 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting 2D weak labels from volume labels using multiple instance learning in CT hemorrhage detection
Nov 13, 2019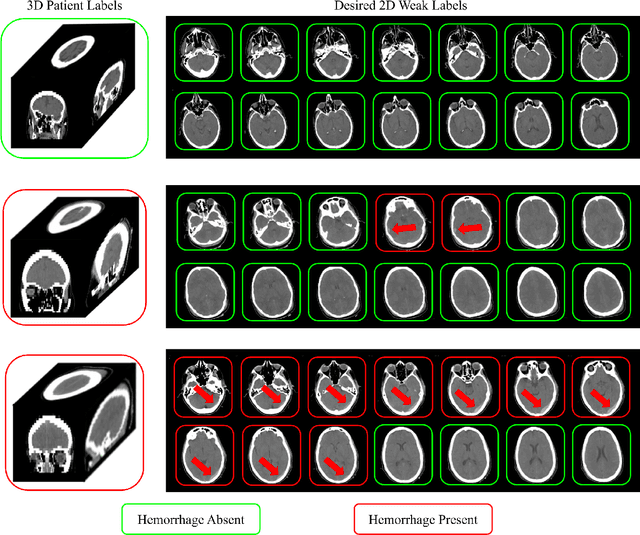

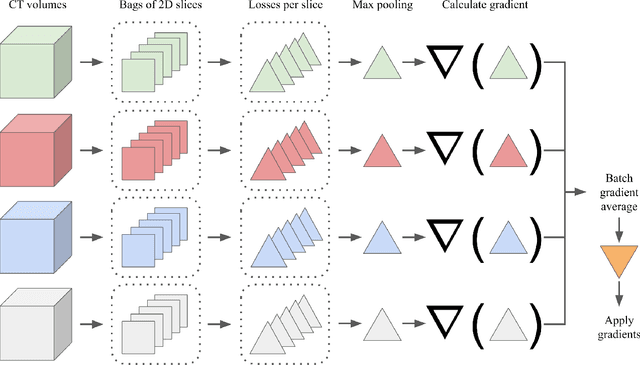
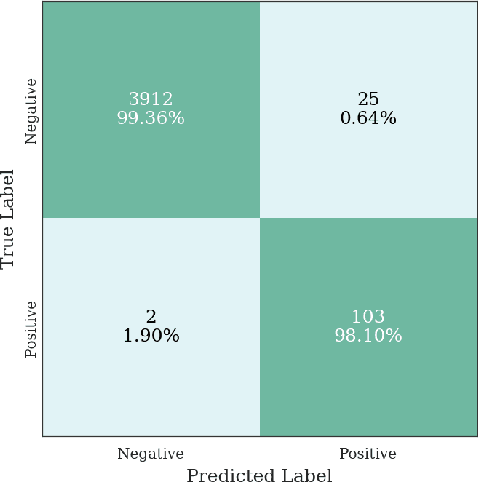
Multiple instance learning (MIL) is a supervised learning methodology that aims to allow models to learn instance class labels from bag class labels, where a bag is defined to contain multiple instances. MIL is gaining traction for learning from weak labels but has not been widely applied to 3D medical imaging. MIL is well-suited to clinical CT acquisitions since (1) the highly anisotropic voxels hinder application of traditional 3D networks and (2) patch-based networks have limited ability to learn whole volume labels. In this work, we apply MIL with a deep convolutional neural network to identify whether clinical CT head image volumes possess one or more large hemorrhages (> 20cm$^3$), resulting in a learned 2D model without the need for 2D slice annotations. Individual image volumes are considered separate bags, and the slices in each volume are instances. Such a framework sets the stage for incorporating information obtained in clinical reports to help train a 2D segmentation approach. Within this context, we evaluate the data requirements to enable generalization of MIL by varying the amount of training data. Our results show that a training size of at least 400 patient image volumes was needed to achieve accurate per-slice hemorrhage detection. Over a five-fold cross-validation, the leading model, which made use of the maximum number of training volumes, had an average true positive rate of 98.10%, an average true negative rate of 99.36%, and an average precision of 0.9698. The models have been made available along with source code to enabled continued exploration and adaption of MIL in CT neuroimaging.
