 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrast Adaptive Tissue Classification by Alternating Segmentation and Synthesis
Mar 04, 2021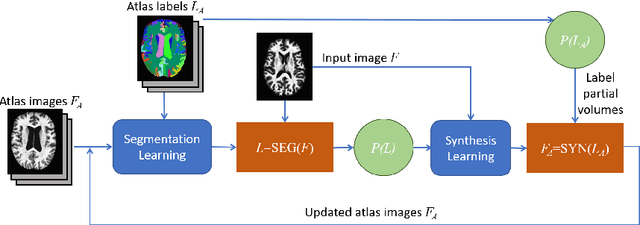
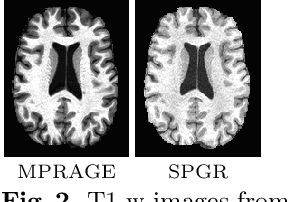
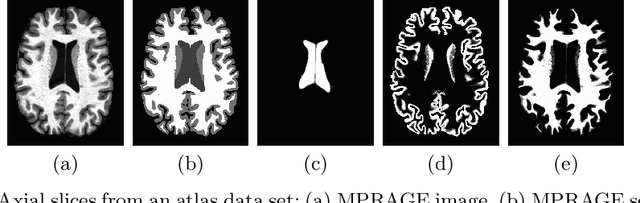
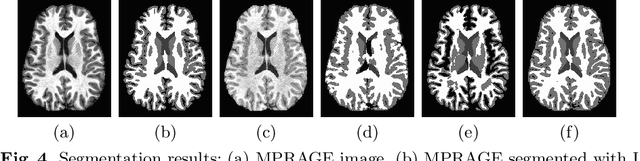
Deep learning approaches to the segmentation of magnetic resonance images have shown significant promise in automating the quantitative analysis of brain images. However, a continuing challenge has been its sensitivity to the variability of acquisition protocols. Attempting to segment images that have different contrast properties from those within the training data generally leads to significantly reduced performance. Furthermore, heterogeneous data sets cannot be easily evaluated because the quantitative variation due to acquisition differences often dwarfs the variation due to the biological differences that one seeks to measure. In this work, we describe an approach using alternating segmentation and synthesis steps that adapts the contrast properties of the training data to the input image. This allows input images that do not resemble the training data to be more consistently segmented. A notable advantage of this approach is that only a single example of the acquisition protocol is required to adapt to its contrast properties. We demonstrate the efficacy of our approaching using brain images from a set of human subjects scanned with two different T1-weighted volumetric protocols.
Extracting 2D weak labels from volume labels using multiple instance learning in CT hemorrhage detection
Nov 13, 2019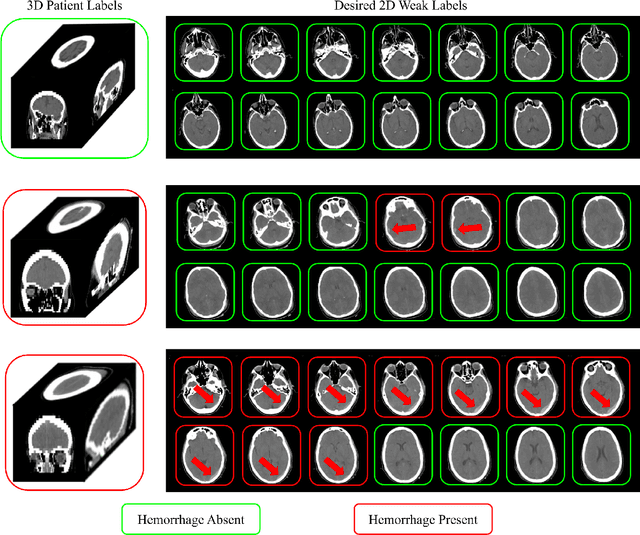

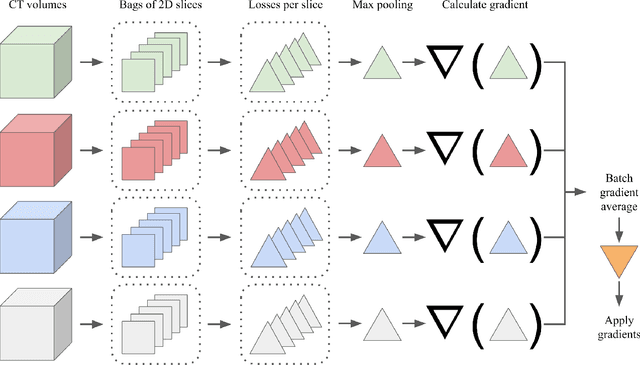
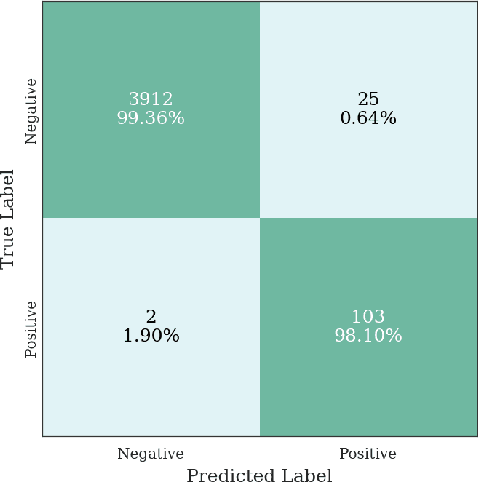
Multiple instance learning (MIL) is a supervised learning methodology that aims to allow models to learn instance class labels from bag class labels, where a bag is defined to contain multiple instances. MIL is gaining traction for learning from weak labels but has not been widely applied to 3D medical imaging. MIL is well-suited to clinical CT acquisitions since (1) the highly anisotropic voxels hinder application of traditional 3D networks and (2) patch-based networks have limited ability to learn whole volume labels. In this work, we apply MIL with a deep convolutional neural network to identify whether clinical CT head image volumes possess one or more large hemorrhages (> 20cm$^3$), resulting in a learned 2D model without the need for 2D slice annotations. Individual image volumes