 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-Aware Multi-Expert Architecture For Lifelong Deep Learning
Dec 12, 2025Lifelong deep learning (LDL) trains neural networks to learn sequentially across tasks while preserving prior knowledge. We propose Task-Aware Multi-Expert (TAME), a continual learning algorithm that leverages task similarity to guide expert selection and knowledge transfer. TAME maintains a pool of pretrained neural networks and activates the most relevant expert for each new task. A shared dense layer integrates features from the chosen expert to generate predictions. To reduce catastrophic forgetting, TAME uses a replay buffer that stores representative samples and embeddings from previous tasks and reuses them during training. An attention mechanism further prioritizes the most relevant stored information for each prediction. Together, these components allow TAME to adapt flexibly while retaining important knowledge across evolving task sequences. Experiments on binary classification tasks derived from CIFAR-100 show that TAME improves accuracy on new tasks while sustaining performance on earlier ones, highlighting its effectiveness in balancing adaptation and retention in lifelong learning settings.
Counterfactual Data Augmentation with Contrastive Learning
Nov 07, 2023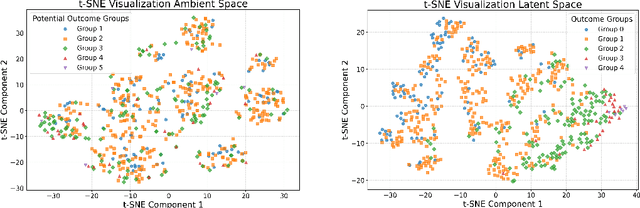
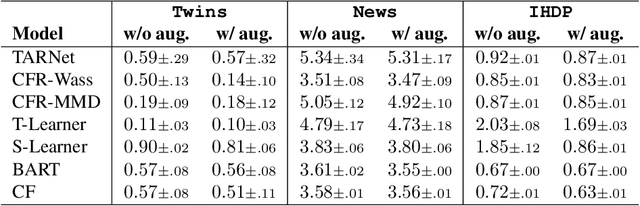

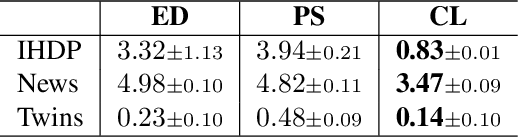
Statistical disparity between distinct treatment groups is one of the most significant challenges for estimating Conditional Average Treatment Effects (CATE). To address this, we introduce a model-agnostic data augmentation method that imputes the counterfactual outcomes for a selected subset of individuals. Specifically, we utilize contrastive learning to learn a representation space and a similarity measure such that in the learned representation space close individuals identified by the learned similarity measure have similar potential outcomes. This property ensures reliable imputation of counterfactual outcomes for the individuals with close neighbors from the alternative treatment group. By augmenting the original dataset with these reliable imputations, we can effectively reduce the discrepancy between different treatment groups, while inducing minimal imputation error. The augmented dataset is subsequently employed to train CATE estimation models. Theoretical analysis and experimental studies on synthetic and semi-synthetic benchmarks demonstrate that our method achieves significant improvements in both performance and robustness to overfitting across state-of-the-art models.
