 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat should post-training optimize? A test-time scaling law perspective
May 11, 2026Large language models are increasingly deployed with test-time strategies: sample $N$ responses, score them with a reward model or verifier, and return the best. This deployment rule exposes a mismatch in post-training: standard objectives optimize the mean reward of a single response, whereas best-of-$N$ performance is governed by the upper tail of the reward distribution. Recent test-time-aware objectives partly address this mismatch, but typically assume that training can use the same per-prompt rollout budget as deployment, which is impractical when post-training must cover many prompts while deployment can allocate much larger per-prompt test-time compute. We study this budget-mismatch regime, where only $m\ll N$ per-prompt rollouts are available during training but the target objective is best-of-$N$ deployment. Under structural assumptions on the reward tails, we show that the policy gradient of the best-of-$N$ objective can be approximated from a much smaller rollout group by extrapolating upper-tail statistics. This yields a family of Tail-Extrapolated estimators for best-of-$N$-oriented post-training: a simple direct estimator, Tail-Extrapolated Advantage (TEA), and a fixed-order debiased Prefix-TEA estimator based on moment cancellation. Experiments on instruction-following tasks show that TEA and Prefix-TEA improve best-of-$N$ performance across different language models, reward models and datasets under various training and test-time budget settings.
Leave-One-Out Prediction for General Hypothesis Classes
Mar 02, 2026Leave-one-out (LOO) prediction provides a principled, data-dependent measure of generalization, yet guarantees in fully transductive settings remain poorly understood beyond specialized models. We introduce Median of Level-Set Aggregation (MLSA), a general aggregation procedure based on empirical-risk level sets around the ERM. For arbitrary fixed datasets and losses satisfying a mild monotonicity condition, we establish a multiplicative oracle inequality for the LOO error of the form \[ LOO_S(\hat{h}) \;\le\; C \cdot \frac{1}{n} \min_{h\in H} L_S(h) \;+\; \frac{Comp(S,H,\ell)}{n}, \qquad C>1. \] The analysis is based on a local level-set growth condition controlling how the set of near-optimal empirical-risk minimizers expands as the tolerance increases. We verify this condition in several canonical settings. For classification with VC classes under the 0-1 loss, the resulting complexity scales as $O(d \log n)$, where $d$ is the VC dimension. For finite hypothesis and density classes under bounded or log loss, it scales as $O(\log |H|)$ and $O(\log |P|)$, respectively. For logistic regression with bounded covariates and parameters, a volumetric argument based on the empirical covariance matrix yields complexity scaling as $O(d \log n)$ up to problem-dependent factors.
Ratio Covers of Convex Sets and Optimal Mixture Density Estimation
Feb 18, 2026We study density estimation in Kullback-Leibler divergence: given an i.i.d. sample from an unknown density $p$, the goal is to construct an estimator $\widehat p$ such that $\mathrm{KL}(p,\widehat p)$ is small with high probability. We consider two settings involving a finite dictionary of $M$ densities: (i) model aggregation, where $p$ belongs to the dictionary, and (ii) convex aggregation (mixture density estimation), where $p$ is a mixture of densities from the dictionary. Crucially, we make no assumption on the base densities: their ratios may be unbounded and their supports may differ. For both problems, we identify the best possible high-probability guarantees in terms of the dictionary size, sample size, and confidence level. These optimal rates are higher than those achievable when density ratios are bounded by absolute constants; for mixture density estimation, they match existing lower bounds in the special case of discrete distributions. Our analysis of the mixture case hinges on two new covering results. First, we provide a sharp, distribution-free upper bound on the local Hellinger entropy of the class of mixtures of $M$ distributions. Second, we prove an optimal ratio covering theorem for convex sets: for every convex compact set $K\subset \mathbb{R}_+^d$, there exists a subset $A\subset K$ with at most $2^{8d}$ elements such that each element of $K$ is coordinate-wise dominated by an element of $A$ up to a universal constant factor. This geometric result is of independent interest; notably, it yields new cardinality estimates for $\varepsilon$-approximate Pareto sets in multi-objective optimization when the attainable set of objective vectors is convex.
Data Reconstruction: Identifiability and Optimization with Sample Splitting
Feb 09, 2026Training data reconstruction from KKT conditions has shown striking empirical success, yet it remains unclear when the resulting KKT equations have unique solutions and, even in identifiable regimes, how to reliably recover solutions by optimization. This work hereby focuses on these two complementary questions: identifiability and optimization. On the identifiability side, we discuss the sufficient conditions for KKT system of two-layer networks with polynomial activations to uniquely determine the training data, providing a theoretical explanation of when and why reconstruction is possible. On the optimization side, we introduce sample splitting, a curvature-aware refinement step applicable to general reconstruction objectives (not limited to KKT-based formulations): it creates additional descent directions to escape poor stationary points and refine solutions. Experiments demonstrate that augmenting several existing reconstruction methods with sample splitting consistently improves reconstruction performance.