are considered separate bags, and the slices in each volume are instances. Such a framework sets the stage for incorporating information obtained in clinical reports to help train a 2D segmentation approach. Within this context, we evaluate the data requirements to enable generalization of MIL by varying the amount of training data. Our results show that a training size of at least 400 patient image volumes was needed to achieve accurate per-slice hemorrhage detection. Over a five-fold cross-validation, the leading model, which made use of the maximum number of training volumes, had an average true positive rate of 98.10%, an average true negative rate of 99.36%, and an average precision of 0.9698. The models have been made available along with source code to enabled continued exploration and adaption of MIL in CT neuroimaging.
Distributed deep learning for robust multi-site segmentation of CT imaging after traumatic brain injury
Mar 11, 2019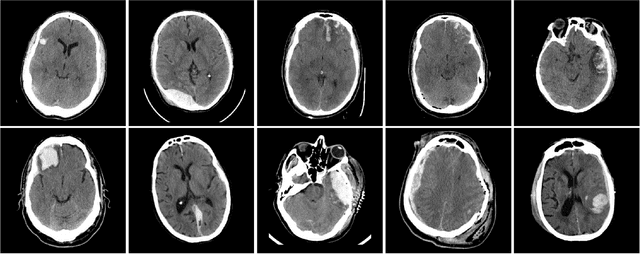

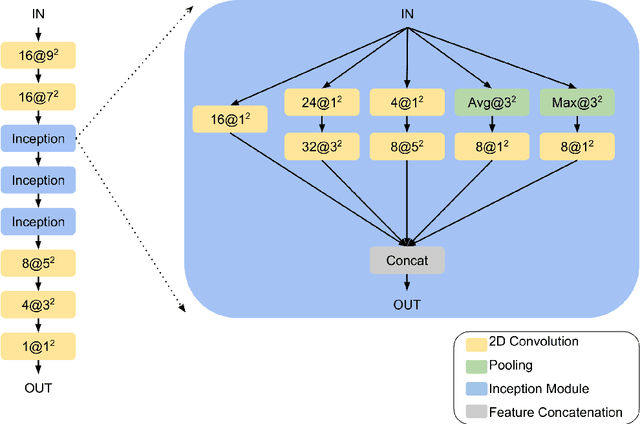

Machine learning models are becoming commonplace in the domain of medical imaging, and with these methods comes an ever-increasing need for more data. However, to preserve patient anonymity it is frequently impractical or prohibited to transfer protected health information (PHI) between institutions. Additionally, due to the nature of some studies, there may not be a large public dataset available on which to train models. To address this conundrum, we analyze the efficacy of transferring the model itself in lieu of data between different sites. By doing so we accomplish two goals: 1) the model gains access to training on a larger dataset that it could not normally obtain and 2) the model better generalizes, having trained on data from separate locations. In this paper, we implement multi-site learning with disparate datasets from the National Institutes of Health (NIH) and Vanderbilt University Medical Center (VUMC) without compromising PHI. Three neural networks are trained to convergence on a computed tomography (CT) brain hematoma segmentation task: one only with NIH data,one only with VUMC data, and one multi-site model alternating between NIH and VUMC data. Resultant lesion masks with the multi-site model attain an average Dice similarity coefficient of 0.64 and the automatically segmented hematoma volumes correlate to those done manually with a Pearson correlation coefficient of 0.87,corresponding to an 8% and 5% improvement, respectively, over the single-site model counterparts.