Distributed deep learning for robust multi-site segmentation of CT imaging after traumatic brain injury
Mar 11, 2019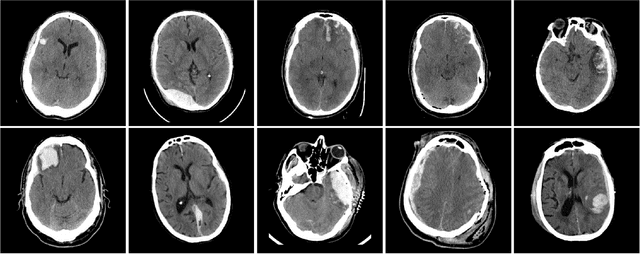

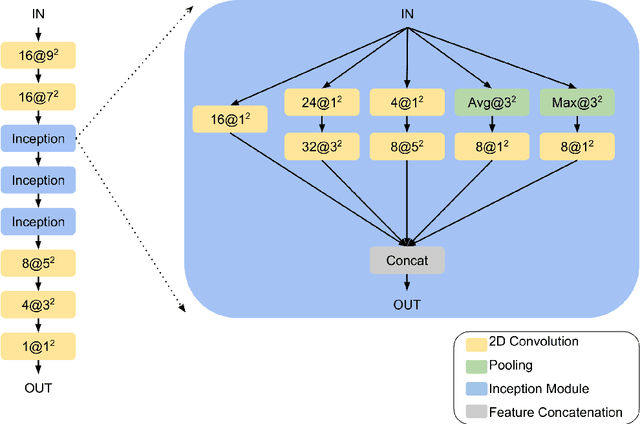

Machine learning models are becoming commonplace in the domain of medical imaging, and with these methods comes an ever-increasing need for more data. However, to preserve patient anonymity it is frequently impractical or prohibited to transfer protected health information (PHI) between institutions. Additionally, due to the nature of some studies, there may not be a large public dataset available on which to train models. To address this conundrum, we analyze the efficacy of transferring the model itself in lieu of data between different sites. By doing so we accomplish two goals: 1) the model gains access to training on a larger dataset that it could not normally obtain and 2) the model better generalizes, having trained on data from separate locations. In this paper, we implement multi-site learning with disparate datasets from the National Institutes of Health (NIH) and Vanderbilt University Medical Center (VUMC) without compromising PHI. Three neural networks are trained to convergence on a computed tomography (CT) brain hematoma segmentation task: one only with NIH data,one only with VUMC data, and one multi-site model alternating between NIH and VUMC data. Resultant lesion masks with the multi-site model attain an average Dice similarity coefficient of 0.64 and the automatically segmented hematoma volumes correlate to those done manually with a Pearson correlation coefficient of 0.87,corresponding to an 8% and 5% improvement, respectively, over the single-site model counterparts.
Montage based 3D Medical Image Retrieval from Traumatic Brain Injury Cohort using Deep Convolutional Neural Network
