 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentMath: Empowering Mathematical Reasoning for Large Language Models via Tool-Augmented Agent
Dec 23, 2025Large Reasoning Models (LRMs) like o3 and DeepSeek-R1 have achieved remarkable progress in natural language reasoning with long chain-of-thought. However, they remain computationally inefficient and struggle with accuracy when solving problems requiring complex mathematical operations. In this work, we present AgentMath, an agent framework that seamlessly integrates language models' reasoning capabilities with code interpreters' computational precision to efficiently tackle complex mathematical problems. Our approach introduces three key innovations: (1) An automated method that converts natural language chain-of-thought into structured tool-augmented trajectories, generating high-quality supervised fine-tuning (SFT) data to alleviate data scarcity; (2) A novel agentic reinforcement learning (RL) paradigm that dynamically interleaves natural language generation with real-time code execution. This enables models to autonomously learn optimal tool-use strategies through multi-round interactive feedback, while fostering emergent capabilities in code refinement and error correction; (3) An efficient training system incorporating innovative techniques, including request-level asynchronous rollout scheduling, agentic partial rollout, and prefix-aware weighted load balancing, achieving 4-5x speedup and making efficient RL training feasible on ultra-long sequences with scenarios with massive tool calls.Extensive evaluations show that AgentMath achieves state-of-the-art performance on challenging mathematical competition benchmarks including AIME24, AIME25, and HMMT25. Specifically, AgentMath-30B-A3B attains 90.6%, 86.4%, and 73.8% accuracy respectively, achieving advanced capabilities.These results validate the effectiveness of our approach and pave the way for building more sophisticated and scalable mathematical reasoning agents.
Efficient Swap Multicalibration of Elicitable Properties
Nov 07, 2025
Multicalibration [HJKRR18] is an algorithmic fairness perspective that demands that the predictions of a predictor are correct conditional on themselves and membership in a collection of potentially overlapping subgroups of a population. The work of [NR23] established a surprising connection between multicalibration for an arbitrary property $\Gamma$ (e.g., mean or median) and property elicitation: a property $\Gamma$ can be multicalibrated if and only if it is elicitable, where elicitability is the notion that the true property value of a distribution can be obtained by solving a regression problem over the distribution. In the online setting, [NR23] proposed an inefficient algorithm that achieves $\sqrt T$ $\ell_2$-multicalibration error for a hypothesis class of group membership functions and an elicitable property $\Gamma$, after $T$ rounds of interaction between a forecaster and adversary. In this paper, we generalize multicalibration for an elicitable property $\Gamma$ from group membership functions to arbitrary bounded hypothesis classes and introduce a stronger notion -- swap multicalibration, following [GKR23]. Subsequently, we propose an oracle-efficient algorithm which, when given access to an online agnostic learner, achieves $T^{1/(r+1)}$ $\ell_r$-swap multicalibration error with high probability (for $r\ge2$) for a hypothesis class with bounded sequential Rademacher complexity and an elicitable property $\Gamma$. For the special case of $r=2$, this implies an oracle-efficient algorithm that achieves $T^{1/3}$ $\ell_2$-swap multicalibration error, which significantly improves on the previously established bounds for the problem [NR23, GMS25, LSS25a], and completely resolves an open question raised in [GJRR24] on the possibility of an oracle-efficient algorithm that achieves $\sqrt{T}$ $\ell_2$-mean multicalibration error by answering it in a strongly affirmative sense.
Reinforcement Learning from Adversarial Preferences in Tabular MDPs
Jul 15, 2025We introduce a new framework of episodic tabular Markov decision processes (MDPs) with adversarial preferences, which we refer to as preference-based MDPs (PbMDPs). Unlike standard episodic MDPs with adversarial losses, where the numerical value of the loss is directly observed, in PbMDPs the learner instead observes preferences between two candidate arms, which represent the choices being compared. In this work, we focus specifically on the setting where the reward functions are determined by Borda scores. We begin by establishing a regret lower bound for PbMDPs with Borda scores. As a preliminary step, we present a simple instance to prove a lower bound of $\Omega(\sqrt{HSAT})$ for episodic MDPs with adversarial losses, where $H$ is the number of steps per episode, $S$ is the number of states, $A$ is the number of actions, and $T$ is the number of episodes. Leveraging this construction, we then derive a regret lower bound of $\Omega( (H^2 S K)^{1/3} T^{2/3} )$ for PbMDPs with Borda scores, where $K$ is the number of arms. Next, we develop algorithms that achieve a regret bound of order $T^{2/3}$. We first propose a global optimization approach based on online linear optimization over the set of all occupancy measures, achieving a regret bound of $\tilde{O}((H^2 S^2 K)^{1/3} T^{2/3} )$ under known transitions. However, this approach suffers from suboptimal dependence on the potentially large number of states $S$ and computational inefficiency. To address this, we propose a policy optimization algorithm whose regret is roughly bounded by $\tilde{O}( (H^6 S K^5)^{1/3} T^{2/3} )$ under known transitions, and further extend the result to the unknown-transition setting.