Synthesizing CT from Ultrashort Echo-Time MR Images via Convolutional Neural Networks
Jul 27, 2018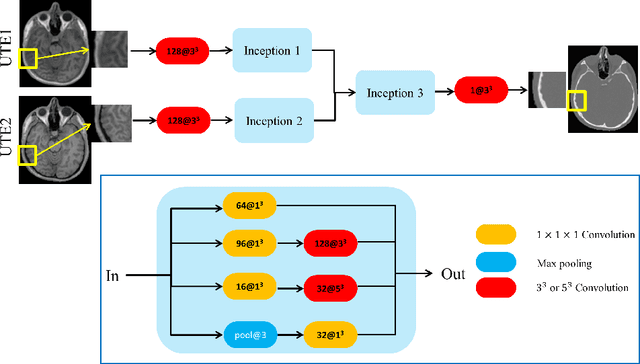
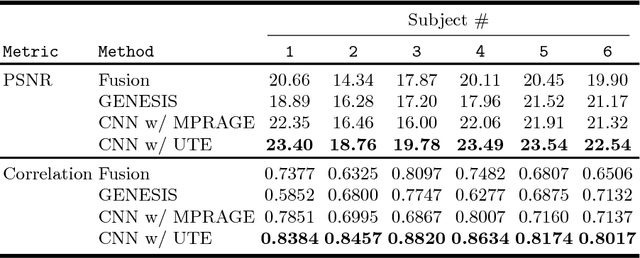
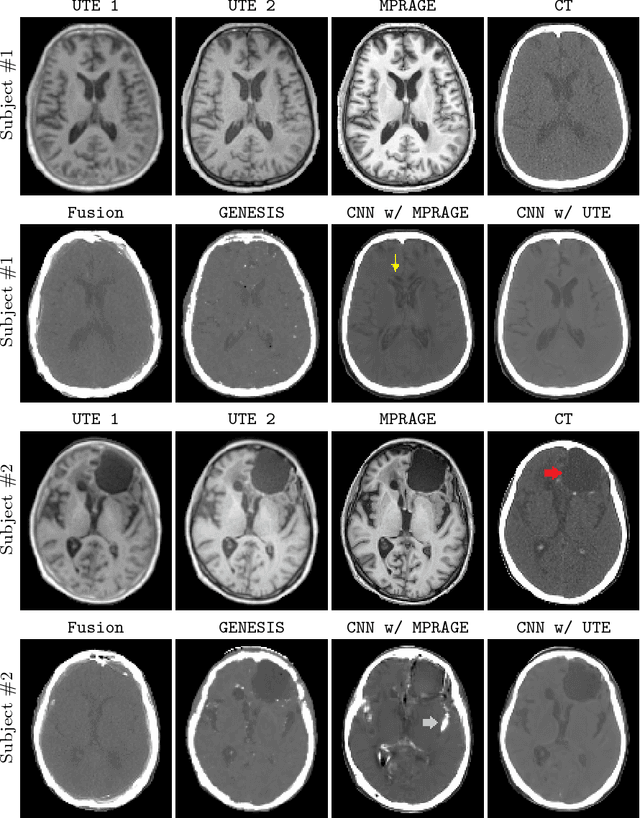
With the increasing popularity of PET-MR scanners in clinical applications, synthesis of CT images from MR has been an important research topic. Accurate PET image reconstruction requires attenuation correction, which is based on the electron density of tissues and can be obtained from CT images. While CT measures electron density information for x-ray photons, MR images convey information about the magnetic properties of tissues. Therefore, with the advent of PET-MR systems, the attenuation coefficients need to be indirectly estimated from MR images. In this paper, we propose a fully convolutional neural network (CNN) based method to synthesize head CT from ultra-short echo-time (UTE) dual-echo MR images. Unlike traditional $T_1$-w images which do not have any bone signal, UTE images show some signal for bone, which makes it a good candidate for MR to CT synthesis. A notable advantage of our approach is that accurate results were achieved with a small training data set. Using an atlas of a single CT and dual-echo UTE pair, we train a deep neural network model to learn the transform of MR intensities to CT using patches. We compared our CNN based model with a state-of-the-art registration based as well as a Bayesian model based CT synthesis method, and showed that the proposed CNN model outperforms both of them. We also compared the proposed model when only $T_1$-w images are available instead of UTE, and show that UTE images produce better synthesis than using just $T_1$-w images.
