 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs Online Linear Optimization Sufficient for Strategic Robustness?
Feb 12, 2026We consider bidding in repeated Bayesian first-price auctions. Bidding algorithms that achieve optimal regret have been extensively studied, but their strategic robustness to the seller's manipulation remains relatively underexplored. Bidding algorithms based on no-swap-regret algorithms achieve both desirable properties, but are suboptimal in terms of statistical and computational efficiency. In contrast, online gradient ascent is the only algorithm that achieves $O(\sqrt{TK})$ regret and strategic robustness [KSS24], where $T$ denotes the number of auctions and $K$ the number of bids. In this paper, we explore whether simple online linear optimization (OLO) algorithms suffice for bidding algorithms with both desirable properties. Our main result shows that sublinear linearized regret is sufficient for strategic robustness. Specifically, we construct simple black-box reductions that convert any OLO algorithm into a strategically robust no-regret bidding algorithm, in both known and unknown value distribution settings. For the known value distribution case, our reduction yields a bidding algorithm that achieves $O(\sqrt{T \log K})$ regret and strategic robustness (with exponential improvement on the $K$-dependence compared to [KSS24]). For the unknown value distribution case, our reduction gives a bidding algorithm with high-probability $O(\sqrt{T (\log K+\log(T/δ)})$ regret and strategic robustness, while removing the bounded density assumption made in [KSS24].
On the Complexity of Offline Reinforcement Learning with $Q^\star$-Approximation and Partial Coverage
Feb 12, 2026We study offline reinforcement learning under $Q^\star$-approximation and partial coverage, a setting that motivates practical algorithms such as Conservative $Q$-Learning (CQL; Kumar et al., 2020) but has received limited theoretical attention. Our work is inspired by the following open question: "Are $Q^\star$-realizability and Bellman completeness sufficient for sample-efficient offline RL under partial coverage?" We answer in the negative by establishing an information-theoretic lower bound. Going substantially beyond this, we introduce a general framework that characterizes the intrinsic complexity of a given $Q^\star$ function class, inspired by model-free decision-estimation coefficients (DEC) for online RL (Foster et al., 2023b; Liu et al., 2025b). This complexity recovers and improves the quantities underlying the guarantees of Chen and Jiang (2022) and Uehara et al. (2023), and extends to broader settings. Our decision-estimation decomposition can be combined with a wide range of $Q^\star$ estimation procedures, modularizing and generalizing existing approaches. Beyond the general framework, we make further contributions: By developing a novel second-order performance difference lemma, we obtain the first $ε^{-2}$ sample complexity under partial coverage for soft $Q$-learning, improving the $ε^{-4}$ bound of Uehara et al. (2023). We remove Chen and Jiang's (2022) need for additional online interaction when the value gap of $Q^\star$ is unknown. We also give the first characterization of offline learnability for general low-Bellman-rank MDPs without Bellman completeness (Jiang et al., 2017; Du et al., 2021; Jin et al., 2021), a canonical setting in online RL that remains unexplored in offline RL except for special cases. Finally, we provide the first analysis for CQL under $Q^\star$-realizability and Bellman completeness beyond the tabular case.
Achieving Optimal Static and Dynamic Regret Simultaneously in Bandits with Deterministic Losses
Feb 07, 2026In adversarial multi-armed bandits, two performance measures are commonly used: static regret, which compares the learner to the best fixed arm, and dynamic regret, which compares it to the best sequence of arms. While optimal algorithms are known for each measure individually, there is no known algorithm achieving optimal bounds for both simultaneously. Marinov and Zimmert [2021] first showed that such simultaneous optimality is impossible against an adaptive adversary. Our work takes a first step to demonstrate its possibility against an oblivious adversary when losses are deterministic. First, we extend the impossibility result of Marinov and Zimmert [2021] to the case of deterministic losses. Then, we present an algorithm achieving optimal static and dynamic regret simultaneously against an oblivious adversary. Together, they reveal a fundamental separation between adaptive and oblivious adversaries when multiple regret benchmarks are considered simultaneously. It also provides new insight into the long open problem of simultaneously achieving optimal regret against switching benchmarks of different numbers of switches. Our algorithm uses negative static regret to compensate for the exploration overhead incurred when controlling dynamic regret, and leverages Blackwell approachability to jointly control both regrets. This yields a new model selection procedure for bandits that may be of independent interest.
