 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Bertrand Paradox via Equilibrium Analysis of No-regret Learners
Feb 25, 2026We study the discrete Bertrand pricing game with a non-increasing demand function. The game has $n \ge 2$ players who simultaneously choose prices from the set $\{1/k, 2/k, \ldots, 1\}$, where $k\in\mathbb{N}$. The player who sets the lowest price captures the entire demand; if multiple players tie for the lowest price, they split the demand equally. We study the Bertrand paradox, where classical theory predicts low prices, yet real markets often sustain high prices. To understand this gap, we analyze a repeated-game model in which firms set prices using no-regret learners. Our goal is to characterize the equilibrium outcomes that can arise under different no-regret learning guarantees. We are particularly interested in questions such as whether no-external-regret learners can converge to undesirable high-price outcomes, and how stronger guarantees such as no-swap regret shape the emergence of competitive low-price behavior. We address these and related questions through a theoretical analysis, complemented by experiments that support the theory and reveal surprising phenomena for no-swap regret learners.
Online Learning for Uninformed Markov Games: Empirical Nash-Value Regret and Non-Stationarity Adaptation
Feb 06, 2026We study online learning in two-player uninformed Markov games, where the opponent's actions and policies are unobserved. In this setting, Tian et al. (2021) show that achieving no-external-regret is impossible without incurring an exponential dependence on the episode length $H$. They then turn to the weaker notion of Nash-value regret and propose a V-learning algorithm with regret $O(K^{2/3})$ after $K$ episodes. However, their algorithm and guarantee do not adapt to the difficulty of the problem: even in the case where the opponent follows a fixed policy and thus $O(\sqrt{K})$ external regret is well-known to be achievable, their result is still the worse rate $O(K^{2/3})$ on a weaker metric. In this work, we fully address both limitations. First, we introduce empirical Nash-value regret, a new regret notion that is strictly stronger than Nash-value regret and naturally reduces to external regret when the opponent follows a fixed policy. Moreover, under this new metric, we propose a parameter-free algorithm that achieves an $O(\min \{\sqrt{K} + (CK)^{1/3},\sqrt{LK}\})$ regret bound, where $C$ quantifies the variance of the opponent's policies and $L$ denotes the number of policy switches (both at most $O(K)$). Therefore, our results not only recover the two extremes -- $O(\sqrt{K})$ external regret when the opponent is fixed and $O(K^{2/3})$ Nash-value regret in the worst case -- but also smoothly interpolate between these extremes by automatically adapting to the opponent's non-stationarity. We achieve so by first providing a new analysis of the epoch-based V-learning algorithm by Mao et al. (2022), establishing an $O(ηC + \sqrt{K/η})$ regret bound, where $η$ is the epoch incremental factor. Next, we show how to adaptively restart this algorithm with an appropriate $η$ in response to the potential non-stationarity of the opponent, eventually achieving our final results.
Learning to Incentivize in Repeated Principal-Agent Problems with Adversarial Agent Arrivals
May 29, 2025We initiate the study of a repeated principal-agent problem over a finite horizon $T$, where a principal sequentially interacts with $K\geq 2$ types of agents arriving in an adversarial order. At each round, the principal strategically chooses one of the $N$ arms to incentivize for an arriving agent of unknown type. The agent then chooses an arm based on its own utility and the provided incentive, and the principal receives a corresponding reward. The objective is to minimize regret against the best incentive in hindsight. Without prior knowledge of agent behavior, we show that the problem becomes intractable, leading to linear regret. We analyze two key settings where sublinear regret is achievable. In the first setting, the principal knows the arm each agent type would select greedily for any given incentive. Under this setting, we propose an algorithm that achieves a regret bound of $O(\min\{\sqrt{KT\log N},K\sqrt{T}\})$ and provide a matching lower bound up to a $\log K$ factor. In the second setting, an agent's response varies smoothly with the incentive and is governed by a Lipschitz constant $L\geq 1$. Under this setting, we show that there is an algorithm with a regret bound of $\tilde{O}((LN)^{1/3}T^{2/3})$ and establish a matching lower bound up to logarithmic factors. Finally, we extend our algorithmic results for both settings by allowing the principal to incentivize multiple arms simultaneously in each round.
Improved Regret and Contextual Linear Extension for Pandora's Box and Prophet Inequality
May 24, 2025We study the Pandora's Box problem in an online learning setting with semi-bandit feedback. In each round, the learner sequentially pays to open up to $n$ boxes with unknown reward distributions, observes rewards upon opening, and decides when to stop. The utility of the learner is the maximum observed reward minus the cumulative cost of opened boxes, and the goal is to minimize regret defined as the gap between the cumulative expected utility and that of the optimal policy. We propose a new algorithm that achieves $\widetilde{O}(\sqrt{nT})$ regret after $T$ rounds, which improves the $\widetilde{O}(n\sqrt{T})$ bound of Agarwal et al. [2024] and matches the known lower bound up to logarithmic factors. To better capture real-life applications, we then extend our results to a natural but challenging contextual linear setting, where each box's expected reward is linear in some known but time-varying $d$-dimensional context and the noise distribution is fixed over time. We design an algorithm that learns both the linear function and the noise distributions, achieving $\widetilde{O}(nd\sqrt{T})$ regret. Finally, we show that our techniques also apply to the online Prophet Inequality problem, where the learner must decide immediately whether or not to accept a revealed reward. In both non-contextual and contextual settings, our approach achieves similar improvements and regret bounds.