TBI Contusion Segmentation from MRI using Convolutional Neural Networks
Jul 27, 2018
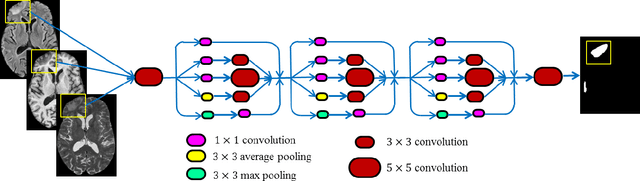
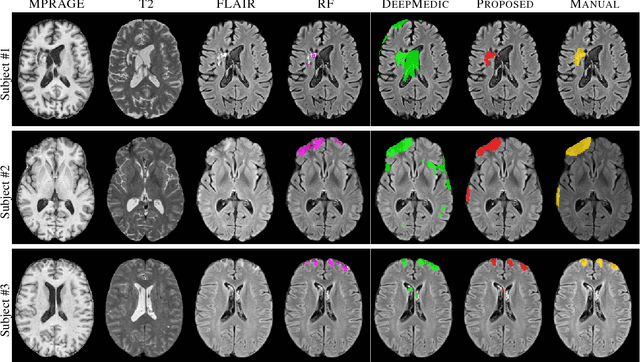
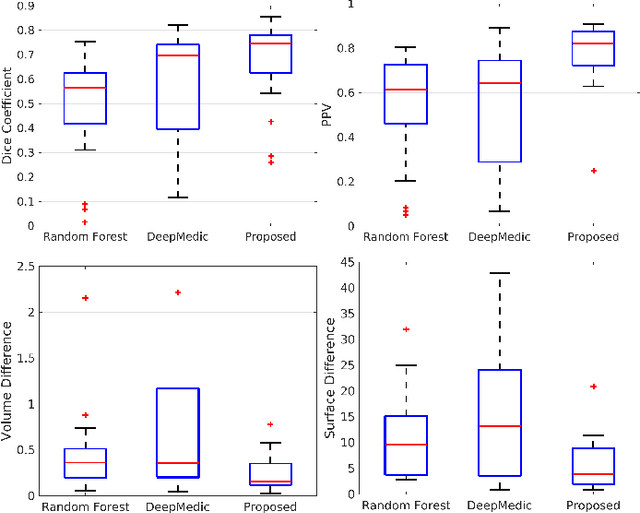
Traumatic brain injury (TBI) is caused by a sudden trauma to the head that may result in hematomas and contusions and can lead to stroke or chronic disability. An accurate quantification of the lesion volumes and their locations is essential to understand the pathophysiology of TBI and its progression. In this paper, we propose a fully convolutional neural network (CNN) model to segment contusions and lesions from brain magnetic resonance (MR) images of patients with TBI. The CNN architecture proposed here was based on a state of the art CNN architecture from Google, called Inception. Using a 3-layer Inception network, lesions are segmented from multi-contrast MR images. When compared with two recent TBI lesion segmentation methods, one based on CNN (called DeepMedic) and another based on random forests, the proposed algorithm showed improved segmentation accuracy on images of 18 patients with mild to severe TBI. Using a leave-one-out cross validation, the proposed model achieved a median Dice of 0.75, which was significantly better (p<0.01) than the two competing methods.