PrACTiS: Perceiver-Attentional Copulas for Time Series
Oct 03, 2023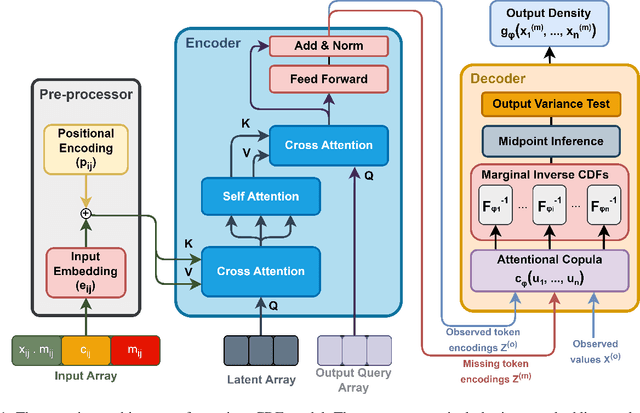
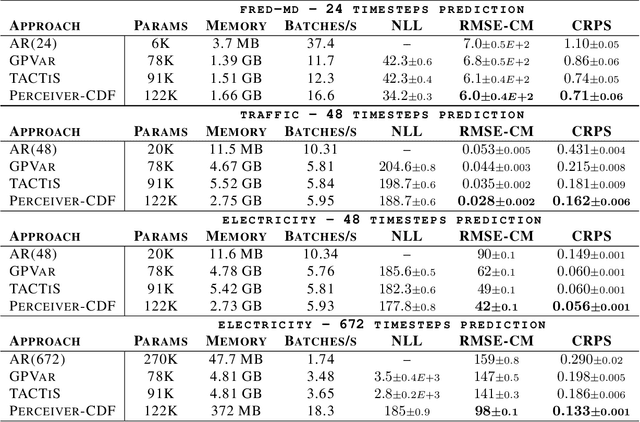
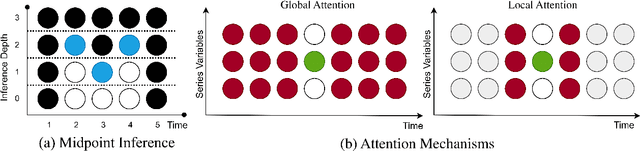
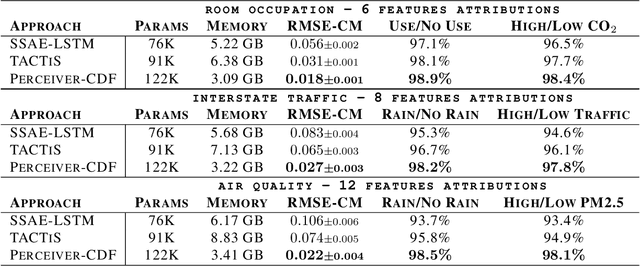
Transformers incorporating copula structures have demonstrated remarkable performance in time series prediction. However, their heavy reliance on self-attention mechanisms demands substantial computational resources, thus limiting their practical utility across a wide range of tasks. In this work, we present a model that combines the perceiver architecture with a copula structure to enhance time-series forecasting. By leveraging the perceiver as the encoder, we efficiently transform complex, high-dimensional, multimodal data into a compact latent space, thereby significantly reducing computational demands. To further reduce complexity, we introduce midpoint inference and local attention mechanisms, enabling the model to capture dependencies within imputed samples effectively. Subsequently, we deploy the copula-based attention and output variance testing mechanism to capture the joint distribution of missing data, while simultaneously mitigating error propagation during prediction. Our experimental results on the unimodal and multimodal benchmarks showcase a consistent 20\% improvement over the state-of-the-art methods, while utilizing less than half of available memory resources.
Few-Shot Continual Learning for Conditional Generative Adversarial Networks
May 19, 2023In few-shot continual learning for generative models, a target mode must be learned with limited samples without adversely affecting the previously learned modes. In this paper, we propose a new continual learning approach for conditional generative adversarial networks (cGAN) based on a new mode-affinity measure for generative modeling. Our measure is entirely based on the cGAN's discriminator and can identify the existing modes that are most similar to the target. Subsequently, we expand the continual learning model by including the target mode using a weighted label derived from those of the closest modes. To prevent catastrophic forgetting, we first generate labeled data samples using the cGAN's generator, and then train the cGAN model for the target mode while memory replaying with the generated data. Our experimental results demonstrate the efficacy of our approach in improving the generation performance over the baselines and the state-of-the-art approaches for various standard datasets while utilizing fewer training samples.
