 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSRNav: Reasoning Spatial Relationship for Image-Goal Navigation
Apr 25, 2025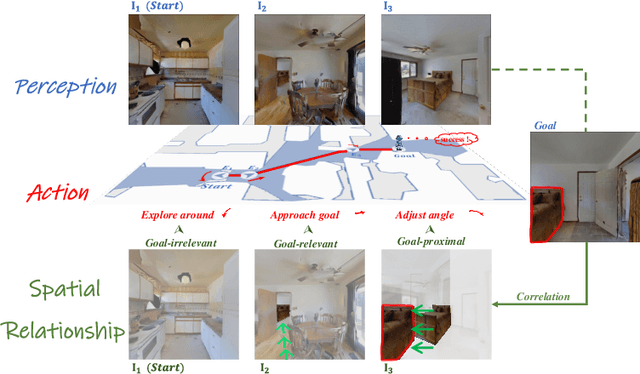
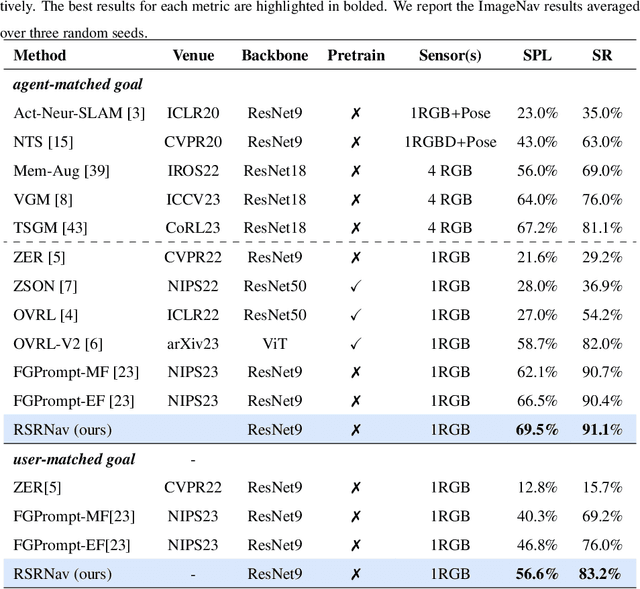
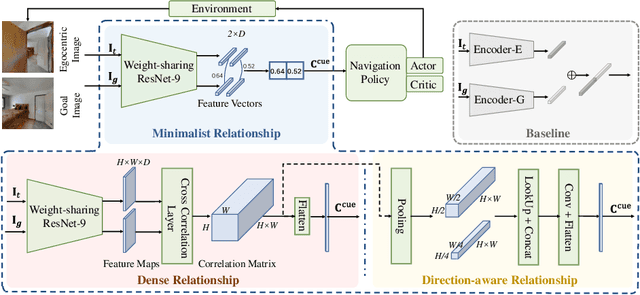
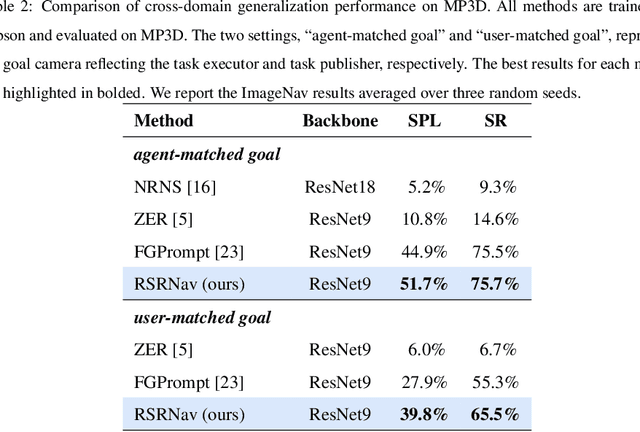
Recent image-goal navigation (ImageNav) methods learn a perception-action policy by separately capturing semantic features of the goal and egocentric images, then passing them to a policy network. However, challenges remain: (1) Semantic features often fail to provide accurate directional information, leading to superfluous actions, and (2) performance drops significantly when viewpoint inconsistencies arise between training and application. To address these challenges, we propose RSRNav, a simple yet effective method that reasons spatial relationships between the goal and current observations as navigation guidance. Specifically, we model the spatial relationship by constructing correlations between the goal and current observations, which are then passed to the policy network for action prediction. These correlations are progressively refined using fine-grained cross-correlation and direction-aware correlation for more precise navigation. Extensive evaluation of RSRNav on three benchmark datasets demonstrates superior navigation performance, particularly in the "user-matched goal" setting, highlighting its potential for real-world applications.
From Mapping to Composing: A Two-Stage Framework for Zero-shot Composed Image Retrieval
Apr 25, 2025Composed Image Retrieval (CIR) is a challenging multimodal task that retrieves a target image based on a reference image and accompanying modification text. Due to the high cost of annotating CIR triplet datasets, zero-shot (ZS) CIR has gained traction as a promising alternative. Existing studies mainly focus on projection-based methods, which map an image to a single pseudo-word token. However, these methods face three critical challenges: (1) insufficient pseudo-word token representation capacity, (2) discrepancies between training and inference phases, and (3) reliance on large-scale synthetic data. To address these issues, we propose a two-stage framework where the training is accomplished from mapping to composing. In the first stage, we enhance image-to-pseudo-word token learning by introducing a visual semantic injection module and a soft text alignment objective, enabling the token to capture richer and fine-grained image information. In the second stage, we optimize the text encoder using a small amount of synthetic triplet data, enabling it to effectively extract compositional semantics by combining pseudo-word tokens with modification text for accurate target image retrieval. The strong visual-to-pseudo mapping established in the first stage provides a solid foundation for the second stage, making our approach compatible with both high- and low-quality synthetic data, and capable of achieving significant performance gains with only a small amount of synthetic data. Extensive experiments were conducted on three public datasets, achieving superior performance compared to existing approaches.
Pedestrian Trajectory Prediction Based on Social Interactions Learning With Random Weights
Jan 13, 2025



