 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWorld Models: A Comprehensive Survey of Architectures, Methodologies, Reasoning Paradigms, and Applications
May 28, 2026World models, internal simulators that learn the structure and dynamics of an environment, have emerged as a central paradigm in the pursuit of artificial general intelligence, enabling agents to predict, plan, and reason within learned representations. Despite rapid progress across reinforcement learning, robotics, autonomous driving, and video generation, the field lacks a unified framework integrating its diverse architectural choices, training methods, reasoning mechanisms, and application settings. This survey addresses that gap with a multi-axis taxonomy organized along four dimensions: (i) architecture, encompassing representation format, dynamics formulation, input modality, learning paradigm, and downstream application; (ii) methodological family, including state-space and recurrent approaches, transformer-based models, diffusion-based generators, physics-informed networks, and language-augmented multimodal systems; (iii) reasoning strategy, covering imagination-based planning, latent policy learning, counterfactual reasoning, and planning under uncertainty; and (iv) application domain, spanning robotics, autonomous driving, video prediction, multimodal agents, reinforcement learning, scientific modeling, medical imaging, educational measurement, and business and finance. Tracing the field from early cognitive-science foundations to milestone systems such as PlaNet, the Dreamer family, MuZero, Sora, Cosmos, and Genie, we examine how these dimensions interact and highlight the recent convergence of chain-of-thought reasoning with world-model imagination. We review evaluation protocols and benchmarks, identify persistent challenges such as compounding prediction errors, sim-to-real transfer, and fragmented evaluation, and outline future directions toward unified multimodal world models, foundation-scale interactive simulators, and safe deployment in safety-critical domains.
YOTOnet: Zero-Shot Cross-Domain Fault Diagnosis via Domain-Conditioned Mixture of Experts
May 06, 2026Mechanical equipment forms the critical backbone of modern industrial production, yet domain shift severely limits the generalization of deep learning based fault diagnosis models across different equipment and operating conditions.Inspired by the success of foundation models in achieving zero-shotgeneralization, we propose YOTOnet (You Only Train Once), a novel architecture specifically designed for cross-domain fault diagnosis in mechanical equipment.YOTOnet comprises three core components: (1) a physics-aware Invariant Feature Distiller that extracts domain-agnostic representations using multi-scale dilated convolutions and FFT-based time-frequency fusion,(2) Domain-Conditioned Sparse Experts (DC-MoE) that adaptively route inputs to specialized processors via learned gating without external meta-data, and (3) a dual-head classification system with auxiliary supervision.Extensive validation on five public bearing datasets (CWRU, MFPT, XJTU,OTTAWA, HUST) through 30 cross-dataset protocols demonstrates the superiority of YOTOnet compared with other state-of-the-art methods. Critically, we observe a clear scaling effect-average test F1 improves from 0.5339(1 training dataset) to 0.705 (4 datasets), with a clear gain when moving from 3 to 4 datasets. These findings provide empirical evidence that foundation model principles can enable robust, train-once deployment for industrial fault diagnosis.
Vibe Medicine: Redefining Biomedical Research Through Human-AI Co-Work
Apr 26, 2026With the emergence of large language models (LLMs) and AI agent frameworks, the human-AI co-work paradigm known as Vibe Coding is changing how people code, making it more accessible and productive. In scientific research, where workflows are more complex and the burden of specialized labor limits independent researchers and those in low-resource areas, the potential impact is even greater, particularly in biomedicine, which involves heterogeneous data modalities and multi-step analytical pipelines. In this paper, we introduce Vibe Medicine, a co-work paradigm in which clinicians and researchers direct skill-augmented AI agents through natural language to execute complex, multi-step biomedical workflows, while retaining the role of research director who specifies objectives, reviews intermediate results, and makes domain-informed decisions. The enabling infrastructure consists of three layers: capable LLMs, agent frameworks such as OpenClaw and Hermes Agent, and the OpenClaw medical skills collection, which includes more than 1,000 curated skills from multiple open-source repositories. We analyze the architecture and skill categories of this collection across ten biomedical domains, and present case studies covering rare disease diagnosis, drug repurposing, and clinical trial design that demonstrate end-to-end workflows in practice. We also identify the principal risks, such as hallucination, data privacy, and over-reliance, and outline directions toward more reliable, trustworthy, and clinically integrated agent-assisted research that advances research and technological equity and reduces health care resource disparities.