Principal-Agent Bandit Games with Self-Interested and Exploratory Learning Agents
Dec 20, 2024We study the repeated principal-agent bandit game, where the principal indirectly interacts with the unknown environment by proposing incentives for the agent to play arms. Most existing work assumes the agent has full knowledge of the reward means and always behaves greedily, but in many online marketplaces, the agent needs to learn the unknown environment and sometimes explore. Motivated by such settings, we model a self-interested learning agent with exploration behaviors who iteratively updates reward estimates and either selects an arm that maximizes the estimated reward plus incentive or explores arbitrarily with a certain probability. As a warm-up, we first consider a self-interested learning agent without exploration. We propose algorithms for both i.i.d. and linear reward settings with bandit feedback in a finite horizon $T$, achieving regret bounds of $\widetilde{O}(\sqrt{T})$ and $\widetilde{O}( T^{2/3} )$, respectively. Specifically, these algorithms are established upon a novel elimination framework coupled with newly-developed search algorithms which accommodate the uncertainty arising from the learning behavior of the agent. We then extend the framework to handle the exploratory learning agent and develop an algorithm to achieve a $\widetilde{O}(T^{2/3})$ regret bound in i.i.d. reward setup by enhancing the robustness of our elimination framework to the potential agent exploration. Finally, when reducing our agent behaviors to the one studied in (Dogan et al., 2023a), we propose an algorithm based on our robust framework, which achieves a $\widetilde{O}(\sqrt{T})$ regret bound, significantly improving upon their $\widetilde{O}(T^{11/12})$ bound.
ST-NeRP: Spatial-Temporal Neural Representation Learning with Prior Embedding for Patient-specific Imaging Study
Oct 25, 2024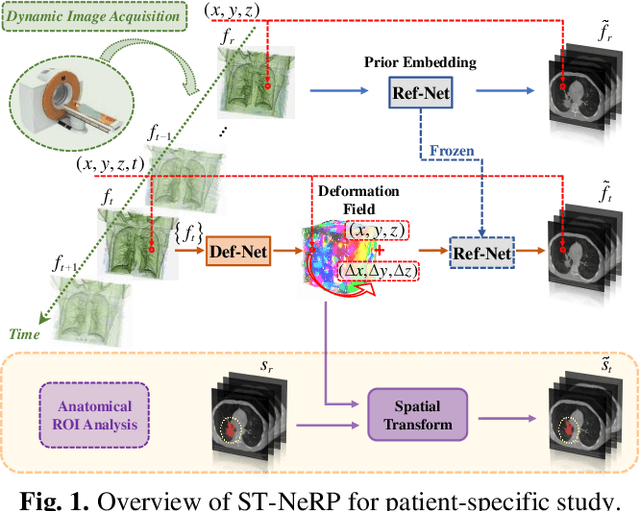
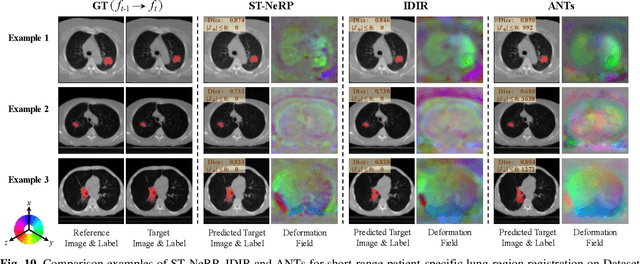
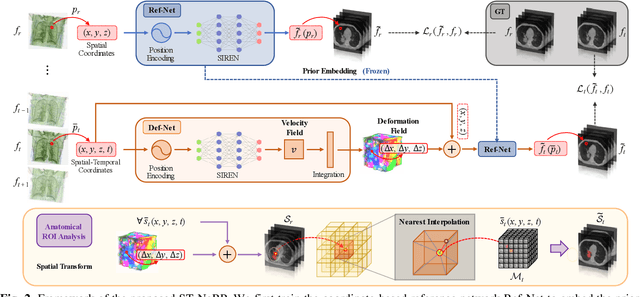
During and after a course of therapy, imaging is routinely used to monitor the disease progression and assess the treatment responses. Despite of its significance, reliably capturing and predicting the spatial-temporal anatomic changes from a sequence of patient-specific image series presents a considerable challenge. Thus, the development of a computational framework becomes highly desirable for a multitude of practical applications. In this context, we propose a strategy of Spatial-Temporal Neural Representation learning with Prior embedding (ST-NeRP) for patient-specific imaging study. Our strategy involves leveraging an Implicit Neural Representation (INR) network to encode the image at the reference time point into a prior embedding. Subsequently, a spatial-temporally continuous deformation function is learned through another INR network. This network is trained using the whole patient-specific image sequence, enabling the prediction of deformation fields at various target time points. The efficacy of the ST-NeRP model is demonstrated through its application to diverse sequential image series, including 4D CT and longitudinal CT datasets within thoracic and abdominal imaging. The proposed ST-NeRP model exhibits substantial potential in enabling the monitoring of anatomical changes within a patient throughout the therapeutic journey.