Classifying magnetic resonance image modalities with convolutional neural networks
Apr 17, 2018Magnetic Resonance (MR) imaging allows the acquisition of images with different contrast properties depending on the acquisition protocol and the magnetic properties of tissues. Many MR brain image processing techniques, such as tissue segmentation, require multiple MR contrasts as inputs, and each contrast is treated differently. Thus it is advantageous to automate the identification of image contrasts for various purposes, such as facilitating image processing pipelines, and managing and maintaining large databases via content-based image retrieval (CBIR). Most automated CBIR techniques focus on a two-step process: extracting features from data and classifying the image based on these features. We present a novel 3D deep convolutional neural network (CNN)-based method for MR image contrast classification. The proposed CNN automatically identifies the MR contrast of an input brain image volume. Specifically, we explored three classification problems: (1) identify T1-weighted (T1-w), T2-weighted (T2-w), and fluid-attenuated inversion recovery (FLAIR) contrasts, (2) identify pre vs post-contrast T1, (3) identify pre vs post-contrast FLAIR. A total of 3418 image volumes acquired from multiple sites and multiple scanners were used. To evaluate each task, the proposed model was trained on 2137 images and tested on the remaining 1281 images. Results showed that image volumes were correctly classified with 97.57% accuracy.
Multiple Sclerosis Lesion Segmentation from Brain MRI via Fully Convolutional Neural Networks
Mar 24, 2018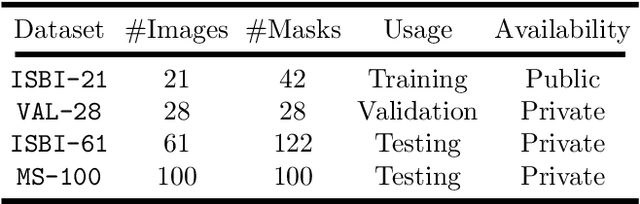
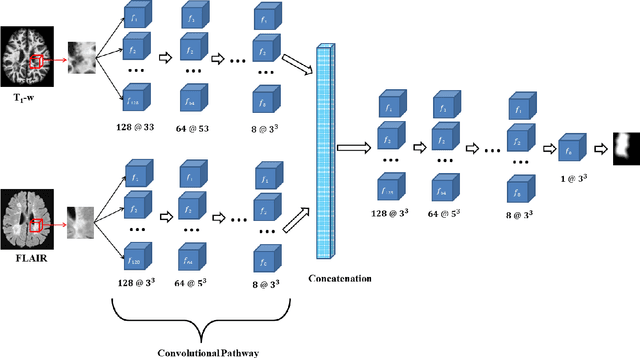
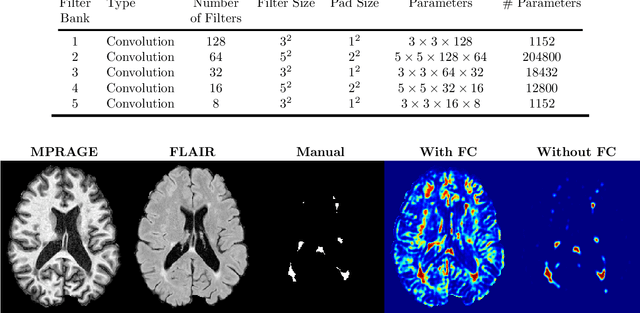
Multiple Sclerosis (MS) is an autoimmune disease that leads to lesions in the central nervous system. Magnetic resonance (MR) images provide sufficient imaging contrast to visualize and detect lesions, particularly those in the white matter. Quantitative measures based on various features of lesions have been shown to be useful in clinical trials for evaluating therapies. Therefore robust and accurate segmentation of white matter lesions from MR images can provide important information about the disease status and progression. In this paper, we propose a fully convolutional neural network (CNN) based method to segment white matter lesions from multi-contrast MR images. The proposed CNN based method contains two convolutional pathways. The first pathway consists of multiple parallel convolutional filter banks catering to multiple MR modalities. In the second pathway, the outputs of the first one are concatenated and another set of convolutional filters are applied. The output of this last pathway produces a membership function for lesions that may be thresholded to obtain a binary segmentation. The proposed method is evaluated on a dataset of 100 MS patients, as well as the ISBI 2015 challenge data consisting of 14 patients. The comparison is performed against four publicly available MS lesion segmentation methods. Significant improvement in segmentation quality over the competing methods is demonstrated on various metrics, such as Dice and false positive ratio. While evaluating on the ISBI 2015 challenge data, our method produces a score of 90.48, where a score of 90 is considered to be comparable to a human rater.