Rethinking Token Prediction: Tree-Structured Diffusion Language Model
Apr 04, 2026Discrete diffusion language models have emerged as a competitive alternative to auto-regressive language models, but training them efficiently under limited parameter and memory budgets remains challenging. Modern architectures are predominantly based on a full-vocabulary token prediction layer, which accounts for a substantial fraction of model parameters (e.g., more than 20% in small scale DiT-style designs) and often dominates peak GPU memory usage. This leads to inefficient use of both parameters and memory under constrained training resources. To address this issue, we revisit the necessity of explicit full-vocabulary prediction, and instead exploit the inherent structure among tokens to build a tree-structured diffusion language model. Specifically, we model the diffusion process with intermediate latent states corresponding to a token's ancestor nodes in a pre-constructed vocabulary tree. This tree-structured factorization exponentially reduces the classification dimensionality, makes the prediction head negligible in size, and enables reallocation of parameters to deepen the attention blocks. Empirically, under the same parameter budget, our method reduces peak GPU memory usage by half while matching the perplexity performance of state-of-the-art discrete diffusion language models.
The Rank and Gradient Lost in Non-stationarity: Sample Weight Decay for Mitigating Plasticity Loss in Reinforcement Learning
Apr 02, 2026Deep reinforcement learning (RL) suffers from plasticity loss severely due to the nature of non-stationarity, which impairs the ability to adapt to new data and learn continually. Unfortunately, our understanding of how plasticity loss arises, dissipates, and can be dissolved remains limited to empirical findings, leaving the theoretical end underexplored.To address this gap, we study the plasticity loss problem from the theoretical perspective of network optimization. By formally characterizing the two culprit factors in online RL process: the non-stationarity of data distributions and the non-stationarity of targets induced by bootstrapping, our theory attributes the loss of plasticity to two mechanisms: the rank collapse of the Neural Tangent Kernel (NTK) Gram matrix and the $Θ(\frac{1}{k})$ decay of gradient magnitude. The first mechanism echoes prior empirical findings from the theoretical perspective and sheds light on the effects of existing methods, e.g., network reset, neuron recycle, and noise injection. Against this backdrop, we focus primarily on the second mechanism and aim to alleviate plasticity loss by addressing the gradient attenuation issue, which is orthogonal to existing methods. We propose Sample Weight Decay -- a lightweight method to restore gradient magnitude, as a general remedy to plasticity loss for deep RL methods based on experience replay. In experiments, we evaluate the efficacy of \methodName upon TD3, \myadded{Double DQN} and SAC with SimBa architecture in MuJoCo, \myadded{ALE} and DeepMind Control Suite tasks. The results demonstrate that \methodName effectively alleviates plasticity loss and consistently improves learning performance across various configurations of deep RL algorithms, UTD, network architectures, and environments, achieving SOTA performance on challenging DMC Humanoid tasks.
Measure gradients, not activations! Enhancing neuronal activity in deep reinforcement learning
May 29, 2025Deep reinforcement learning (RL) agents frequently suffer from neuronal activity loss, which impairs their ability to adapt to new data and learn continually. A common method to quantify and address this issue is the tau-dormant neuron ratio, which uses activation statistics to measure the expressive ability of neurons. While effective for simple MLP-based agents, this approach loses statistical power in more complex architectures. To address this, we argue that in advanced RL agents, maintaining a neuron's learning capacity, its ability to adapt via gradient updates, is more critical than preserving its expressive ability. Based on this insight, we shift the statistical objective from activations to gradients, and introduce GraMa (Gradient Magnitude Neural Activity Metric), a lightweight, architecture-agnostic metric for quantifying neuron-level learning capacity. We show that GraMa effectively reveals persistent neuron inactivity across diverse architectures, including residual networks, diffusion models, and agents with varied activation functions. Moreover, resetting neurons guided by GraMa (ReGraMa) consistently improves learning performance across multiple deep RL algorithms and benchmarks, such as MuJoCo and the DeepMind Control Suite.