Improved Bounds for Swap Multicalibration and Swap Omniprediction
May 28, 2025In this paper, we consider the related problems of multicalibration -- a multigroup fairness notion and omniprediction -- a simultaneous loss minimization paradigm, both in the distributional and online settings. The recent work of Garg et al. (2024) raised the open problem of whether it is possible to efficiently achieve $O(\sqrt{T})$ $\ell_{2}$-multicalibration error against bounded linear functions. In this paper, we answer this question in a strongly affirmative sense. We propose an efficient algorithm that achieves $O(T^{\frac{1}{3}})$ $\ell_{2}$-swap multicalibration error (both in high probability and expectation). On propagating this bound onward, we obtain significantly improved rates for $\ell_{1}$-swap multicalibration and swap omniprediction for a loss class of convex Lipschitz functions. In particular, we show that our algorithm achieves $O(T^{\frac{2}{3}})$ $\ell_{1}$-swap multicalibration and swap omniprediction errors, thereby improving upon the previous best-known bound of $O(T^{\frac{7}{8}})$. As a consequence of our improved online results, we further obtain several improved sample complexity rates in the distributional setting. In particular, we establish a $O(\varepsilon ^ {-3})$ sample complexity of efficiently learning an $\varepsilon$-swap omnipredictor for the class of convex and Lipschitz functions, $O(\varepsilon ^{-2.5})$ sample complexity of efficiently learning an $\varepsilon$-swap agnostic learner for the squared loss, and $O(\varepsilon ^ {-5}), O(\varepsilon ^ {-2.5})$ sample complexities of learning $\ell_{1}, \ell_{2}$-swap multicalibrated predictors against linear functions, all of which significantly improve on the previous best-known bounds.
Improved Regret and Contextual Linear Extension for Pandora's Box and Prophet Inequality
May 24, 2025We study the Pandora's Box problem in an online learning setting with semi-bandit feedback. In each round, the learner sequentially pays to open up to $n$ boxes with unknown reward distributions, observes rewards upon opening, and decides when to stop. The utility of the learner is the maximum observed reward minus the cumulative cost of opened boxes, and the goal is to minimize regret defined as the gap between the cumulative expected utility and that of the optimal policy. We propose a new algorithm that achieves $\widetilde{O}(\sqrt{nT})$ regret after $T$ rounds, which improves the $\widetilde{O}(n\sqrt{T})$ bound of Agarwal et al. [2024] and matches the known lower bound up to logarithmic factors. To better capture real-life applications, we then extend our results to a natural but challenging contextual linear setting, where each box's expected reward is linear in some known but time-varying $d$-dimensional context and the noise distribution is fixed over time. We design an algorithm that learns both the linear function and the noise distributions, achieving $\widetilde{O}(nd\sqrt{T})$ regret. Finally, we show that our techniques also apply to the online Prophet Inequality problem, where the learner must decide immediately whether or not to accept a revealed reward. In both non-contextual and contextual settings, our approach achieves similar improvements and regret bounds.