Improving Open-Domain Dialogue Evaluation with a Causal Inference Model
Jan 31, 2023Effective evaluation methods remain a significant challenge for research on open-domain conversational dialogue systems. Explicit satisfaction ratings can be elicited from users, but users often do not provide ratings when asked, and those they give can be highly subjective. Post-hoc ratings by experts are an alternative, but these can be both expensive and complex to collect. Here, we explore the creation of automated methods for predicting both expert and user ratings of open-domain dialogues. We compare four different approaches. First, we train a baseline model using an end-to-end transformer to predict ratings directly from the raw dialogue text. The other three methods are variants of a two-stage approach in which we first extract interpretable features at the turn level that capture, among other aspects, user dialogue behaviors indicating contradiction, repetition, disinterest, compliments, or criticism. We project these features to the dialogue level and train a dialogue-level MLP regression model, a dialogue-level LSTM, and a novel causal inference model called counterfactual-LSTM (CF-LSTM) to predict ratings. The proposed CF-LSTM is a sequential model over turn-level features which predicts ratings using multiple regressors depending on hypotheses derived from the turn-level features. As a causal inference model, CF-LSTM aims to learn the underlying causes of a specific event, such as a low rating. We also bin the user ratings and perform classification experiments with all four models. In evaluation experiments on conversational data from the Alexa Prize SocialBot, we show that the CF-LSTM achieves the best performance for predicting dialogue ratings and classification.
Causal Knowledge Transfer from Task Affinity
Oct 07, 2022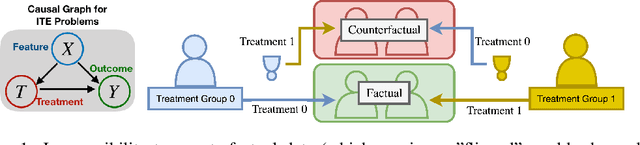
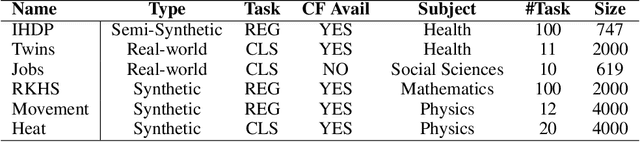
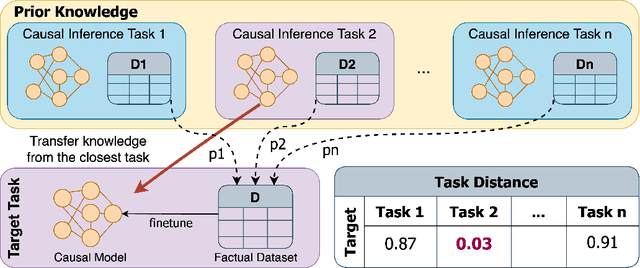

Recent developments in deep representation models through counterfactual balancing have led to a promising framework for estimating Individual Treatment Effects (ITEs) that are essential to causal inference in the Neyman-Rubin potential outcomes framework. While Randomized Control Trials are vital to understanding causal effects, they are sometimes infeasible, costly, or unethical to conduct. Motivated by these potential obstacles to data acquisition, we focus on transferring the causal knowledge acquired in prior experiments to new scenarios for which only limited data is available. To this end, we first observe that the absolute values of ITEs are invariant under the action of the symmetric group on the labels of treatments. Given this invariance, we propose a symmetrized task distance for calculating the similarity of a target scenario with those encountered before. The aforementioned task distance is then used to transfer causal knowledge from the closest of all the available previously learned tasks to the target scenario. We provide upper bounds on the counterfactual loss and ITE error of the target task indicating the transferability of causal knowledge. Empirical studies are provided for various real-world, semi-synthetic, and synthetic datasets demonstrating that the proposed symmetrized task distance is strongly related to the estimation of the counterfactual loss. Numerical results indicate that transferring causal knowledge reduces the amount of required data by up to 95% when compared to training from scratch. These results reveal the promise of our method when applied to important albeit challenging real-world scenarios such as transferring the knowledge of treatment effects (e.g., medicine, social policy, personal training, etc.) studied on a population to other groups absent in the study.
