03) changes, respectively.
HACA3: A Unified Approach for Multi-site MR Image Harmonization
Dec 12, 2022



The lack of standardization is a prominent issue in magnetic resonance (MR) imaging. This often causes undesired contrast variations due to differences in hardware and acquisition parameters. In recent years, MR harmonization using image synthesis with disentanglement has been proposed to compensate for the undesired contrast variations. Despite the success of existing methods, we argue that three major improvements can be made. First, most existing methods are built upon the assumption that multi-contrast MR images of the same subject share the same anatomy. This assumption is questionable since different MR contrasts are specialized to highlight different anatomical features. Second, these methods often require a fixed set of MR contrasts for training (e.g., both Tw-weighted and T2-weighted images must be available), which limits their applicability. Third, existing methods generally are sensitive to imaging artifacts. In this paper, we present a novel approach, Harmonization with Attention-based Contrast, Anatomy, and Artifact Awareness (HACA3), to address these three issues. We first propose an anatomy fusion module that enables HACA3 to respect the anatomical differences between MR contrasts. HACA3 is also robust to imaging artifacts and can be trained and applied to any set of MR contrasts. Experiments show that HACA3 achieves state-of-the-art performance under multiple image quality metrics. We also demonstrate the applicability of HACA3 on downstream tasks with diverse MR datasets acquired from 21 sites with different field strengths, scanner platforms, and acquisition protocols.
Information-based Disentangled Representation Learning for Unsupervised MR Harmonization
Mar 24, 2021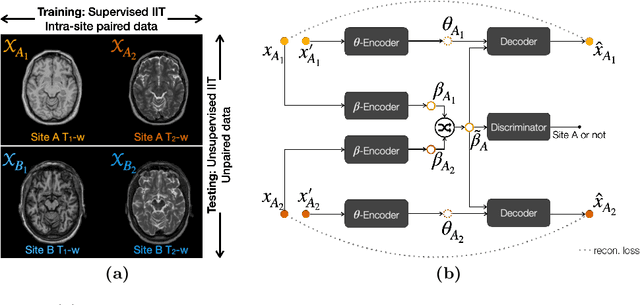
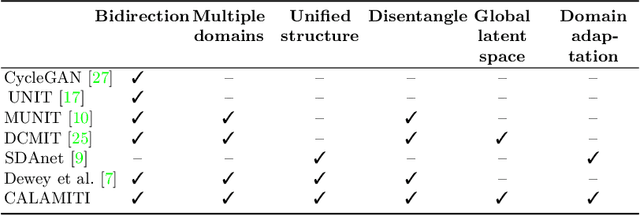
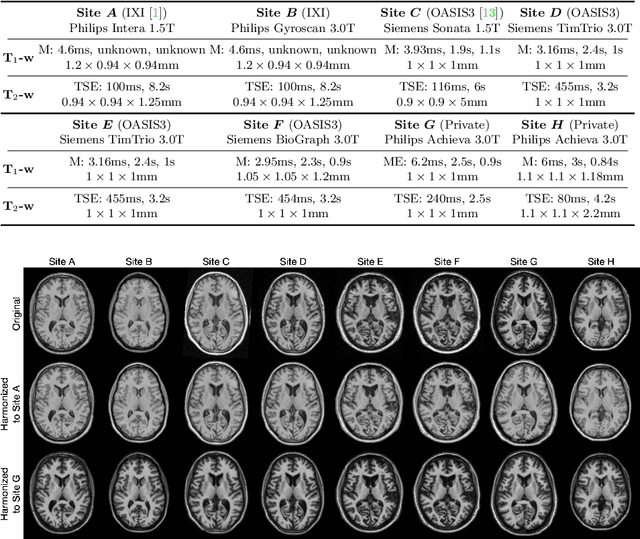
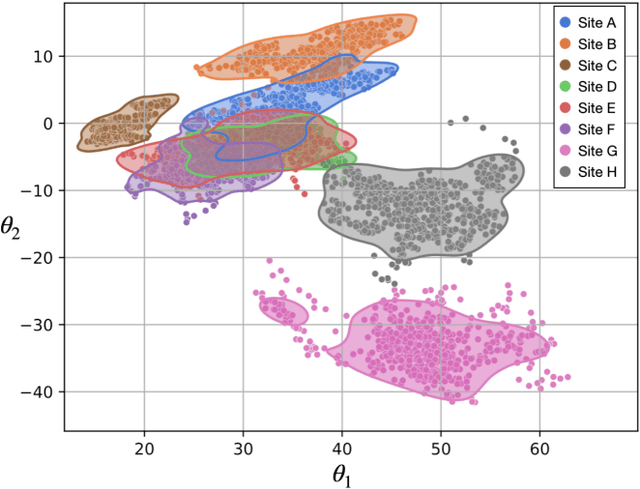
Accuracy and consistency are two key factors in computer-assisted magnetic resonance (MR) image analysis. However, contrast variation from site to site caused by lack of standardization in MR acquisition impedes consistent measurements. In recent years, image harmonization approaches have been proposed to compensate for contrast variation in MR images. Current harmonization approaches either require cross-site traveling subjects for supervised training or heavily rely on site-specific harmonization models to encourage harmonization accuracy. These requirements potentially limit the application of current harmonization methods in large-scale multi-site studies. In this work, we propose an unsupervised MR harmonization framework, CALAMITI (Contrast Anatomy Learning and Analysis for MR Intensity Translation and Integration), based on information bottleneck theory. CALAMITI learns a disentangled latent space using a unified structure for multi-site harmonization without the need for traveling subjects. Our model is also able to adapt itself to harmonize MR images from a new site with fine tuning solely on images from the new site. Both qualitative and quantitative results show that the proposed method achieves superior performance compared with other unsupervised harmonization approaches.
