 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAmazon Nova AI Challenge -- Trusted AI: Advancing secure, AI-assisted software development
Aug 13, 2025AI systems for software development are rapidly gaining prominence, yet significant challenges remain in ensuring their safety. To address this, Amazon launched the Trusted AI track of the Amazon Nova AI Challenge, a global competition among 10 university teams to drive advances in secure AI. In the challenge, five teams focus on developing automated red teaming bots, while the other five create safe AI assistants. This challenge provides teams with a unique platform to evaluate automated red-teaming and safety alignment methods through head-to-head adversarial tournaments where red teams have multi-turn conversations with the competing AI coding assistants to test their safety alignment. Along with this, the challenge provides teams with a feed of high quality annotated data to fuel iterative improvement. Throughout the challenge, teams developed state-of-the-art techniques, introducing novel approaches in reasoning-based safety alignment, robust model guardrails, multi-turn jail-breaking, and efficient probing of large language models (LLMs). To support these efforts, the Amazon Nova AI Challenge team made substantial scientific and engineering investments, including building a custom baseline coding specialist model for the challenge from scratch, developing a tournament orchestration service, and creating an evaluation harness. This paper outlines the advancements made by university teams and the Amazon Nova AI Challenge team in addressing the safety challenges of AI for software development, highlighting this collaborative effort to raise the bar for AI safety.
S-EQA: Tackling Situational Queries in Embodied Question Answering
May 08, 2024We present and tackle the problem of Embodied Question Answering (EQA) with Situational Queries (S-EQA) in a household environment. Unlike prior EQA work tackling simple queries that directly reference target objects and quantifiable properties pertaining them, EQA with situational queries (such as "Is the bathroom clean and dry?") is more challenging, as the agent needs to figure out not just what the target objects pertaining to the query are, but also requires a consensus on their states to be answerable. Towards this objective, we first introduce a novel Prompt-Generate-Evaluate (PGE) scheme that wraps around an LLM's output to create a dataset of unique situational queries, corresponding consensus object information, and predicted answers. PGE maintains uniqueness among the generated queries, using multiple forms of semantic similarity. We validate the generated dataset via a large scale user-study conducted on M-Turk, and introduce it as S-EQA, the first dataset tackling EQA with situational queries. Our user study establishes the authenticity of S-EQA with a high 97.26% of the generated queries being deemed answerable, given the consensus object data. Conversely, we observe a low correlation of 46.2% on the LLM-predicted answers to human-evaluated ones; indicating the LLM's poor capability in directly answering situational queries, while establishing S-EQA's usability in providing a human-validated consensus for an indirect solution. We evaluate S-EQA via Visual Question Answering (VQA) on VirtualHome, which unlike other simulators, contains several objects with modifiable states that also visually appear different upon modification -- enabling us to set a quantitative benchmark for S-EQA. To the best of our knowledge, this is the first work to introduce EQA with situational queries, and also the first to use a generative approach for query creation.
"Don't forget to put the milk back!" Dataset for Enabling Embodied Agents to Detect Anomalous Situations
Apr 12, 2024Home robots intend to make their users lives easier. Our work assists in this goal by enabling robots to inform their users of dangerous or unsanitary anomalies in their home. Some examples of these anomalies include the user leaving their milk out, forgetting to turn off the stove, or leaving poison accessible to children. To move towards enabling home robots with these abilities, we have created a new dataset, which we call SafetyDetect. The SafetyDetect dataset consists of 1000 anomalous home scenes, each of which contains unsafe or unsanitary situations for an agent to detect. Our approach utilizes large language models (LLMs) alongside both a graph representation of the scene and the relationships between the objects in the scene. Our key insight is that this connected scene graph and the object relationships it encodes enables the LLM to better reason about the scene -- especially as it relates to detecting dangerous or unsanitary situations. Our most promising approach utilizes GPT-4 and pursues a categorization technique where object relations from the scene graph are classified as normal, dangerous, unsanitary, or dangerous for children. This method is able to correctly identify over 90% of anomalous scenarios in the SafetyDetect Dataset. Additionally, we conduct real world experiments on a ClearPath TurtleBot where we generate a scene graph from visuals of the real world scene, and run our approach with no modification. This setup resulted in little performance loss. The SafetyDetect Dataset and code will be released to the public upon this papers publication.
Dialogue with Robots: Proposals for Broadening Participation and Research in the SLIVAR Community
Apr 01, 2024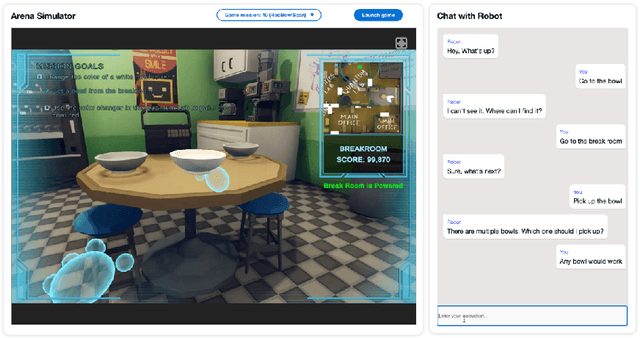
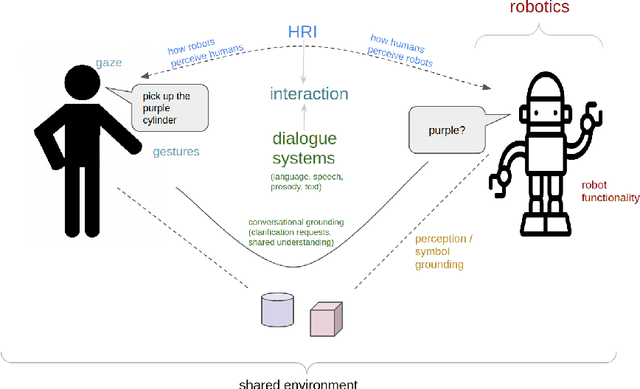
The ability to interact with machines using natural human language is becoming not just commonplace, but expected. The next step is not just text interfaces, but speech interfaces and not just with computers, but with all machines including robots. In this paper, we chronicle the recent history of this growing field of spoken dialogue with robots and offer the community three proposals, the first focused on education, the second on benchmarks, and the third on the modeling of language when it comes to spoken interaction with robots. The three proposals should act as white papers for any researcher to take and build upon.
Mastering Robot Manipulation with Multimodal Prompts through Pretraining and Multi-task Fine-tuning
Oct 14, 2023



