 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverberation: Learning the Latencies Before Forecasting Trajectories
Nov 14, 2025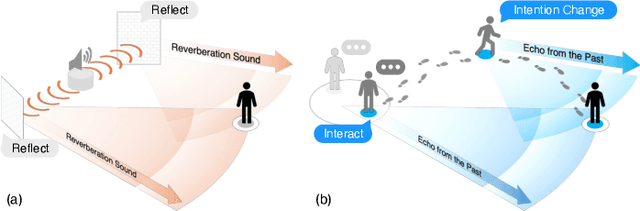
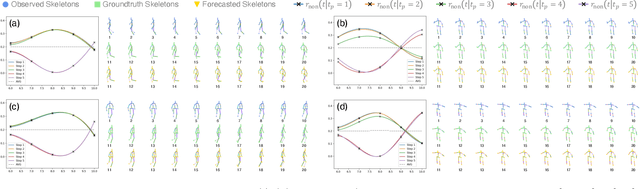
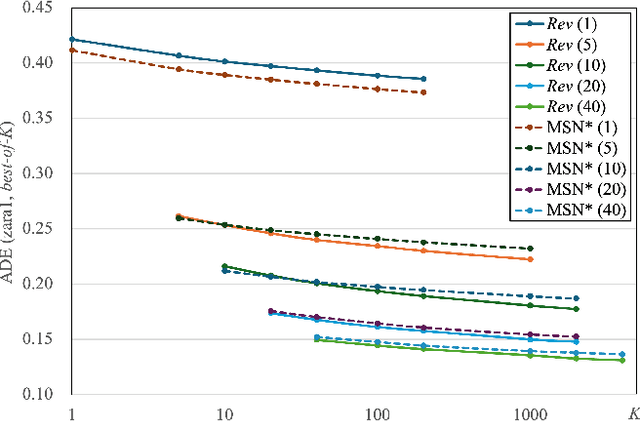
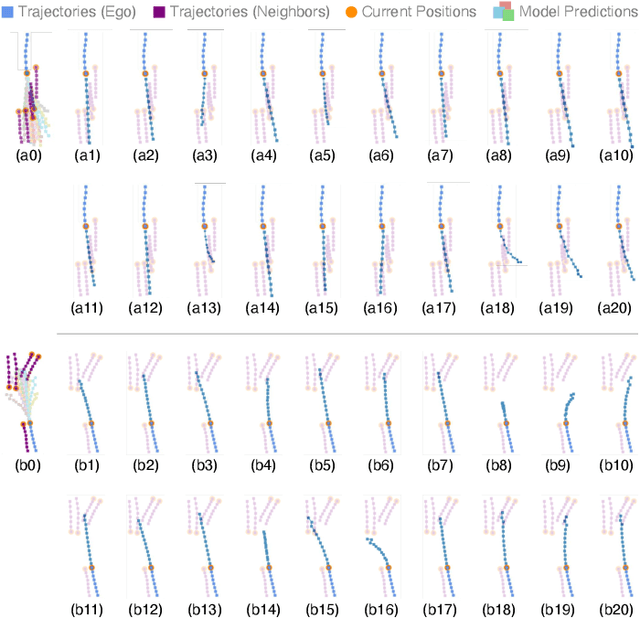
Bridging the past to the future, connecting agents both spatially and temporally, lies at the core of the trajectory prediction task. Despite great efforts, it remains challenging to explicitly learn and predict latencies, the temporal delays with which agents respond to different trajectory-changing events and adjust their future paths, whether on their own or interactively. Different agents may exhibit distinct latency preferences for noticing, processing, and reacting to any specific trajectory-changing event. The lack of consideration of such latencies may undermine the causal continuity of the forecasting system and also lead to implausible or unintended trajectories. Inspired by the reverberation curves in acoustics, we propose a new reverberation transform and the corresponding Reverberation (short for Rev) trajectory prediction model, which simulates and predicts different latency preferences of each agent as well as their stochasticity by using two explicit and learnable reverberation kernels, allowing for the controllable trajectory prediction based on these forecasted latencies. Experiments on multiple datasets, whether pedestrians or vehicles, demonstrate that Rev achieves competitive accuracy while revealing interpretable latency dynamics across agents and scenarios. Qualitative analyses further verify the properties of the proposed reverberation transform, highlighting its potential as a general latency modeling approach.