Pedestrian trajectory prediction is a critical technology in the evolution of self-driving cars toward complete artificial intelligence. Over recent years, focusing on the trajectories of pedestrians to model their social interactions has surged with great interest in more accurate trajectory predictions. However, existing methods for modeling pedestrian social interactions rely on pre-defined rules, struggling to capture non-explicit social interactions. In this work, we propose a novel framework named DTGAN, which extends the application of Generative Adversarial Networks (GANs) to graph sequence data, with the primary objective of automatically capturing implicit social interactions and achieving precise predictions of pedestrian trajectory. DTGAN innovatively incorporates random weights within each graph to eliminate the need for pre-defined interaction rules. We further enhance the performance of DTGAN by exploring diverse task loss functions during adversarial training, which yields improvements of 16.7\% and 39.3\% on metrics ADE and FDE, respectively. The effectiveness and accuracy of our framework are verified on two public datasets. The experimental results show that our proposed DTGAN achieves superior performance and is well able to understand pedestrians' intentions.
Referencing Where to Focus: Improving VisualGrounding with Referential Query
Dec 26, 2024



Visual Grounding aims to localize the referring object in an image given a natural language expression. Recent advancements in DETR-based visual grounding methods have attracted considerable attention, as they directly predict the coordinates of the target object without relying on additional efforts, such as pre-generated proposal candidates or pre-defined anchor boxes. However, existing research primarily focuses on designing stronger multi-modal decoder, which typically generates learnable queries by random initialization or by using linguistic embeddings. This vanilla query generation approach inevitably increases the learning difficulty for the model, as it does not involve any target-related information at the beginning of decoding. Furthermore, they only use the deepest image feature during the query learning process, overlooking the importance of features from other levels. To address these issues, we propose a novel approach, called RefFormer. It consists of the query adaption module that can be seamlessly integrated into CLIP and generate the referential query to provide the prior context for decoder, along with a task-specific decoder. By incorporating the referential query into the decoder, we can effectively mitigate the learning difficulty of the decoder, and accurately concentrate on the target object. Additionally, our proposed query adaption module can also act as an adapter, preserving the rich knowledge within CLIP without the need to tune the parameters of the backbone network. Extensive experiments demonstrate the effectiveness and efficiency of our proposed method, outperforming state-of-the-art approaches on five visual grounding benchmarks.
CogNav: Cognitive Process Modeling for Object Goal Navigation with LLMs
Dec 11, 2024



Object goal navigation (ObjectNav) is a fundamental task of embodied AI that requires the agent to find a target object in unseen environments. This task is particularly challenging as it demands both perceptual and cognitive processes for effective perception and decision-making. While perception has gained significant progress powered by the rapidly developed visual foundation models, the progress on the cognitive side remains limited to either implicitly learning from massive navigation demonstrations or explicitly leveraging pre-defined heuristic rules. Inspired by neuroscientific evidence that humans consistently update their cognitive states while searching for objects in unseen environments, we present CogNav, which attempts to model this cognitive process with the help of large language models. Specifically, we model the cognitive process with a finite state machine composed of cognitive states ranging from exploration to identification. The transitions between the states are determined by a large language model based on an online built heterogeneous cognitive map containing spatial and semantic information of the scene being explored. Extensive experiments on both synthetic and real-world environments demonstrate that our cognitive modeling significantly improves ObjectNav efficiency, with human-like navigation behaviors. In an open-vocabulary and zero-shot setting, our method advances the SOTA of the HM3D benchmark from 69.3% to 87.2%. The code and data will be released.
Towards Generalizable Multi-Object Tracking
Jun 01, 2024



Multi-Object Tracking MOT encompasses various tracking scenarios, each characterized by unique traits. Effective trackers should demonstrate a high degree of generalizability across diverse scenarios. However, existing trackers struggle to accommodate all aspects or necessitate hypothesis and experimentation to customize the association information motion and or appearance for a given scenario, leading to narrowly tailored solutions with limited generalizability. In this paper, we investigate the factors that influence trackers generalization to different scenarios and concretize them into a set of tracking scenario attributes to guide the design of more generalizable trackers. Furthermore, we propose a point-wise to instance-wise relation framework for MOT, i.e., GeneralTrack, which can generalize across diverse scenarios while eliminating the need to balance motion and appearance. Thanks to its superior generalizability, our proposed GeneralTrack achieves state-of-the-art performance on multiple benchmarks and demonstrates the potential for domain generalization. https://github.com/qinzheng2000/GeneralTrack.git
NeRF-Guided Unsupervised Learning of RGB-D Registration
May 01, 2024