Task Affinity with Maximum Bipartite Matching in Few-Shot Learning
Oct 05, 2021
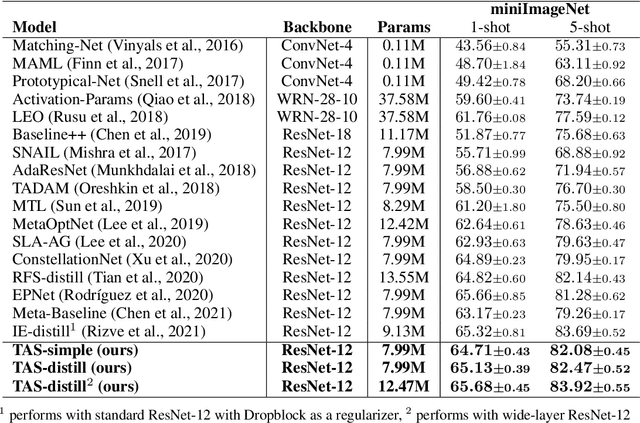
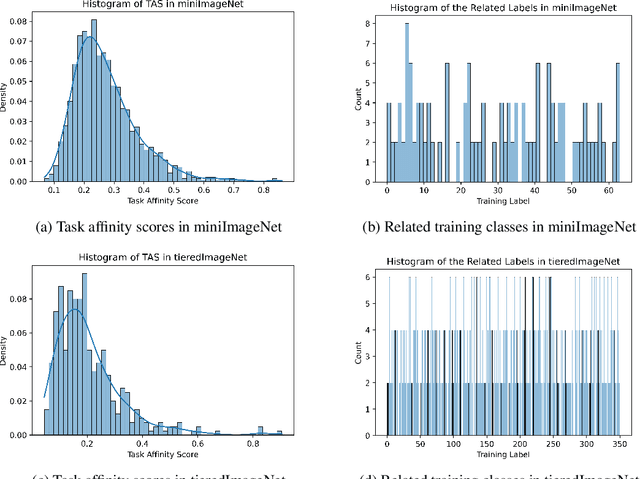
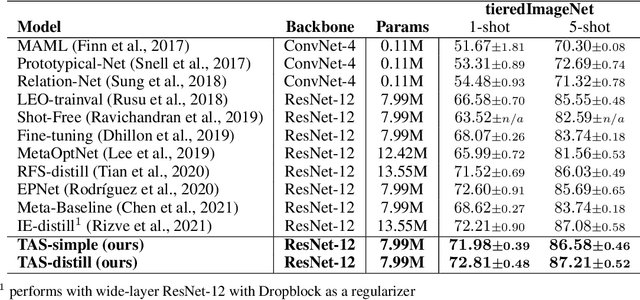
We propose an asymmetric affinity score for representing the complexity of utilizing the knowledge of one task for learning another one. Our method is based on the maximum bipartite matching algorithm and utilizes the Fisher Information matrix. We provide theoretical analyses demonstrating that the proposed score is mathematically well-defined, and subsequently use the affinity score to propose a novel algorithm for the few-shot learning problem. In particular, using this score, we find relevant training data labels to the test data and leverage the discovered relevant data for episodically fine-tuning a few-shot model. Results on various few-shot benchmark datasets demonstrate the efficacy of the proposed approach by improving the classification accuracy over the state-of-the-art methods even when using smaller models.
