 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScore-based Metropolis-Hastings for Fractional Langevin Algorithms
Jan 31, 2026Sampling from heavy-tailed and multimodal distributions is challenging when neither the target density nor the proposal density can be evaluated, as in $α$-stable Lévy-driven fractional Langevin algorithms. While the target distribution can be estimated from data via score-based or energy-based models, the $α$-stable proposal density and its score are generally unavailable, rendering classical density-based Metropolis--Hastings (MH) corrections impractical. Consequently, existing fractional Langevin methods operate in an unadjusted regime and can exhibit substantial finite-time errors and poor empirical control of tail behavior. We introduce the Metropolis-Adjusted Fractional Langevin Algorithm (MAFLA), an MH-inspired, fully score-based correction mechanism. MAFLA employs designed proxies for fractional proposal score gradients under isotropic symmetric $α$-stable noise and learns an acceptance function via Score Balance Matching. We empirically illustrate the strong performance of MAFLA on a series of tasks including combinatorial optimization problems where the method significantly improves finite time sampling accuracy over unadjusted fractional Langevin dynamics.
Conditional Average Treatment Effect Estimation Under Hidden Confounders
Jun 14, 2025One of the major challenges in estimating conditional potential outcomes and conditional average treatment effects (CATE) is the presence of hidden confounders. Since testing for hidden confounders cannot be accomplished only with observational data, conditional unconfoundedness is commonly assumed in the literature of CATE estimation. Nevertheless, under this assumption, CATE estimation can be significantly biased due to the effects of unobserved confounders. In this work, we consider the case where in addition to a potentially large observational dataset, a small dataset from a randomized controlled trial (RCT) is available. Notably, we make no assumptions on the existence of any covariate information for the RCT dataset, we only require the outcomes to be observed. We propose a CATE estimation method based on a pseudo-confounder generator and a CATE model that aligns the learned potential outcomes from the observational data with those observed from the RCT. Our method is applicable to many practical scenarios of interest, particularly those where privacy is a concern (e.g., medical applications). Extensive numerical experiments are provided demonstrating the effectiveness of our approach for both synthetic and real-world datasets.
Teleportation With Null Space Gradient Projection for Optimization Acceleration
Feb 17, 2025Optimization techniques have become increasingly critical due to the ever-growing model complexity and data scale. In particular, teleportation has emerged as a promising approach, which accelerates convergence of gradient descent-based methods by navigating within the loss invariant level set to identify parameters with advantageous geometric properties. Existing teleportation algorithms have primarily demonstrated their effectiveness in optimizing Multi-Layer Perceptrons (MLPs), but their extension to more advanced architectures, such as Convolutional Neural Networks (CNNs) and Transformers, remains challenging. Moreover, they often impose significant computational demands, limiting their applicability to complex architectures. To this end, we introduce an algorithm that projects the gradient of the teleportation objective function onto the input null space, effectively preserving the teleportation within the loss invariant level set and reducing computational cost. Our approach is readily generalizable from MLPs to CNNs, transformers, and potentially other advanced architectures. We validate the effectiveness of our algorithm across various benchmark datasets and optimizers, demonstrating its broad applicability.
Score-Based Metropolis-Hastings Algorithms
Dec 31, 2024



In this paper, we introduce a new approach for integrating score-based models with the Metropolis-Hastings algorithm. While traditional score-based diffusion models excel in accurately learning the score function from data points, they lack an energy function, making the Metropolis-Hastings adjustment step inaccessible. Consequently, the unadjusted Langevin algorithm is often used for sampling using estimated score functions. The lack of an energy function then prevents the application of the Metropolis-adjusted Langevin algorithm and other Metropolis-Hastings methods, limiting the wealth of other algorithms developed that use acceptance functions. We address this limitation by introducing a new loss function based on the \emph{detailed balance condition}, allowing the estimation of the Metropolis-Hastings acceptance probabilities given a learned score function. We demonstrate the effectiveness of the proposed method for various scenarios, including sampling from heavy-tail distributions.
Random Linear Projections Loss for Hyperplane-Based Optimization in Regression Neural Networks
Nov 21, 2023