TubeRMC: Tube-conditioned Reconstruction with Mutual Constraints for Weakly-supervised Spatio-Temporal Video Grounding
Nov 13, 2025Spatio-Temporal Video Grounding (STVG) aims to localize a spatio-temporal tube that corresponds to a given language query in an untrimmed video. This is a challenging task since it involves complex vision-language understanding and spatiotemporal reasoning. Recent works have explored weakly-supervised setting in STVG to eliminate reliance on fine-grained annotations like bounding boxes or temporal stamps. However, they typically follow a simple late-fusion manner, which generates tubes independent of the text description, often resulting in failed target identification and inconsistent target tracking. To address this limitation, we propose a Tube-conditioned Reconstruction with Mutual Constraints (\textbf{TubeRMC}) framework that generates text-conditioned candidate tubes with pre-trained visual grounding models and further refine them via tube-conditioned reconstruction with spatio-temporal constraints. Specifically, we design three reconstruction strategies from temporal, spatial, and spatio-temporal perspectives to comprehensively capture rich tube-text correspondences. Each strategy is equipped with a Tube-conditioned Reconstructor, utilizing spatio-temporal tubes as condition to reconstruct the key clues in the query. We further introduce mutual constraints between spatial and temporal proposals to enhance their quality for reconstruction. TubeRMC outperforms existing methods on two public benchmarks VidSTG and HCSTVG. Further visualization shows that TubeRMC effectively mitigates both target identification errors and inconsistent tracking.
UAVD-Mamba: Deformable Token Fusion Vision Mamba for Multimodal UAV Detection
Jul 01, 2025Unmanned Aerial Vehicle (UAV) object detection has been widely used in traffic management, agriculture, emergency rescue, etc. However, it faces significant challenges, including occlusions, small object sizes, and irregular shapes. These challenges highlight the necessity for a robust and efficient multimodal UAV object detection method. Mamba has demonstrated considerable potential in multimodal image fusion. Leveraging this, we propose UAVD-Mamba, a multimodal UAV object detection framework based on Mamba architectures. To improve geometric adaptability, we propose the Deformable Token Mamba Block (DTMB) to generate deformable tokens by incorporating adaptive patches from deformable convolutions alongside normal patches from normal convolutions, which serve as the inputs to the Mamba Block. To optimize the multimodal feature complementarity, we design two separate DTMBs for the RGB and infrared (IR) modalities, with the outputs from both DTMBs integrated into the Mamba Block for feature extraction and into the Fusion Mamba Block for feature fusion. Additionally, to improve multiscale object detection, especially for small objects, we stack four DTMBs at different scales to produce multiscale feature representations, which are then sent to the Detection Neck for Mamba (DNM). The DNM module, inspired by the YOLO series, includes modifications to the SPPF and C3K2 of YOLOv11 to better handle the multiscale features. In particular, we employ cross-enhanced spatial attention before the DTMB and cross-channel attention after the Fusion Mamba Block to extract more discriminative features. Experimental results on the DroneVehicle dataset show that our method outperforms the baseline OAFA method by 3.6% in the mAP metric. Codes will be released at https://github.com/GreatPlum-hnu/UAVD-Mamba.git.