Save the Good Prefix: Precise Error Penalization via Process-Supervised RL to Enhance LLM Reasoning
Jan 26, 2026Reinforcement learning (RL) has emerged as a powerful framework for improving the reasoning capabilities of large language models (LLMs). However, most existing RL approaches rely on sparse outcome rewards, which fail to credit correct intermediate steps in partially successful solutions. Process reward models (PRMs) offer fine-grained step-level supervision, but their scores are often noisy and difficult to evaluate. As a result, recent PRM benchmarks focus on a more objective capability: detecting the first incorrect step in a reasoning path. However, this evaluation target is misaligned with how PRMs are typically used in RL, where their step-wise scores are treated as raw rewards to maximize. To bridge this gap, we propose Verifiable Prefix Policy Optimization (VPPO), which uses PRMs only to localize the first error during RL. Given an incorrect rollout, VPPO partitions the trajectory into a verified correct prefix and an erroneous suffix based on the first error, rewarding the former while applying targeted penalties only after the detected mistake. This design yields stable, interpretable learning signals and improves credit assignment. Across multiple reasoning benchmarks, VPPO consistently outperforms sparse-reward RL and prior PRM-guided baselines on both Pass@1 and Pass@K.
Decision Making in Hybrid Environments: A Model Aggregation Approach
Feb 09, 2025Recent work by Foster et al. (2021, 2022, 2023) and Xu and Zeevi (2023) developed the framework of decision estimation coefficient (DEC) that characterizes the complexity of general online decision making problems and provides a general algorithm design principle. These works, however, either focus on the pure stochastic regime where the world remains fixed over time, or the pure adversarial regime where the world arbitrarily changes over time. For the hybrid regime where the dynamics of the world is fixed while the reward arbitrarily changes, they only give pessimistic bounds on the decision complexity. In this work, we propose a general extension of DEC that more precisely characterizes this case. Besides applications in special cases, our framework leads to a flexible algorithm design where the learner learns over subsets of the hypothesis set, trading estimation complexity with decision complexity, which could be of independent interest. Our work covers model-based learning and model-free learning in the hybrid regime, with a newly proposed extension of the bilinear classes (Du et al., 2021) to the adversarial-reward case. We also recover some existing model-free learning results in the pure stochastic regime.
Beating Adversarial Low-Rank MDPs with Unknown Transition and Bandit Feedback
Nov 11, 2024
We consider regret minimization in low-rank MDPs with fixed transition and adversarial losses. Previous work has investigated this problem under either full-information loss feedback with unknown transitions (Zhao et al., 2024), or bandit loss feedback with known transition (Foster et al., 2022). First, we improve the $poly(d, A, H)T^{5/6}$ regret bound of Zhao et al. (2024) to $poly(d, A, H)T^{2/3}$ for the full-information unknown transition setting, where d is the rank of the transitions, A is the number of actions, H is the horizon length, and T is the number of episodes. Next, we initiate the study on the setting with bandit loss feedback and unknown transitions. Assuming that the loss has a linear structure, we propose both model based and model free algorithms achieving $poly(d, A, H)T^{2/3}$ regret, though they are computationally inefficient. We also propose oracle-efficient model-free algorithms with $poly(d, A, H)T^{4/5}$ regret. We show that the linear structure is necessary for the bandit case without structure on the reward function, the regret has to scale polynomially with the number of states. This is contrary to the full-information case (Zhao et al., 2024), where the regret can be independent of the number of states even for unstructured reward function.
How Does Variance Shape the Regret in Contextual Bandits?