Achieving Near-Optimal Regret for Bandit Algorithms with Uniform Last-Iterate Guarantee
Feb 20, 2024Existing performance measures for bandit algorithms such as regret, PAC bounds, or uniform-PAC (Dann et al., 2017), typically evaluate the cumulative performance, while allowing the play of an arbitrarily bad arm at any finite time t. Such a behavior can be highly detrimental in high-stakes applications. This paper introduces a stronger performance measure, the uniform last-iterate (ULI) guarantee, capturing both cumulative and instantaneous performance of bandit algorithms. Specifically, ULI characterizes the instantaneous performance since it ensures that the per-round regret of the played arm is bounded by a function, monotonically decreasing w.r.t. (large) round t, preventing revisits to bad arms when sufficient samples are available. We demonstrate that a near-optimal ULI guarantee directly implies near-optimal cumulative performance across aforementioned performance measures. To examine the achievability of ULI in the finite arm setting, we first provide two positive results that some elimination-based algorithms and high-probability adversarial algorithms with stronger analysis or additional designs, can attain near-optimal ULI guarantees. Then, we also provide a negative result, indicating that optimistic algorithms cannot achieve a near-optimal ULI guarantee. Finally, we propose an efficient algorithm for linear bandits with infinitely many arms, which achieves the ULI guarantee, given access to an optimization oracle.
No-Regret Online Reinforcement Learning with Adversarial Losses and Transitions
May 30, 2023Existing online learning algorithms for adversarial Markov Decision Processes achieve ${O}(\sqrt{T})$ regret after $T$ rounds of interactions even if the loss functions are chosen arbitrarily by an adversary, with the caveat that the transition function has to be fixed. This is because it has been shown that adversarial transition functions make no-regret learning impossible. Despite such impossibility results, in this work, we develop algorithms that can handle both adversarial losses and adversarial transitions, with regret increasing smoothly in the degree of maliciousness of the adversary. More concretely, we first propose an algorithm that enjoys $\widetilde{{O}}(\sqrt{T} + C^{\textsf{P}})$ regret where $C^{\textsf{P}}$ measures how adversarial the transition functions are and can be at most ${O}(T)$. While this algorithm itself requires knowledge of $C^{\textsf{P}}$, we further develop a black-box reduction approach that removes this requirement. Moreover, we also show that further refinements of the algorithm not only maintains the same regret bound, but also simultaneously adapts to easier environments (where losses are generated in a certain stochastically constrained manner as in Jin et al. [2021]) and achieves $\widetilde{{O}}(U + \sqrt{UC^{\textsf{L}}} + C^{\textsf{P}})$ regret, where $U$ is some standard gap-dependent coefficient and $C^{\textsf{L}}$ is the amount of corruption on losses.
Improved Best-of-Both-Worlds Guarantees for Multi-Armed Bandits: FTRL with General Regularizers and Multiple Optimal Arms
Feb 27, 2023


We study the problem of designing adaptive multi-armed bandit algorithms that perform optimally in both the stochastic setting and the adversarial setting simultaneously (often known as a best-of-both-world guarantee). A line of recent works shows that when configured and analyzed properly, the Follow-the-Regularized-Leader (FTRL) algorithm, originally designed for the adversarial setting, can in fact optimally adapt to the stochastic setting as well. Such results, however, critically rely on an assumption that there exists one unique optimal arm. Recently, Ito (2021) took the first step to remove such an undesirable uniqueness assumption for one particular FTRL algorithm with the $\frac{1}{2}$-Tsallis entropy regularizer. In this work, we significantly improve and generalize this result, showing that uniqueness is unnecessary for FTRL with a broad family of regularizers and a new learning rate schedule. For some regularizers, our regret bounds also improve upon prior results even when uniqueness holds. We further provide an application of our results to the decoupled exploration and exploitation problem, demonstrating that our techniques are broadly applicable.
Cooperative Stochastic Multi-agent Multi-armed Bandits Robust to Adversarial Corruptions
Jun 08, 2021We study the problem of stochastic bandits with adversarial corruptions in the cooperative multi-agent setting, where $V$ agents interact with a common $K$-armed bandit problem, and each pair of agents can communicate with each other to expedite the learning process. In the problem, the rewards are independently sampled from distributions across all agents and rounds, but they may be corrupted by an adversary. Our goal is to minimize both the overall regret and communication cost across all agents. We first show that an additive term of corruption is unavoidable for any algorithm in this problem. Then, we propose a new algorithm that is agnostic to the level of corruption. Our algorithm not only achieves near-optimal regret in the stochastic setting, but also obtains a regret with an additive term of corruption in the corrupted setting, while maintaining efficient communication. The algorithm is also applicable for the single-agent corruption problem, and achieves a high probability regret that removes the multiplicative dependence of $K$ on corruption level. Our result of the single-agent case resolves an open question from Gupta et al. [2019].