Prompt-based learning has been demonstrated as a compelling paradigm contributing to large language models' tremendous success (LLMs). Inspired by their success in language tasks, existing research has leveraged LLMs in embodied instruction following and task planning. However, not much attention has been paid to embodied tasks with multimodal prompts, combining vision signals with text descriptions. This type of task poses a major challenge to robots' capability to understand the interconnection and complementarity between vision and language signals. In this work, we introduce an effective framework that learns a policy to perform robot manipulation with multimodal prompts from multi-task expert trajectories. Our methods consist of a two-stage training pipeline that performs inverse dynamics pretraining and multi-task finetuning. To facilitate multimodal understanding, we design our multimodal prompt encoder by augmenting a pretrained LM with a residual connection to the visual input and model the dependencies among action dimensions. Empirically, we evaluate the efficacy of our method on the VIMA-BENCH and establish a new state-of-the-art (10% improvement in success rate). Moreover, we demonstrate that our model exhibits remarkable in-context learning ability.
Alexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
Alexa Arena: A User-Centric Interactive Platform for Embodied AI
Mar 02, 2023



We introduce Alexa Arena, a user-centric simulation platform for Embodied AI (EAI) research. Alexa Arena provides a variety of multi-room layouts and interactable objects, for the creation of human-robot interaction (HRI) missions. With user-friendly graphics and control mechanisms, Alexa Arena supports the development of gamified robotic tasks readily accessible to general human users, thus opening a new venue for high-efficiency HRI data collection and EAI system evaluation. Along with the platform, we introduce a dialog-enabled instruction-following benchmark and provide baseline results for it. We make Alexa Arena publicly available to facilitate research in building generalizable and assistive embodied agents.
Improving Open-Domain Dialogue Evaluation with a Causal Inference Model
Jan 31, 2023Effective evaluation methods remain a significant challenge for research on open-domain conversational dialogue systems. Explicit satisfaction ratings can be elicited from users, but users often do not provide ratings when asked, and those they give can be highly subjective. Post-hoc ratings by experts are an alternative, but these can be both expensive and complex to collect. Here, we explore the creation of automated methods for predicting both expert and user ratings of open-domain dialogues. We compare four different approaches. First, we train a baseline model using an end-to-end transformer to predict ratings directly from the raw dialogue text. The other three methods are variants of a two-stage approach in which we first extract interpretable features at the turn level that capture, among other aspects, user dialogue behaviors indicating contradiction, repetition, disinterest, compliments, or criticism. We project these features to the dialogue level and train a dialogue-level MLP regression model, a dialogue-level LSTM, and a novel causal inference model called counterfactual-LSTM (CF-LSTM) to predict ratings. The proposed CF-LSTM is a sequential model over turn-level features which predicts ratings using multiple regressors depending on hypotheses derived from the turn-level features. As a causal inference model, CF-LSTM aims to learn the underlying causes of a specific event, such as a low rating. We also bin the user ratings and perform classification experiments with all four models. In evaluation experiments on conversational data from the Alexa Prize SocialBot, we show that the CF-LSTM achieves the best performance for predicting dialogue ratings and classification.
GIVL: Improving Geographical Inclusivity of Vision-Language Models with Pre-Training Methods
Jan 05, 2023

