 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Linguistic Priors in Measuring Compositional Generalization of Vision-Language Models
Oct 04, 2023
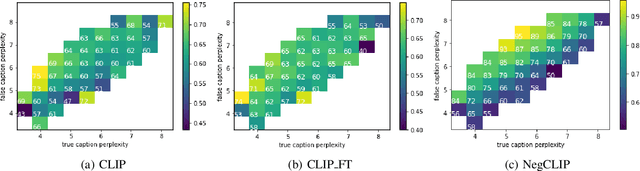


Compositionality is a common property in many modalities including natural languages and images, but the compositional generalization of multi-modal models is not well-understood. In this paper, we identify two sources of visual-linguistic compositionality: linguistic priors and the interplay between images and texts. We show that current attempts to improve compositional generalization rely on linguistic priors rather than on information in the image. We also propose a new metric for compositionality without such linguistic priors.
Rapid Connectionist Speaker Adaptation
Nov 15, 2022We present SVCnet, a system for modelling speaker variability. Encoder Neural Networks specialized for each speech sound produce low dimensionality models of acoustical variation, and these models are further combined into an overall model of voice variability. A training procedure is described which minimizes the dependence of this model on which sounds have been uttered. Using the trained model (SVCnet) and a brief, unconstrained sample of a new speaker's voice, the system produces a Speaker Voice Code that can be used to adapt a recognition system to the new speaker without retraining. A system which combines SVCnet with an MS-TDNN recognizer is described
* 6 Figures, Two Tables, ICASSP-92
Deep Clustering with Measure Propagation
Apr 26, 2021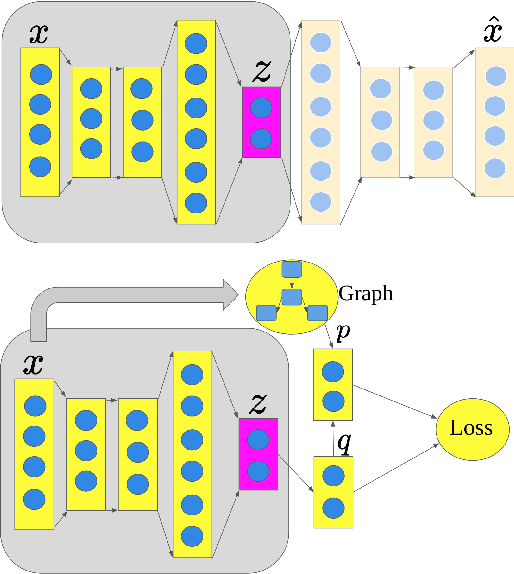

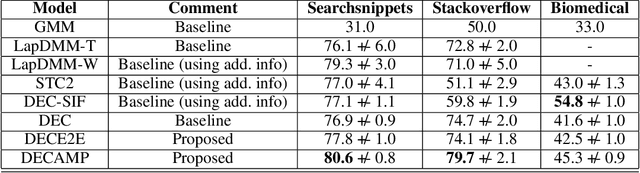
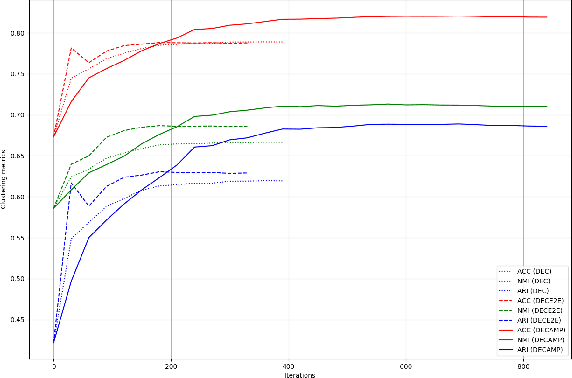
Deep models have improved state-of-the-art for both supervised and unsupervised learning. For example, deep embedded clustering (DEC) has greatly improved the unsupervised clustering performance, by using stacked autoencoders for representation learning. However, one weakness of deep modeling is that the local neighborhood structure in the original space is not necessarily preserved in the latent space. To preserve local geometry, various methods have been proposed in the supervised and semi-supervised learning literature (e.g., spectral clustering and label propagation) using graph Laplacian regularization. In this paper, we combine the strength of deep representation learning with measure propagation (MP), a KL-divergence based graph regularization method originally used in the semi-supervised scenario. The main assumption of MP is that if two data points are close in the original space, they are likely to belong to the same class, measured by KL-divergence of class membership distribution. By taking the same assumption in the unsupervised learning scenario, we propose our Deep Embedded Clustering Aided by Measure Propagation (DECAMP) model. We evaluate DECAMP on short text clustering tasks. On three public datasets, DECAMP performs competitively with other state-of-the-art baselines, including baselines using additional data to generate word embeddings used in the clustering process. As an example, on the Stackoverflow dataset, DECAMP achieved a clustering accuracy of 79%, which is about 5% higher than all existing baselines. These empirical results suggest that DECAMP is a very effective method for unsupervised learning.
Learning to Adapt by Minimizing Discrepancy
Nov 30, 2017