Dec 10, 2018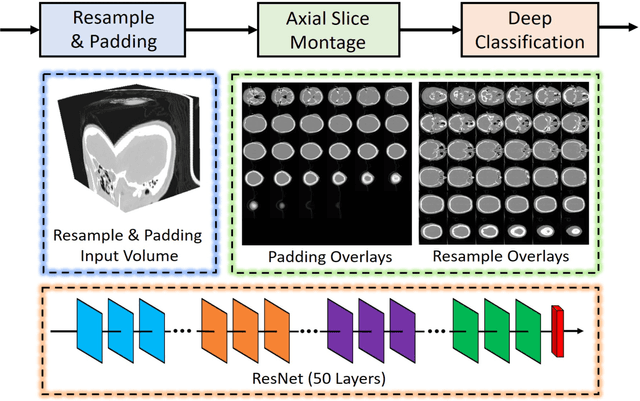
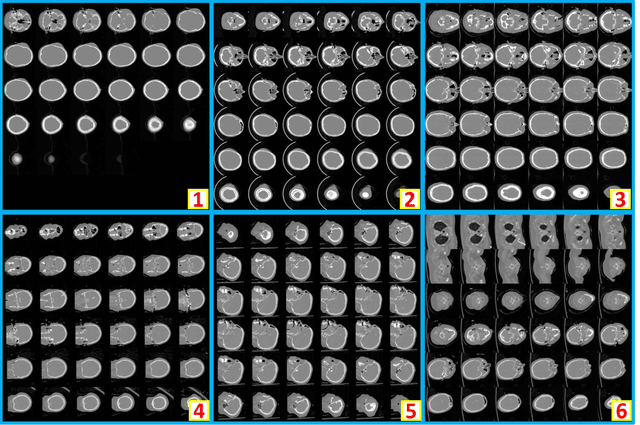
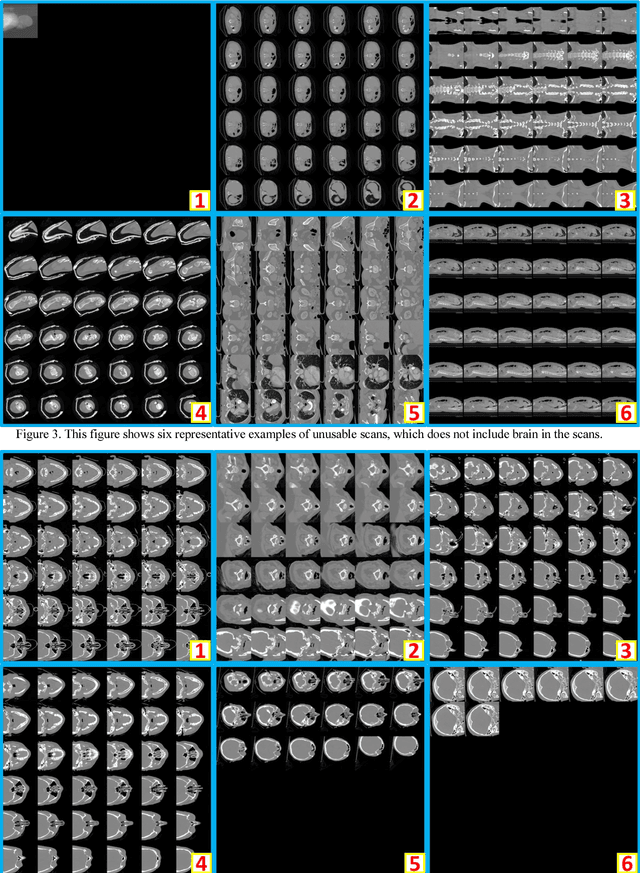
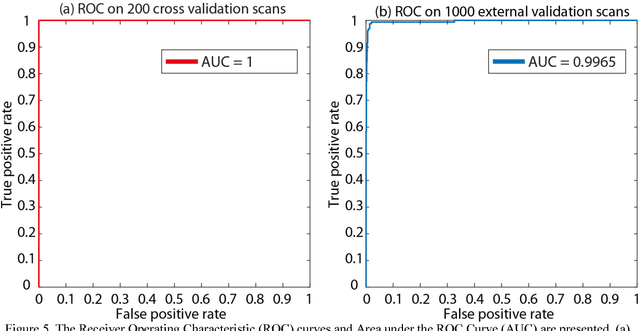
Brain imaging analysis on clinically acquired computed tomography (CT) is essential for the diagnosis, risk prediction of progression, and treatment of the structural phenotypes of traumatic brain injury (TBI). However, in real clinical imaging scenarios, entire body CT images (e.g., neck, abdomen, chest, pelvis) are typically captured along with whole brain CT scans. For instance, in a typical sample of clinical TBI imaging cohort, only ~15% of CT scans actually contain whole brain CT images suitable for volumetric brain analyses; the remaining are partial brain or non-brain images. Therefore, a manual image retrieval process is typically required to isolate the whole brain CT scans from the entire cohort. However, the manual image retrieval is time and resource consuming and even more difficult for the larger cohorts. To alleviate the manual efforts, in this paper we propose an automated 3D medical image retrieval pipeline, called deep montage-based image retrieval (dMIR), which performs classification on 2D montage images via a deep convolutional neural network. The novelty of the proposed method for image processing is to characterize the medical image retrieval task based on the montage images. In a cohort of 2000 clinically acquired TBI scans, 794 scans were used as training data, 206 scans were used as validation data, and the remaining 1000 scans were used as testing data. The proposed achieved accuracy=1.0, recall=1.0, precision=1.0, f1=1.0 for validation data, while achieved accuracy=0.988, recall=0.962, precision=0.962, f1=0.962 for testing data. Thus, the proposed dMIR is able to perform accurate CT whole brain image retrieval from large-scale clinical cohorts.