Despite their popularity across a wide range of domains, regression neural networks are prone to overfitting complex datasets. In this work, we propose a loss function termed Random Linear Projections (RLP) loss, which is empirically shown to mitigate overfitting. With RLP loss, the distance between sets of hyperplanes connecting fixed-size subsets of the neural network's feature-prediction pairs and feature-label pairs is minimized. The intuition behind this loss derives from the notion that if two functions share the same hyperplanes connecting all subsets of feature-label pairs, then these functions must necessarily be equivalent. Our empirical studies, conducted across benchmark datasets and representative synthetic examples, demonstrate the improvements of the proposed RLP loss over mean squared error (MSE). Specifically, neural networks trained with the RLP loss achieve better performance while requiring fewer data samples and are more robust to additive noise. We provide theoretical analysis supporting our empirical findings.
Counterfactual Data Augmentation with Contrastive Learning
Nov 07, 2023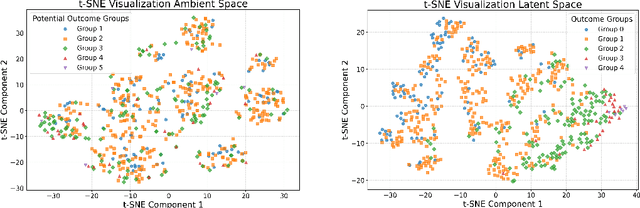
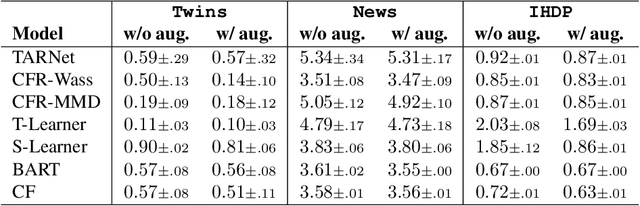

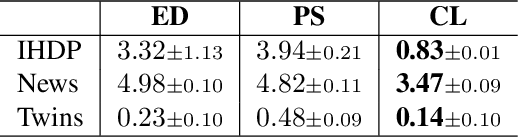
Statistical disparity between distinct treatment groups is one of the most significant challenges for estimating Conditional Average Treatment Effects (CATE). To address this, we introduce a model-agnostic data augmentation method that imputes the counterfactual outcomes for a selected subset of individuals. Specifically, we utilize contrastive learning to learn a representation space and a similarity measure such that in the learned representation space close individuals identified by the learned similarity measure have similar potential outcomes. This property ensures reliable imputation of counterfactual outcomes for the individuals with close neighbors from the alternative treatment group. By augmenting the original dataset with these reliable imputations, we can effectively reduce the discrepancy between different treatment groups, while inducing minimal imputation error. The augmented dataset is subsequently employed to train CATE estimation models. Theoretical analysis and experimental studies on synthetic and semi-synthetic benchmarks demonstrate that our method achieves significant improvements in both performance and robustness to overfitting across state-of-the-art models.
Individual Treatment Effects in Extreme Regimes
Jun 20, 2023Understanding individual treatment effects in extreme regimes is important for characterizing risks associated with different interventions. This is hindered by the fact that extreme regime data may be hard to collect, as it is scarcely observed in practice. In addressing this issue, we propose a new framework for estimating the individual treatment effect in extreme regimes (ITE$_2$). Specifically, we quantify this effect by the changes in the tail decay rates of potential outcomes in the presence or absence of the treatment. Subsequently, we establish conditions under which ITE$_2$ may be calculated and develop algorithms for its computation. We demonstrate the efficacy of our proposed method on various synthetic and semi-synthetic datasets.
Causal Mediation Analysis with Multi-dimensional and Indirectly Observed Mediators
Jun 13, 2023