Comparator-Adaptive $Φ$-Regret: Improved Bounds, Simpler Algorithms, and Applications to Games
May 22, 2025In the classic expert problem, $\Phi$-regret measures the gap between the learner's total loss and that achieved by applying the best action transformation $\phi \in \Phi$. A recent work by Lu et al., [2025] introduces an adaptive algorithm whose regret against a comparator $\phi$ depends on a certain sparsity-based complexity measure of $\phi$, (almost) recovering and interpolating optimal bounds for standard regret notions such as external, internal, and swap regret. In this work, we propose a general idea to achieve an even better comparator-adaptive $\Phi$-regret bound via much simpler algorithms compared to Lu et al., [2025]. Specifically, we discover a prior distribution over all possible binary transformations and show that it suffices to achieve prior-dependent regret against these transformations. Then, we propose two concrete and efficient algorithms to achieve so, where the first one learns over multiple copies of a prior-aware variant of the Kernelized MWU algorithm of Farina et al., [2022], and the second one learns over multiple copies of a prior-aware variant of the BM-reduction [Blum and Mansour, 2007]. To further showcase the power of our methods and the advantages over Lu et al., [2025] besides the simplicity and better regret bounds, we also show that our second approach can be extended to the game setting to achieve accelerated and adaptive convergence rate to $\Phi$-equilibria for a class of general-sum games. When specified to the special case of correlated equilibria, our bound improves over the existing ones from Anagnostides et al., [2022a,b]
Hunyuan-TurboS: Advancing Large Language Models through Mamba-Transformer Synergy and Adaptive Chain-of-Thought
May 21, 2025As Large Language Models (LLMs) rapidly advance, we introduce Hunyuan-TurboS, a novel large hybrid Transformer-Mamba Mixture of Experts (MoE) model. It synergistically combines Mamba's long-sequence processing efficiency with Transformer's superior contextual understanding. Hunyuan-TurboS features an adaptive long-short chain-of-thought (CoT) mechanism, dynamically switching between rapid responses for simple queries and deep "thinking" modes for complex problems, optimizing computational resources. Architecturally, this 56B activated (560B total) parameter model employs 128 layers (Mamba2, Attention, FFN) with an innovative AMF/MF block pattern. Faster Mamba2 ensures linear complexity, Grouped-Query Attention minimizes KV cache, and FFNs use an MoE structure. Pre-trained on 16T high-quality tokens, it supports a 256K context length and is the first industry-deployed large-scale Mamba model. Our comprehensive post-training strategy enhances capabilities via Supervised Fine-Tuning (3M instructions), a novel Adaptive Long-short CoT Fusion method, Multi-round Deliberation Learning for iterative improvement, and a two-stage Large-scale Reinforcement Learning process targeting STEM and general instruction-following. Evaluations show strong performance: overall top 7 rank on LMSYS Chatbot Arena with a score of 1356, outperforming leading models like Gemini-2.0-Flash-001 (1352) and o4-mini-2025-04-16 (1345). TurboS also achieves an average of 77.9% across 23 automated benchmarks. Hunyuan-TurboS balances high performance and efficiency, offering substantial capabilities at lower inference costs than many reasoning models, establishing a new paradigm for efficient large-scale pre-trained models.
On Separation Between Best-Iterate, Random-Iterate, and Last-Iterate Convergence of Learning in Games
Mar 04, 2025Non-ergodic convergence of learning dynamics in games is widely studied recently because of its importance in both theory and practice. Recent work (Cai et al., 2024) showed that a broad class of learning dynamics, including Optimistic Multiplicative Weights Update (OMWU), can exhibit arbitrarily slow last-iterate convergence even in simple $2 \times 2$ matrix games, despite many of these dynamics being known to converge asymptotically in the last iterate. It remains unclear, however, whether these algorithms achieve fast non-ergodic convergence under weaker criteria, such as best-iterate convergence. We show that for $2\times 2$ matrix games, OMWU achieves an $O(T^{-1/6})$ best-iterate convergence rate, in stark contrast to its slow last-iterate convergence in the same class of games. Furthermore, we establish a lower bound showing that OMWU does not achieve any polynomial random-iterate convergence rate, measured by the expected duality gaps across all iterates. This result challenges the conventional wisdom that random-iterate convergence is essentially equivalent to best-iterate convergence, with the former often used as a proxy for establishing the latter. Our analysis uncovers a new connection to dynamic regret and presents a novel two-phase approach to best-iterate convergence, which could be of independent interest.