Multiple Sclerosis Lesion Segmentation from Brain MRI via Fully Convolutional Neural Networks
Mar 24, 2018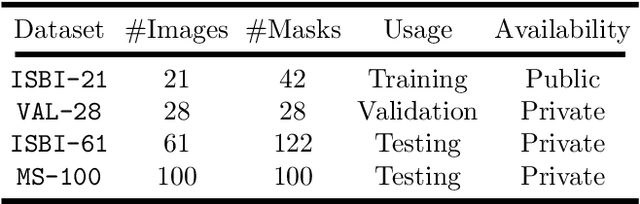
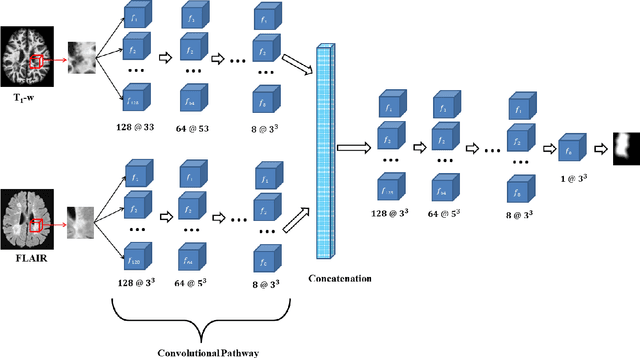
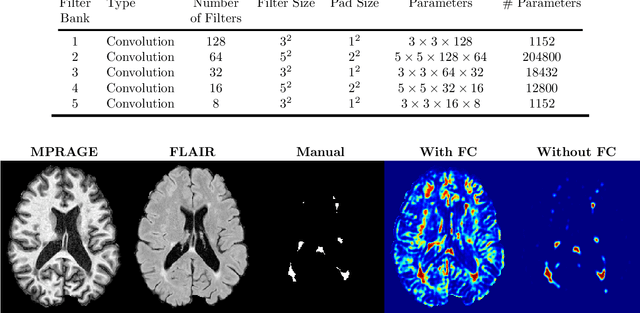
Multiple Sclerosis (MS) is an autoimmune disease that leads to lesions in the central nervous system. Magnetic resonance (MR) images provide sufficient imaging contrast to visualize and detect lesions, particularly those in the white matter. Quantitative measures based on various features of lesions have been shown to be useful in clinical trials for evaluating therapies. Therefore robust and accurate segmentation of white matter lesions from MR images can provide important information about the disease status and progression. In this paper, we propose a fully convolutional neural network (CNN) based method to segment white matter lesions from multi-contrast MR images. The proposed CNN based method contains two convolutional pathways. The first pathway consists of multiple parallel convolutional filter banks catering to multiple MR modalities. In the second pathway, the outputs of the first one are concatenated and another set of convolutional filters are applied. The output of this last pathway produces a membership function for lesions that may be thresholded to obtain a binary segmentation. The proposed method is evaluated on a dataset of 100 MS patients, as well as the ISBI 2015 challenge data consisting of 14 patients. The comparison is performed against four publicly available MS lesion segmentation methods. Significant improvement in segmentation quality over the competing methods is demonstrated on various metrics, such as Dice and false positive ratio. While evaluating on the ISBI 2015 challenge data, our method produces a score of 90.48, where a score of 90 is considered to be comparable to a human rater.