Causal mediation analysis (CMA) is a powerful method to dissect the total effect of a treatment into direct and mediated effects within the potential outcome framework. This is important in many scientific applications to identify the underlying mechanisms of a treatment effect. However, in many scientific applications the mediator is unobserved, but there may exist related measurements. For example, we may want to identify how changes in brain activity or structure mediate an antidepressant's effect on behavior, but we may only have access to electrophysiological or imaging brain measurements. To date, most CMA methods assume that the mediator is one-dimensional and observable, which oversimplifies such real-world scenarios. To overcome this limitation, we introduce a CMA framework that can handle complex and indirectly observed mediators based on the identifiable variational autoencoder (iVAE) architecture. We prove that the true joint distribution over observed and latent variables is identifiable with the proposed method. Additionally, our framework captures a disentangled representation of the indirectly observed mediator and yields accurate estimation of the direct and mediated effects in synthetic and semi-synthetic experiments, providing evidence of its potential utility in real-world applications.
Few-Shot Continual Learning for Conditional Generative Adversarial Networks
May 19, 2023In few-shot continual learning for generative models, a target mode must be learned with limited samples without adversely affecting the previously learned modes. In this paper, we propose a new continual learning approach for conditional generative adversarial networks (cGAN) based on a new mode-affinity measure for generative modeling. Our measure is entirely based on the cGAN's discriminator and can identify the existing modes that are most similar to the target. Subsequently, we expand the continual learning model by including the target mode using a weighted label derived from those of the closest modes. To prevent catastrophic forgetting, we first generate labeled data samples using the cGAN's generator, and then train the cGAN model for the target mode while memory replaying with the generated data. Our experimental results demonstrate the efficacy of our approach in improving the generation performance over the baselines and the state-of-the-art approaches for various standard datasets while utilizing fewer training samples.
Domain Adaptation via Rebalanced Sub-domain Alignment
Feb 03, 2023

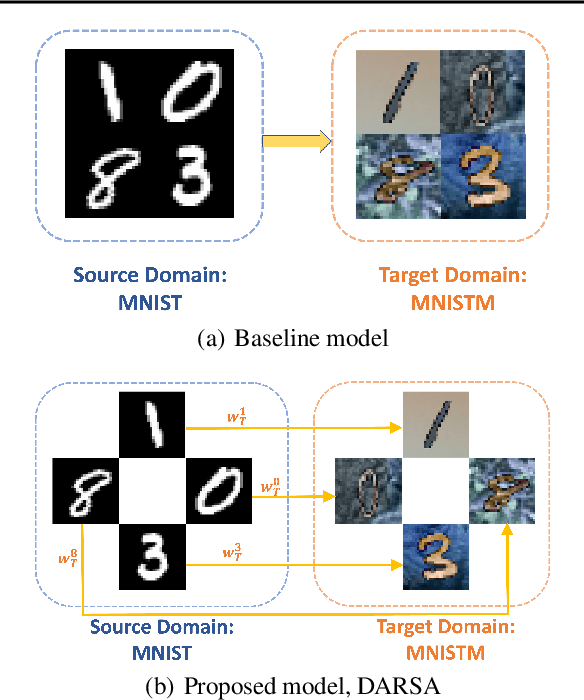

Unsupervised domain adaptation (UDA) is a technique used to transfer knowledge from a labeled source domain to a different but related unlabeled target domain. While many UDA methods have shown success in the past, they often assume that the source and target domains must have identical class label distributions, which can limit their effectiveness in real-world scenarios. To address this limitation, we propose a novel generalization bound that reweights source classification error by aligning source and target sub-domains. We prove that our proposed generalization bound is at least as strong as existing bounds under realistic assumptions, and we empirically show that it is much stronger on real-world data. We then propose an algorithm to minimize this novel generalization bound. We demonstrate by numerical experiments that this approach improves performance in shifted class distribution scenarios compared to state-of-the-art methods.