Instance-Dependent Regret Bounds for Learning Two-Player Zero-Sum Games with Bandit Feedback
Feb 24, 2025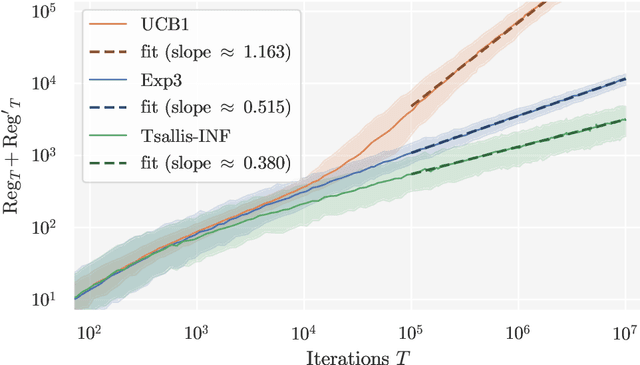
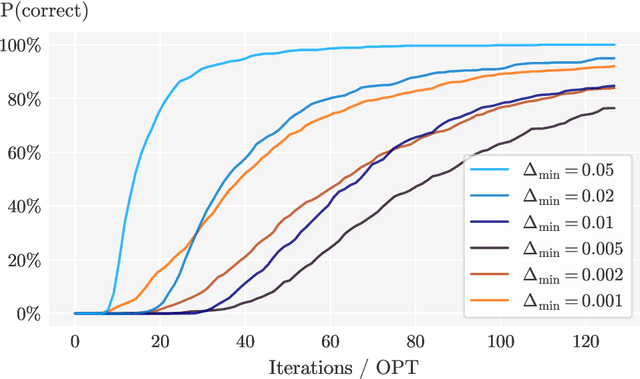
No-regret self-play learning dynamics have become one of the premier ways to solve large-scale games in practice. Accelerating their convergence via improving the regret of the players over the naive $O(\sqrt{T})$ bound after $T$ rounds has been extensively studied in recent years, but almost all studies assume access to exact gradient feedback. We address the question of whether acceleration is possible under bandit feedback only and provide an affirmative answer for two-player zero-sum normal-form games. Specifically, we show that if both players apply the Tsallis-INF algorithm of Zimmert and Seldin (2018, arXiv:1807.07623), then their regret is at most $O(c_1 \log T + \sqrt{c_2 T})$, where $c_1$ and $c_2$ are game-dependent constants that characterize the difficulty of learning -- $c_1$ resembles the complexity of learning a stochastic multi-armed bandit instance and depends inversely on some gap measures, while $c_2$ can be much smaller than the number of actions when the Nash equilibria have a small support or are close to the boundary. In particular, for the case when a pure strategy Nash equilibrium exists, $c_2$ becomes zero, leading to an optimal instance-dependent regret bound as we show. We additionally prove that in this case, our algorithm also enjoys last-iterate convergence and can identify the pure strategy Nash equilibrium with near-optimal sample complexity.
Simultaneous Swap Regret Minimization via KL-Calibration
Feb 23, 2025Calibration is a fundamental concept that aims at ensuring the reliability of probabilistic predictions by aligning them with real-world outcomes. There is a surge of studies on new calibration measures that are easier to optimize compared to the classical $\ell_1$-Calibration while still having strong implications for downstream applications. One recent such example is the work by Fishelson et al. (2025) who show that it is possible to achieve $O(T^{1/3})$ pseudo $\ell_2$-Calibration error via minimizing pseudo swap regret of the squared loss, which in fact implies the same bound for all bounded proper losses with a smooth univariate form. In this work, we significantly generalize their result in the following ways: (a) in addition to smooth univariate forms, our algorithm also simultaneously achieves $O(T^{1/3})$ swap regret for any proper loss with a twice continuously differentiable univariate form (such as Tsallis entropy); (b) our bounds hold not only for pseudo swap regret that measures losses using the forecaster's distributions on predictions, but also hold for the actual swap regret that measures losses using the forecaster's actual realized predictions. We achieve so by introducing a new stronger notion of calibration called (pseudo) KL-Calibration, which we show is equivalent to the (pseudo) swap regret for log loss. We prove that there exists an algorithm that achieves $O(T^{1/3})$ KL-Calibration error and provide an explicit algorithm that achieves $O(T^{1/3})$ pseudo KL-Calibration error. Moreover, we show that the same algorithm achieves $O(T^{1/3}(\log T)^{-1/3}\log(T/\delta))$ swap regret w.p. $\ge 1-\delta$ for any proper loss with a smooth univariate form, which implies $O(T^{1/3})$ $\ell_2$-Calibration error. A technical contribution of our work is a new randomized rounding procedure and a non-uniform discretization scheme to minimize the swap regret for log loss.