This paper focuses on training a robust RGB-D registration model without ground-truth pose supervision. Existing methods usually adopt a pairwise training strategy based on differentiable rendering, which enforces the photometric and the geometric consistency between the two registered frames as supervision. However, this frame-to-frame framework suffers from poor multi-view consistency due to factors such as lighting changes, geometry occlusion and reflective materials. In this paper, we present NeRF-UR, a novel frame-to-model optimization framework for unsupervised RGB-D registration. Instead of frame-to-frame consistency, we leverage the neural radiance field (NeRF) as a global model of the scene and use the consistency between the input and the NeRF-rerendered frames for pose optimization. This design can significantly improve the robustness in scenarios with poor multi-view consistency and provides better learning signal for the registration model. Furthermore, to bootstrap the NeRF optimization, we create a synthetic dataset, Sim-RGBD, through a photo-realistic simulator to warm up the registration model. By first training the registration model on Sim-RGBD and later unsupervisedly fine-tuning on real data, our framework enables distilling the capability of feature extraction and registration from simulation to reality. Our method outperforms the state-of-the-art counterparts on two popular indoor RGB-D datasets, ScanNet and 3DMatch. Code and models will be released for paper reproduction.
Are Watermarks Bugs for Deepfake Detectors? Rethinking Proactive Forensics
Apr 27, 2024



AI-generated content has accelerated the topic of media synthesis, particularly Deepfake, which can manipulate our portraits for positive or malicious purposes. Before releasing these threatening face images, one promising forensics solution is the injection of robust watermarks to track their own provenance. However, we argue that current watermarking models, originally devised for genuine images, may harm the deployed Deepfake detectors when directly applied to forged images, since the watermarks are prone to overlap with the forgery signals used for detection. To bridge this gap, we thus propose AdvMark, on behalf of proactive forensics, to exploit the adversarial vulnerability of passive detectors for good. Specifically, AdvMark serves as a plug-and-play procedure for fine-tuning any robust watermarking into adversarial watermarking, to enhance the forensic detectability of watermarked images; meanwhile, the watermarks can still be extracted for provenance tracking. Extensive experiments demonstrate the effectiveness of the proposed AdvMark, leveraging robust watermarking to fool Deepfake detectors, which can help improve the accuracy of downstream Deepfake detection without tuning the in-the-wild detectors. We believe this work will shed some light on the harmless proactive forensics against Deepfake.
Robust Noisy Label Learning via Two-Stream Sample Distillation
Apr 16, 2024Noisy label learning aims to learn robust networks under the supervision of noisy labels, which plays a critical role in deep learning. Existing work either conducts sample selection or label correction to deal with noisy labels during the model training process. In this paper, we design a simple yet effective sample selection framework, termed Two-Stream Sample Distillation (TSSD), for noisy label learning, which can extract more high-quality samples with clean labels to improve the robustness of network training. Firstly, a novel Parallel Sample Division (PSD) module is designed to generate a certain training set with sufficient reliable positive and negative samples by jointly considering the sample structure in feature space and the human prior in loss space. Secondly, a novel Meta Sample Purification (MSP) module is further designed to mine adequate semi-hard samples from the remaining uncertain training set by learning a strong meta classifier with extra golden data. As a result, more and more high-quality samples will be distilled from the noisy training set to train networks robustly in every iteration. Extensive experiments on four benchmark datasets, including CIFAR-10, CIFAR-100, Tiny-ImageNet, and Clothing-1M, show that our method has achieved state-of-the-art results over its competitors.
Learning Instance-Aware Correspondences for Robust Multi-Instance Point Cloud Registration in Cluttered Scenes
Apr 06, 2024Multi-instance point cloud registration estimates the poses of multiple instances of a model point cloud in a scene point cloud. Extracting accurate point correspondence is to the center of the problem. Existing approaches usually treat the scene point cloud as a whole, overlooking the separation of instances. Therefore, point features could be easily polluted by other points from the background or different instances, leading to inaccurate correspondences oblivious to separate instances, especially in cluttered scenes. In this work, we propose MIRETR, Multi-Instance REgistration TRansformer, a coarse-to-fine approach to the extraction of instance-aware correspondences. At the coarse level, it jointly learns instance-aware superpoint features and predicts per-instance masks. With instance masks, the influence from outside of the instance being concerned is minimized, such that highly reliable superpoint correspondences can be extracted. The superpoint correspondences are then extended to instance candidates at the fine level according to the instance masks. At last, an efficient candidate selection and refinement algorithm is devised to obtain the final registrations. Extensive experiments on three public benchmarks demonstrate the efficacy of our approach. In particular, MIRETR outperforms the state of the arts by 16.6 points on F1 score on the challenging ROBI benchmark. Code and models are available at https://github.com/zhiyuanYU134/MIRETR.