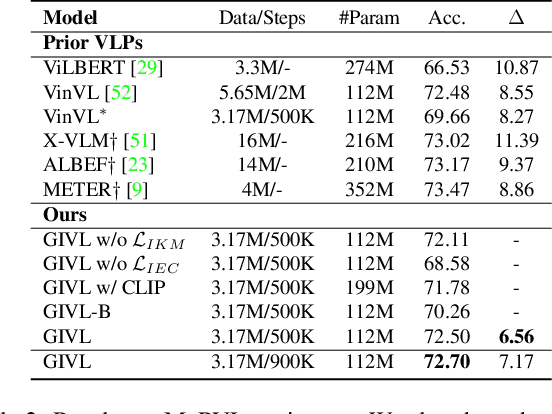

A key goal for the advancement of AI is to develop technologies that serve the needs not just of one group but of all communities regardless of their geographical region. In fact, a significant proportion of knowledge is locally shared by people from certain regions but may not apply equally in other regions because of cultural differences. If a model is unaware of regional characteristics, it may lead to performance disparity across regions and result in bias against underrepresented groups. We propose GIVL, a Geographically Inclusive Vision-and-Language Pre-trained model. There are two attributes of geo-diverse visual concepts which can help to learn geo-diverse knowledge: 1) concepts under similar categories have unique knowledge and visual characteristics, 2) concepts with similar visual features may fall in completely different categories. Motivated by the attributes, we design new pre-training objectives Image Knowledge Matching (IKM) and Image Edit Checking (IEC) to pre-train GIVL. Compared with similar-size models pre-trained with similar scale of data, GIVL achieves state-of-the-art (SOTA) and more balanced performance on geo-diverse V&L tasks.
Alexa, Let's Work Together: Introducing the First Alexa Prize TaskBot Challenge on Conversational Task Assistance
Sep 13, 2022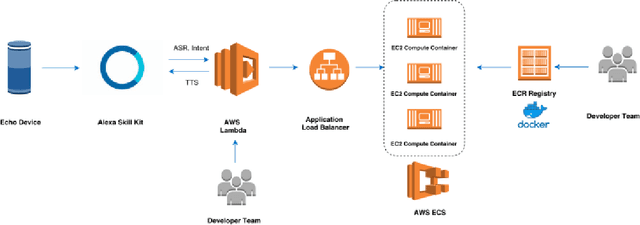
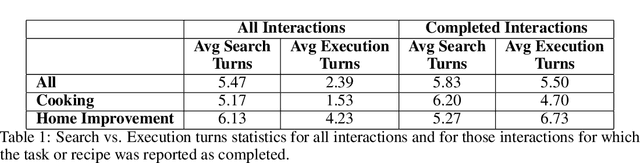
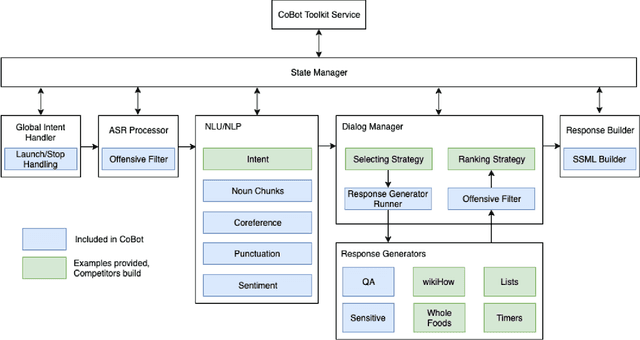

Since its inception in 2016, the Alexa Prize program has enabled hundreds of university students to explore and compete to develop conversational agents through the SocialBot Grand Challenge. The goal of the challenge is to build agents capable of conversing coherently and engagingly with humans on popular topics for 20 minutes, while achieving an average rating of at least 4.0/5.0. However, as conversational agents attempt to assist users with increasingly complex tasks, new conversational AI techniques and evaluation platforms are needed. The Alexa Prize TaskBot challenge, established in 2021, builds on the success of the SocialBot challenge by introducing the requirements of interactively assisting humans with real-world Cooking and Do-It-Yourself tasks, while making use of both voice and visual modalities. This challenge requires the TaskBots to identify and understand the user's need, identify and integrate task and domain knowledge into the interaction, and develop new ways of engaging the user without distracting them from the task at hand, among other challenges. This paper provides an overview of the TaskBot challenge, describes the infrastructure support provided to the teams with the CoBot Toolkit, and summarizes the approaches the participating teams took to overcome the research challenges. Finally, it analyzes the performance of the competing TaskBots during the first year of the competition.