Teleportation With Null Space Gradient Projection for Optimization Acceleration
Feb 17, 2025Optimization techniques have become increasingly critical due to the ever-growing model complexity and data scale. In particular, teleportation has emerged as a promising approach, which accelerates convergence of gradient descent-based methods by navigating within the loss invariant level set to identify parameters with advantageous geometric properties. Existing teleportation algorithms have primarily demonstrated their effectiveness in optimizing Multi-Layer Perceptrons (MLPs), but their extension to more advanced architectures, such as Convolutional Neural Networks (CNNs) and Transformers, remains challenging. Moreover, they often impose significant computational demands, limiting their applicability to complex architectures. To this end, we introduce an algorithm that projects the gradient of the teleportation objective function onto the input null space, effectively preserving the teleportation within the loss invariant level set and reducing computational cost. Our approach is readily generalizable from MLPs to CNNs, transformers, and potentially other advanced architectures. We validate the effectiveness of our algorithm across various benchmark datasets and optimizers, demonstrating its broad applicability.
S2TX: Cross-Attention Multi-Scale State-Space Transformer for Time Series Forecasting
Feb 17, 2025Time series forecasting has recently achieved significant progress with multi-scale models to address the heterogeneity between long and short range patterns. Despite their state-of-the-art performance, we identify two potential areas for improvement. First, the variates of the multivariate time series are processed independently. Moreover, the multi-scale (long and short range) representations are learned separately by two independent models without communication. In light of these concerns, we propose State Space Transformer with cross-attention (S2TX). S2TX employs a cross-attention mechanism to integrate a Mamba model for extracting long-range cross-variate context and a Transformer model with local window attention to capture short-range representations. By cross-attending to the global context, the Transformer model further facilitates variate-level interactions as well as local/global communications. Comprehensive experiments on seven classic long-short range time-series forecasting benchmark datasets demonstrate that S2TX can achieve highly robust SOTA results while maintaining a low memory footprint.
Large Language Models for Bioinformatics
Jan 10, 2025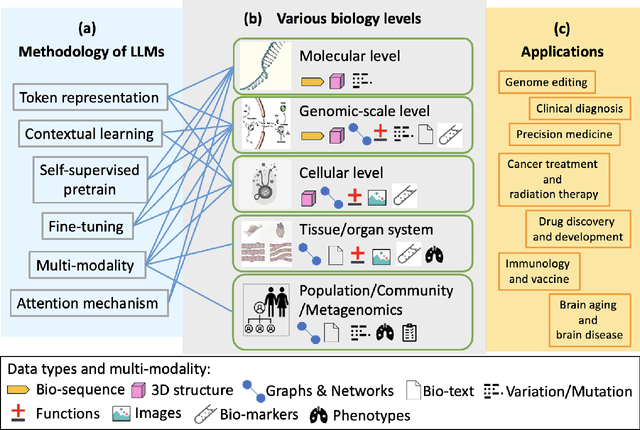
With the rapid advancements in large language model (LLM) technology and the emergence of bioinformatics-specific language models (BioLMs), there is a growing need for a comprehensive analysis of the current landscape, computational characteristics, and diverse applications. This survey aims to address this need by providing a thorough review of BioLMs, focusing on their evolution, classification, and distinguishing features, alongside a detailed examination of training methodologies, datasets, and evaluation frameworks. We explore the wide-ranging applications of BioLMs in critical areas such as disease diagnosis, drug discovery, and vaccine development, highlighting their impact and transformative potential in bioinformatics. We identify key challenges and limitations inherent in BioLMs, including data privacy and security concerns, interpretability issues, biases in training data and model outputs, and domain adaptation complexities. Finally, we highlight emerging trends and future directions, offering valuable insights to guide researchers and clinicians toward advancing BioLMs for increasingly sophisticated biological and clinical applications.
Score-Based Metropolis-Hastings Algorithms
Dec 31, 2024



In this paper, we introduce a new approach for integrating score-based models with the Metropolis-Hastings algorithm. While traditional score-based diffusion models excel in accurately learning the score function from data points, they lack an energy function, making the Metropolis-Hastings adjustment step inaccessible. Consequently, the unadjusted Langevin algorithm is often used for sampling using estimated score functions. The lack of an energy function then prevents the application of the Metropolis-adjusted Langevin algorithm and other Metropolis-Hastings methods, limiting the wealth of other algorithms developed that use acceptance functions. We address this limitation by introducing a new loss function based on the \emph{detailed balance condition}, allowing the estimation of the Metropolis-Hastings acceptance probabilities given a learned score function. We demonstrate the effectiveness of the proposed method for various scenarios, including sampling from heavy-tail distributions.