Achieving Optimal Static and Dynamic Regret Simultaneously in Bandits with Deterministic Losses
Feb 07, 2026In adversarial multi-armed bandits, two performance measures are commonly used: static regret, which compares the learner to the best fixed arm, and dynamic regret, which compares it to the best sequence of arms. While optimal algorithms are known for each measure individually, there is no known algorithm achieving optimal bounds for both simultaneously. Marinov and Zimmert [2021] first showed that such simultaneous optimality is impossible against an adaptive adversary. Our work takes a first step to demonstrate its possibility against an oblivious adversary when losses are deterministic. First, we extend the impossibility result of Marinov and Zimmert [2021] to the case of deterministic losses. Then, we present an algorithm achieving optimal static and dynamic regret simultaneously against an oblivious adversary. Together, they reveal a fundamental separation between adaptive and oblivious adversaries when multiple regret benchmarks are considered simultaneously. It also provides new insight into the long open problem of simultaneously achieving optimal regret against switching benchmarks of different numbers of switches. Our algorithm uses negative static regret to compensate for the exploration overhead incurred when controlling dynamic regret, and leverages Blackwell approachability to jointly control both regrets. This yields a new model selection procedure for bandits that may be of independent interest.
Predicting and improving test-time scaling laws via reward tail-guided search
Feb 01, 2026Test-time scaling has emerged as a critical avenue for enhancing the reasoning capabilities of Large Language Models (LLMs). Though the straight-forward ''best-of-$N$'' (BoN) strategy has already demonstrated significant improvements in performance, it lacks principled guidance on the choice of $N$, budget allocation, and multi-stage decision-making, thereby leaving substantial room for optimization. While many works have explored such optimization, rigorous theoretical guarantees remain limited. In this work, we propose new methodologies to predict and improve scaling properties via tail-guided search. By estimating the tail distribution of rewards, our method predicts the scaling law of LLMs without the need for exhaustive evaluations. Leveraging this prediction tool, we introduce Scaling-Law Guided (SLG) Search, a new test-time algorithm that dynamically allocates compute to identify and exploit intermediate states with the highest predicted potential. We theoretically prove that SLG achieves vanishing regret compared to perfect-information oracles, and achieves expected rewards that would otherwise require a polynomially larger compute budget required when using BoN. Empirically, we validate our framework across different LLMs and reward models, confirming that tail-guided allocation consistently achieves higher reward yields than Best-of-$N$ under identical compute budgets. Our code is available at https://github.com/PotatoJnny/Scaling-Law-Guided-search.
BioMamba: Leveraging Spectro-Temporal Embedding in Bidirectional Mamba for Enhanced Biosignal Classification
Mar 14, 2025

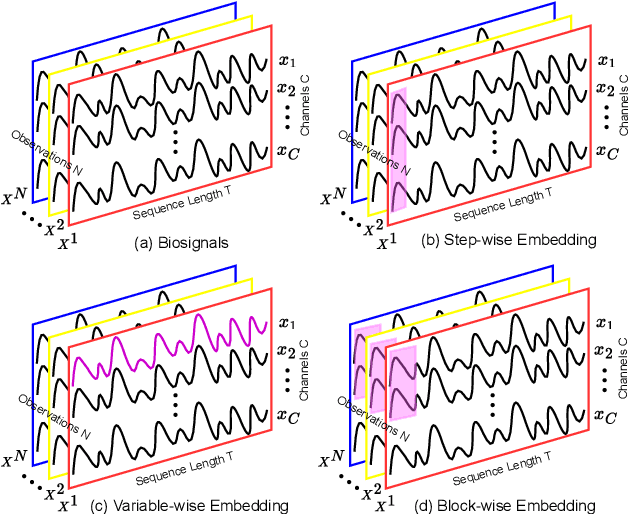

Biological signals, such as electroencephalograms (EEGs) and electrocardiograms (ECGs), play a pivotal role in numerous clinical practices, such as diagnosing brain and cardiac arrhythmic diseases. Existing methods for biosignal classification rely on Attention-based frameworks with dense Feed Forward layers, which lead to inefficient learning, high computational overhead, and suboptimal performance. In this work, we introduce BioMamba, a Spectro-Temporal Embedding strategy applied to the Bidirectional Mamba framework with Sparse Feed Forward layers to enable effective learning of biosignal sequences. By integrating these three key components, BioMamba effectively addresses the limitations of existing methods. Extensive experiments demonstrate that BioMamba significantly outperforms state-of-the-art methods with marked improvement in classification performance. The advantages of the proposed BioMamba include (1) Reliability: BioMamba consistently delivers robust results, confirmed across six evaluation metrics. (2) Efficiency: We assess both model and training efficiency, the BioMamba demonstrates computational effectiveness by reducing model size and resource consumption compared to existing approaches. (3) Generality: With the capacity to effectively classify a diverse set of tasks, BioMamba demonstrates adaptability and effectiveness across various domains and applications.
