 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTimeLDM: Latent Diffusion Model for Unconditional Time Series Generation
Jul 05, 2024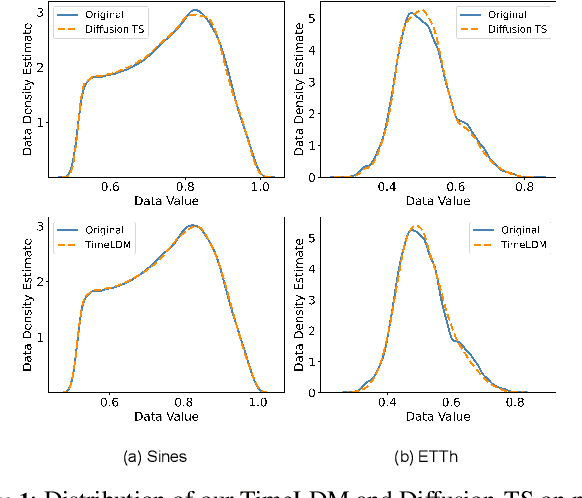

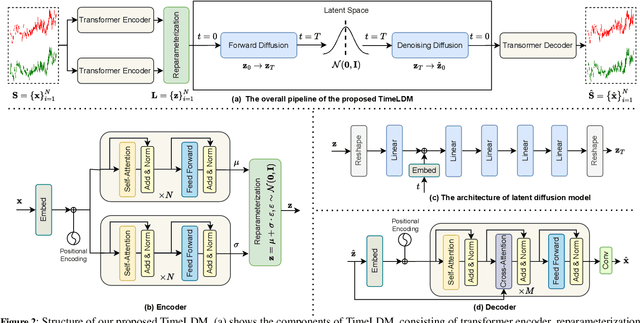
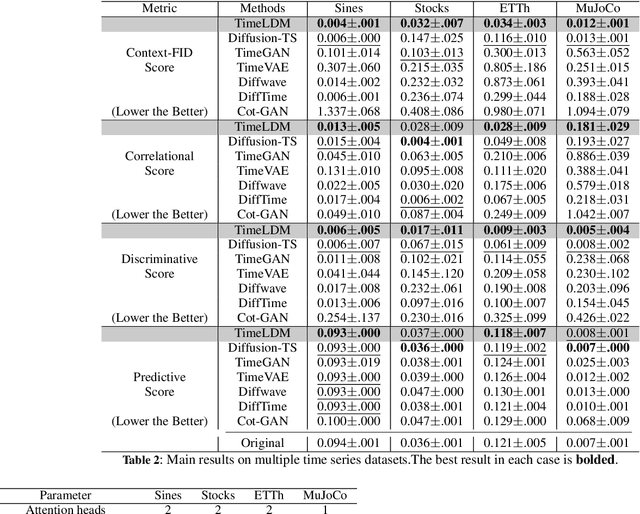
Time series generation is a crucial research topic in the area of deep learning, which can be used for data augmentation, imputing missing values, and forecasting. Currently, latent diffusion models are ascending to the forefront of generative modeling for many important data representations. Being the most pivotal in the computer vision domain, latent diffusion models have also recently attracted interest in other communities, including NLP, Speech, and Geometric Space. In this work, we propose TimeLDM, a novel latent diffusion model for high-quality time series generation. TimeLDM is composed of a variational autoencoder that encodes time series into an informative and smoothed latent content and a latent diffusion model operating in the latent space to generate latent information. We evaluate the ability of our method to generate synthetic time series with simulated and realistic datasets, benchmark the performance against existing state-of-the-art methods. Qualitatively and quantitatively, we find that the proposed TimeLDM persistently delivers high-quality generated time series. Sores from Context-FID and Discriminative indicate that TimeLDM consistently and significantly outperforms current state-of-the-art benchmarks with an average improvement of 3.4$\times$ and 3.8$\times$, respectively. Further studies demonstrate that our method presents better performance on different lengths of time series data generation. To the best of our knowledge, this is the first study to explore the potential of the latent diffusion model for unconditional time series generation and establish a new baseline for synthetic time series.
2D3D-MATR: 2D-3D Matching Transformer for Detection-free Registration between Images and Point Clouds
Aug 14, 2023The commonly adopted detect-then-match approach to registration finds difficulties in the cross-modality cases due to the incompatible keypoint detection and inconsistent feature description. We propose, 2D3D-MATR, a detection-free method for accurate and robust registration between images and point clouds. Our method adopts a coarse-to-fine pipeline where it first computes coarse correspondences between downsampled patches of the input image and the point cloud and then extends them to form dense correspondences between pixels and points within the patch region. The coarse-level patch matching is based on transformer which jointly learns global contextual constraints with self-attention and cross-modality correlations with cross-attention. To resolve the scale ambiguity in patch matching, we construct a multi-scale pyramid for each image patch and learn to find for each point patch the best matching image patch at a proper resolution level. Extensive experiments on two public benchmarks demonstrate that 2D3D-MATR outperforms the previous state-of-the-art P2-Net by around $20$ percentage points on inlier ratio and over $10$ points on registration recall. Our code and models are available at https://github.com/minhaolee/2D3DMATR.