Neural Architecture Search From Fréchet Task Distance
Mar 25, 2021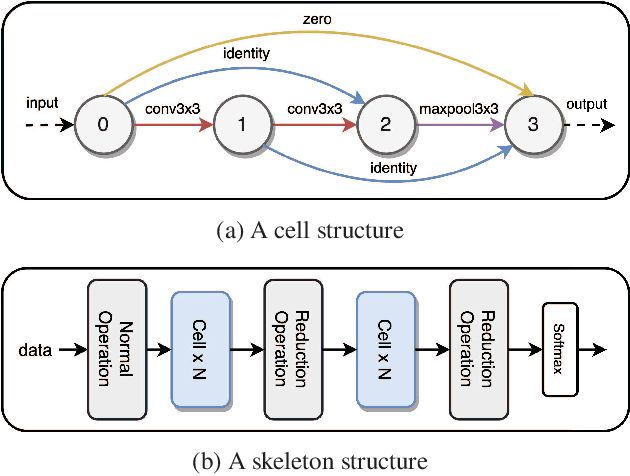

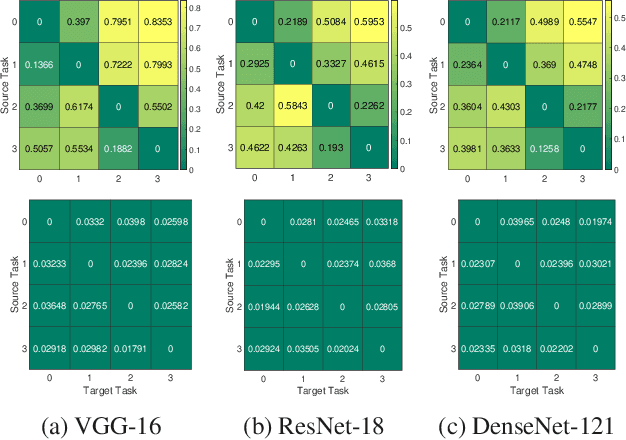

We formulate a Fr\'echet-type asymmetric distance between tasks based on Fisher Information Matrices. We show how the distance between a target task and each task in a given set of baseline tasks can be used to reduce the neural architecture search space for the target task. The complexity reduction in search space for task-specific architectures is achieved by building on the optimized architectures for similar tasks instead of doing a full search without using this side information. Experimental results demonstrate the efficacy of the proposed approach and its improvements over the state-of-the-art methods.
Neural Architecture Search From Task Similarity Measure
Mar 15, 2021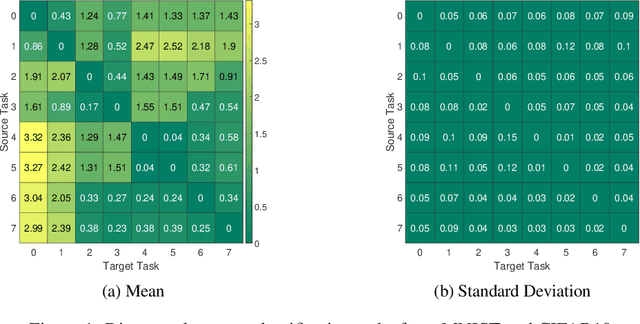
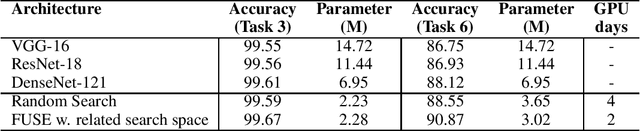
In this paper, we propose a neural architecture search framework based on a similarity measure between various tasks defined in terms of Fisher information. By utilizing the relation between a target and a set of existing tasks, the search space of architectures can be significantly reduced, making the discovery of the best candidates in the set of possible architectures tractable. This method eliminates the requirement for training the networks from scratch for the target task. Simulation results illustrate the efficacy of our proposed approach and its competitiveness with state-of-the-art methods.
Task-Aware Neural Architecture Search
Oct 27, 2020
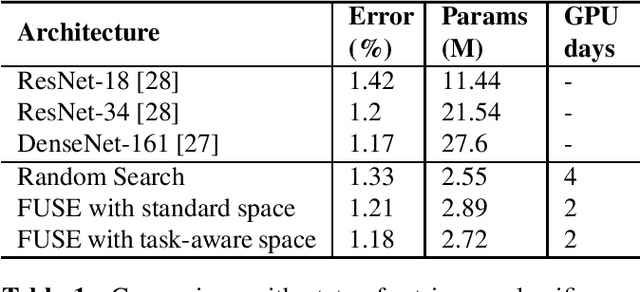

The design of handcrafted neural networks requires a lot of time and resources. Recent techniques in Neural Architecture Search (NAS) have proven to be competitive or better than traditional handcrafted design, although they require domain knowledge and have generally used limited search spaces. In this paper, we propose a novel framework for neural architecture search, utilizing a dictionary of models of base tasks and the similarity between the target task and the atoms of the dictionary; hence, generating an adaptive search space based on the base models of the dictionary. By introducing a gradient-based search algorithm, we can evaluate and discover the best architecture in the search space without fully training the networks. The experimental results show the efficacy of our proposed task-aware approach.