Oct 16, 2024
We consider realizable contextual bandits with general function approximation, investigating how small reward variance can lead to better-than-minimax regret bounds. Unlike in minimax bounds, we show that the eluder dimension $d_\text{elu}$$-$a complexity measure of the function class$-$plays a crucial role in variance-dependent bounds. We consider two types of adversary: (1) Weak adversary: The adversary sets the reward variance before observing the learner's action. In this setting, we prove that a regret of $\Omega(\sqrt{\min\{A,d_\text{elu}\}\Lambda}+d_\text{elu})$ is unavoidable when $d_{\text{elu}}\leq\sqrt{AT}$, where $A$ is the number of actions, $T$ is the total number of rounds, and $\Lambda$ is the total variance over $T$ rounds. For the $A\leq d_\text{elu}$ regime, we derive a nearly matching upper bound $\tilde{O}(\sqrt{A\Lambda}+d_\text{elu})$ for the special case where the variance is revealed at the beginning of each round. (2) Strong adversary: The adversary sets the reward variance after observing the learner's action. We show that a regret of $\Omega(\sqrt{d_\text{elu}\Lambda}+d_\text{elu})$ is unavoidable when $\sqrt{d_\text{elu}\Lambda}+d_\text{elu}\leq\sqrt{AT}$. In this setting, we provide an upper bound of order $\tilde{O}(d_\text{elu}\sqrt{\Lambda}+d_\text{elu})$. Furthermore, we examine the setting where the function class additionally provides distributional information of the reward, as studied by Wang et al. (2024). We demonstrate that the regret bound $\tilde{O}(\sqrt{d_\text{elu}\Lambda}+d_\text{elu})$ established in their work is unimprovable when $\sqrt{d_{\text{elu}}\Lambda}+d_\text{elu}\leq\sqrt{AT}$. However, with a slightly different definition of the total variance and with the assumption that the reward follows a Gaussian distribution, one can achieve a regret of $\tilde{O}(\sqrt{A\Lambda}+d_\text{elu})$.
Corruption-Robust Linear Bandits: Minimax Optimality and Gap-Dependent Misspecification
Oct 10, 2024


In linear bandits, how can a learner effectively learn when facing corrupted rewards? While significant work has explored this question, a holistic understanding across different adversarial models and corruption measures is lacking, as is a full characterization of the minimax regret bounds. In this work, we compare two types of corruptions commonly considered: strong corruption, where the corruption level depends on the action chosen by the learner, and weak corruption, where the corruption level does not depend on the action chosen by the learner. We provide a unified framework to analyze these corruptions. For stochastic linear bandits, we fully characterize the gap between the minimax regret under strong and weak corruptions. We also initiate the study of corrupted adversarial linear bandits, obtaining upper and lower bounds with matching dependencies on the corruption level. Next, we reveal a connection between corruption-robust learning and learning with gap-dependent mis-specification, a setting first studied by Liu et al. (2023a), where the misspecification level of an action or policy is proportional to its suboptimality. We present a general reduction that enables any corruption-robust algorithm to handle gap-dependent misspecification. This allows us to recover the results of Liu et al. (2023a) in a black-box manner and significantly generalize them to settings like linear MDPs, yielding the first results for gap-dependent misspecification in reinforcement learning. However, this general reduction does not attain the optimal rate for gap-dependent misspecification. Motivated by this, we develop a specialized algorithm that achieves optimal bounds for gap-dependent misspecification in linear bandits, thus answering an open question posed by Liu et al. (2023a).
Offline Reinforcement Learning: Role of State Aggregation and Trajectory Data
Mar 25, 2024



We revisit the problem of offline reinforcement learning with value function realizability but without Bellman completeness. Previous work by Xie and Jiang (2021) and Foster et al. (2022) left open the question whether a bounded concentrability coefficient along with trajectory-based offline data admits a polynomial sample complexity. In this work, we provide a negative answer to this question for the task of offline policy evaluation. In addition to addressing this question, we provide a rather complete picture for offline policy evaluation with only value function realizability. Our primary findings are threefold: 1) The sample complexity of offline policy evaluation is governed by the concentrability coefficient in an aggregated Markov Transition Model jointly determined by the function class and the offline data distribution, rather than that in the original MDP. This unifies and generalizes the ideas of Xie and Jiang (2021) and Foster et al. (2022), 2) The concentrability coefficient in the aggregated Markov Transition Model may grow exponentially with the horizon length, even when the concentrability coefficient in the original MDP is small and the offline data is admissible (i.e., the data distribution equals the occupancy measure of some policy), 3) Under value function realizability, there is a generic reduction that can convert any hard instance with admissible data to a hard instance with trajectory data, implying that trajectory data offers no extra benefits over admissible data. These three pieces jointly resolve the open problem, though each of them could be of independent interest.