Topology guaranteed segmentation of the human retina from OCT using convolutional neural networks
Mar 14, 2018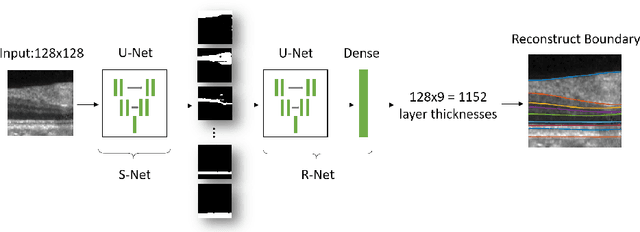
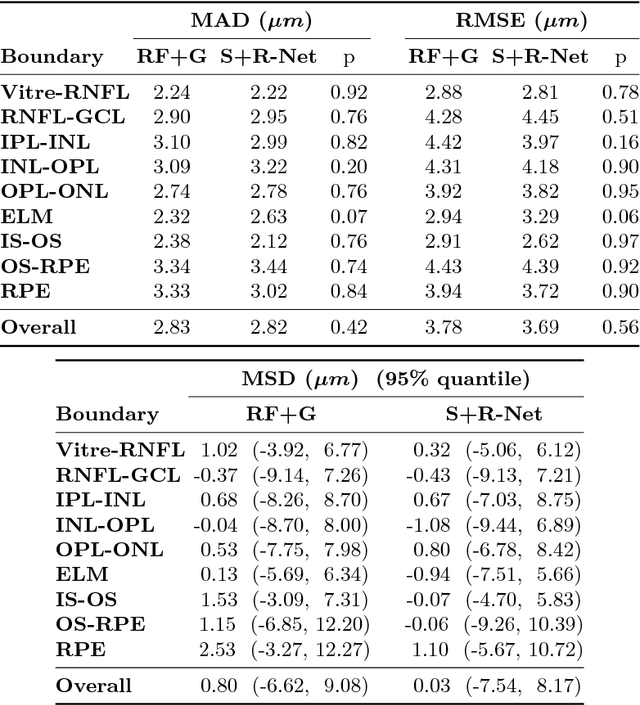
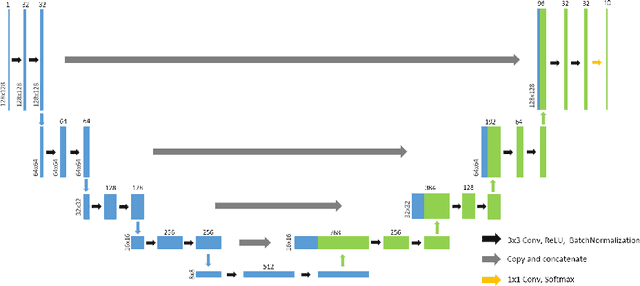
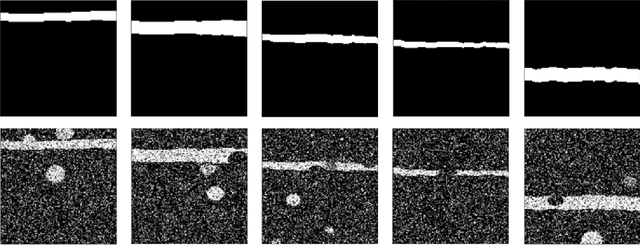
Optical coherence tomography (OCT) is a noninvasive imaging modality which can be used to obtain depth images of the retina. The changing layer thicknesses can thus be quantified by analyzing these OCT images, moreover these changes have been shown to correlate with disease progression in multiple sclerosis. Recent automated retinal layer segmentation tools use machine learning methods to perform pixel-wise labeling and graph methods to guarantee the layer hierarchy or topology. However, graph parameters like distance and smoothness constraints must be experimentally assigned by retinal region and pathology, thus degrading the flexibility and time efficiency of the whole framework. In this paper, we develop cascaded deep networks to provide a topologically correct segmentation of the retinal layers in a single feed forward propagation. The first network (S-Net) performs pixel-wise labeling and the second regression network (R-Net) takes the topologically unconstrained S-Net results and outputs layer thicknesses for each layer and each position. Relu activation is used as the final operation of the R-Net which guarantees non-negativity of the output layer thickness. Since the segmentation boundary position is acquired by summing up the corresponding non-negative layer thicknesses, the layer ordering (i.e., topology) of the reconstructed boundaries is guaranteed even at the fovea where the distances between boundaries can be zero. The R-Net is trained using simulated masks and thus can be generalized to provide topology guaranteed segmentation for other layered structures. This deep network has achieved comparable mean absolute boundary error (2.82 {\mu}m) to state-of-the-art graph methods (2.83 {\mu}m).