We explore whether useful temporal neural generative models can be learned from sequential data without back-propagation through time. We investigate the viability of a more neurocognitively-grounded approach in the context of unsupervised generative modeling of sequences. Specifically, we build on the concept of predictive coding, which has gained influence in cognitive science, in a neural framework. To do so we develop a novel architecture, the Temporal Neural Coding Network, and its learning algorithm, Discrepancy Reduction. The underlying directed generative model is fully recurrent, meaning that it employs structural feedback connections and temporal feedback connections, yielding information propagation cycles that create local learning signals. This facilitates a unified bottom-up and top-down approach for information transfer inside the architecture. Our proposed algorithm shows promise on the bouncing balls generative modeling problem. Further experiments could be conducted to explore the strengths and weaknesses of our approach.
Accelerated Parallel Optimization Methods for Large Scale Machine Learning
Nov 25, 2014The growing amount of high dimensional data in different machine learning applications requires more efficient and scalable optimization algorithms. In this work, we consider combining two techniques, parallelism and Nesterov's acceleration, to design faster algorithms for L1-regularized loss. We first simplify BOOM, a variant of gradient descent, and study it in a unified framework, which allows us to not only propose a refined measurement of sparsity to improve BOOM, but also show that BOOM is provably slower than FISTA. Moving on to parallel coordinate descent methods, we then propose an efficient accelerated version of Shotgun, improving the convergence rate from $O(1/t)$ to $O(1/t^2)$. Our algorithm enjoys a concise form and analysis compared to previous work, and also allows one to study several connected work in a unified way.
Efficient Multiclass Implementations of L1-Regularized Maximum Entropy
Jun 29, 2005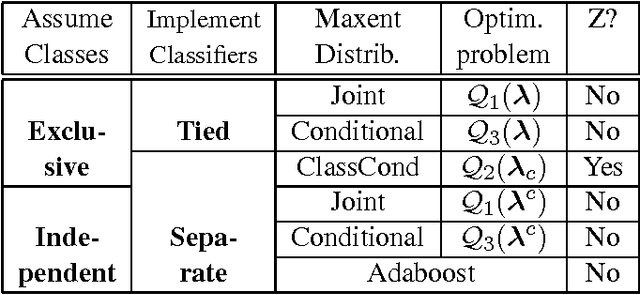
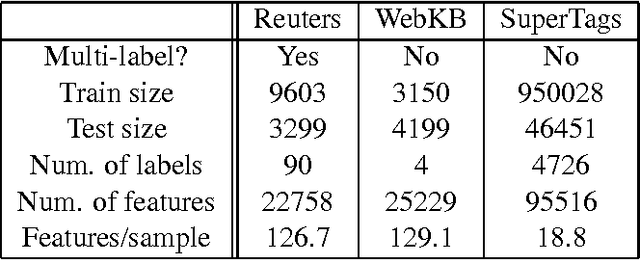
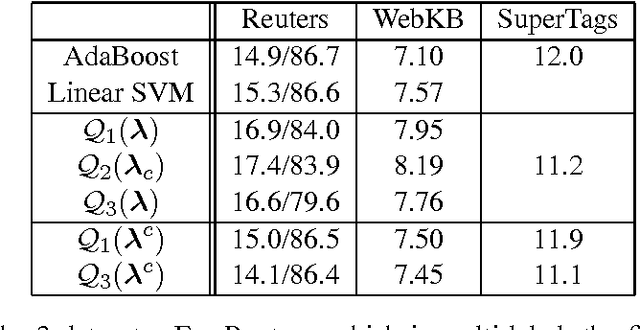
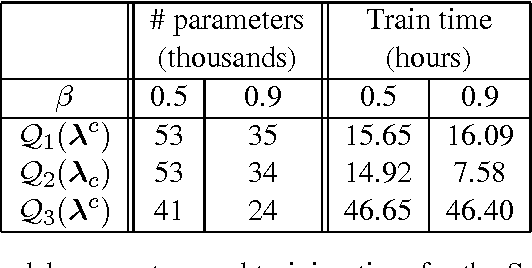
This paper discusses the application of L1-regularized maximum entropy modeling or SL1-Max [9] to multiclass categorization problems. A new modification to the SL1-Max fast sequential learning algorithm is proposed to handle conditional distributions. Furthermore, unlike most previous studies, the present research goes beyond a single type of conditional distribution. It describes and compares a variety of modeling assumptions about the class distribution (independent or exclusive) and various types of joint or conditional distributions. It results in a new methodology for combining binary regularized classifiers to achieve multiclass categorization. In this context, Maximum Entropy can be considered as a generic and efficient regularized classification tool that matches or outperforms the state-of-the art represented by AdaBoost and SVMs.