Tractable Local Equilibria in Non-Concave Games
Mar 13, 2024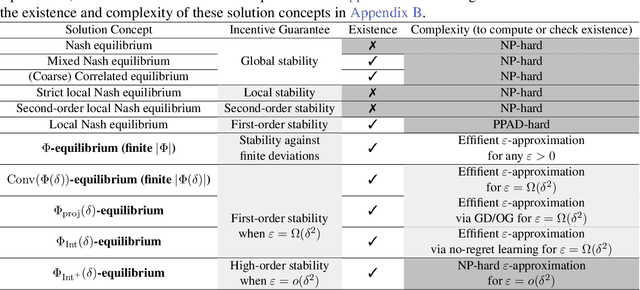
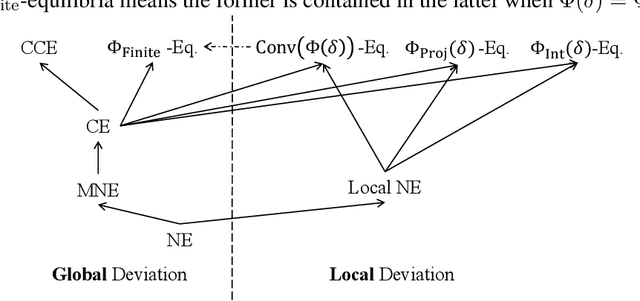
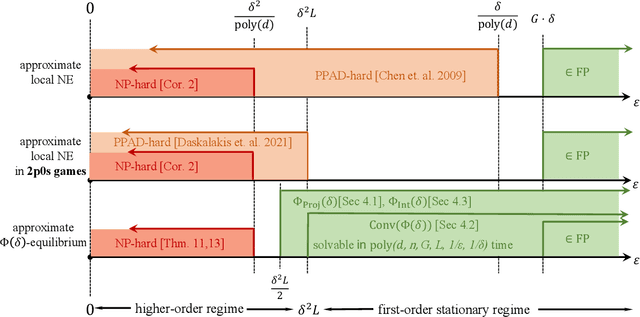
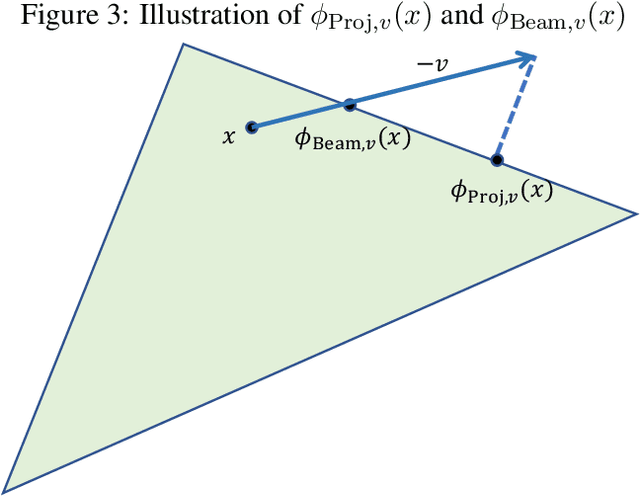
While Online Gradient Descent and other no-regret learning procedures are known to efficiently converge to coarse correlated equilibrium in games where each agent's utility is concave in their own strategy, this is not the case when the utilities are non-concave, a situation that is common in machine learning applications where the agents' strategies are parameterized by deep neural networks, or the agents' utilities are computed by a neural network, or both. Indeed, non-concave games present a host of game-theoretic and optimization challenges: (i) Nash equilibria may fail to exist; (ii) local Nash equilibria exist but are intractable; and (iii) mixed Nash, correlated, and coarse correlated equilibria have infinite support in general, and are intractable. To sidestep these challenges we propose a new solution concept, termed $(\varepsilon, \Phi(\delta))$-local equilibrium, which generalizes local Nash equilibrium in non-concave games, as well as (coarse) correlated equilibrium in concave games. Importantly, we show that two instantiations of this solution concept capture the convergence guarantees of Online Gradient Descent and no-regret learning, which we show efficiently converge to this type of equilibrium in non-concave games with smooth utilities.