To bootstrap or to rollout? An optimal and adaptive interpolation
Nov 14, 2024Bootstrapping and rollout are two fundamental principles for value function estimation in reinforcement learning (RL). We introduce a novel class of Bellman operators, called subgraph Bellman operators, that interpolate between bootstrapping and rollout methods. Our estimator, derived by solving the fixed point of the empirical subgraph Bellman operator, combines the strengths of the bootstrapping-based temporal difference (TD) estimator and the rollout-based Monte Carlo (MC) methods. Specifically, the error upper bound of our estimator approaches the optimal variance achieved by TD, with an additional term depending on the exit probability of a selected subset of the state space. At the same time, the estimator exhibits the finite-sample adaptivity of MC, with sample complexity depending only on the occupancy measure of this subset. We complement the upper bound with an information-theoretic lower bound, showing that the additional term is unavoidable given a reasonable sample size. Together, these results establish subgraph Bellman estimators as an optimal and adaptive framework for reconciling TD and MC methods in policy evaluation.
Refined Risk Bounds for Unbounded Losses via Transductive Priors
Oct 29, 2024We revisit the sequential variants of linear regression with the squared loss, classification problems with hinge loss, and logistic regression, all characterized by unbounded losses in the setup where no assumptions are made on the magnitude of design vectors and the norm of the optimal vector of parameters. The key distinction from existing results lies in our assumption that the set of design vectors is known in advance (though their order is not), a setup sometimes referred to as transductive online learning. While this assumption seems similar to fixed design regression or denoising, we demonstrate that the sequential nature of our algorithms allows us to convert our bounds into statistical ones with random design without making any additional assumptions about the distribution of the design vectors--an impossibility for standard denoising results. Our key tools are based on the exponential weights algorithm with carefully chosen transductive (design-dependent) priors, which exploit the full horizon of the design vectors. Our classification regret bounds have a feature that is only attributed to bounded losses in the literature: they depend solely on the dimension of the parameter space and on the number of rounds, independent of the design vectors or the norm of the optimal solution. For linear regression with squared loss, we further extend our analysis to the sparse case, providing sparsity regret bounds that additionally depend on the magnitude of the response variables. We argue that these improved bounds are specific to the transductive setting and unattainable in the worst-case sequential setup. Our algorithms, in several cases, have polynomial time approximations and reduce to sampling with respect to log-concave measures instead of aggregating over hard-to-construct $\varepsilon$-covers of classes.
How Does Variance Shape the Regret in Contextual Bandits?
Oct 16, 2024
We consider realizable contextual bandits with general function approximation, investigating how small reward variance can lead to better-than-minimax regret bounds. Unlike in minimax bounds, we show that the eluder dimension $d_\text{elu}$$-$a complexity measure of the function class$-$plays a crucial role in variance-dependent bounds. We consider two types of adversary: (1) Weak adversary: The adversary sets the reward variance before observing the learner's action. In this setting, we prove that a regret of $\Omega(\sqrt{\min\{A,d_\text{elu}\}\Lambda}+d_\text{elu})$ is unavoidable when $d_{\text{elu}}\leq\sqrt{AT}$, where $A$ is the number of actions, $T$ is the total number of rounds, and $\Lambda$ is the total variance over $T$ rounds. For the $A\leq d_\text{elu}$ regime, we derive a nearly matching upper bound $\tilde{O}(\sqrt{A\Lambda}+d_\text{elu})$ for the special case where the variance is revealed at the beginning of each round. (2) Strong adversary: The adversary sets the reward variance after observing the learner's action. We show that a regret of $\Omega(\sqrt{d_\text{elu}\Lambda}+d_\text{elu})$ is unavoidable when $\sqrt{d_\text{elu}\Lambda}+d_\text{elu}\leq\sqrt{AT}$. In this setting, we provide an upper bound of order $\tilde{O}(d_\text{elu}\sqrt{\Lambda}+d_\text{elu})$. Furthermore, we examine the setting where the function class additionally provides distributional information of the reward, as studied by Wang et al. (2024). We demonstrate that the regret bound $\tilde{O}(\sqrt{d_\text{elu}\Lambda}+d_\text{elu})$ established in their work is unimprovable when $\sqrt{d_{\text{elu}}\Lambda}+d_\text{elu}\leq\sqrt{AT}$. However, with a slightly different definition of the total variance and with the assumption that the reward follows a Gaussian distribution, one can achieve a regret of $\tilde{O}(\sqrt{A\Lambda}+d_\text{elu})$.