Pedestrian Trajectory Prediction Based on Social Interactions Learning With Random Weights
Jan 13, 2025



Pedestrian trajectory prediction is a critical technology in the evolution of self-driving cars toward complete artificial intelligence. Over recent years, focusing on the trajectories of pedestrians to model their social interactions has surged with great interest in more accurate trajectory predictions. However, existing methods for modeling pedestrian social interactions rely on pre-defined rules, struggling to capture non-explicit social interactions. In this work, we propose a novel framework named DTGAN, which extends the application of Generative Adversarial Networks (GANs) to graph sequence data, with the primary objective of automatically capturing implicit social interactions and achieving precise predictions of pedestrian trajectory. DTGAN innovatively incorporates random weights within each graph to eliminate the need for pre-defined interaction rules. We further enhance the performance of DTGAN by exploring diverse task loss functions during adversarial training, which yields improvements of 16.7\% and 39.3\% on metrics ADE and FDE, respectively. The effectiveness and accuracy of our framework are verified on two public datasets. The experimental results show that our proposed DTGAN achieves superior performance and is well able to understand pedestrians' intentions.
Who Walks With You Matters: Perceiving Social Interactions with Groups for Pedestrian Trajectory Prediction
Dec 03, 2024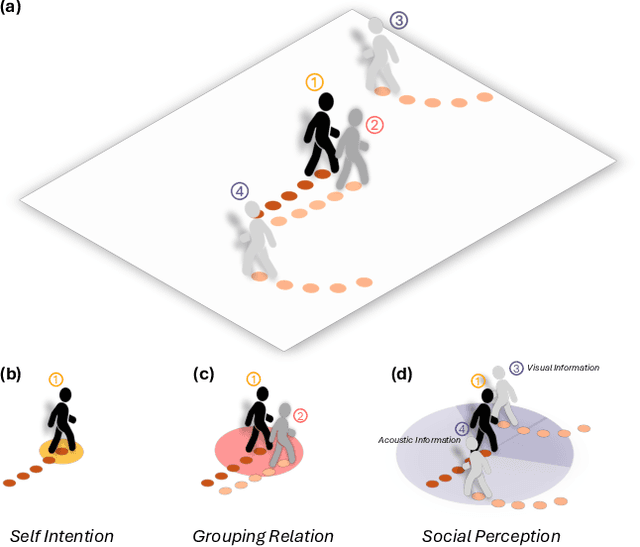
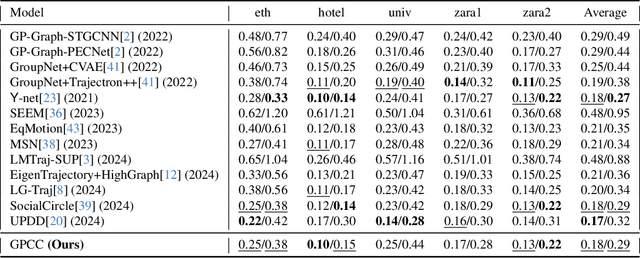
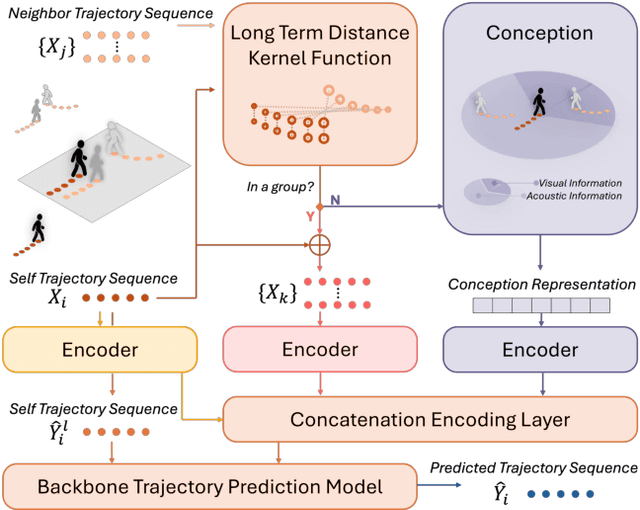
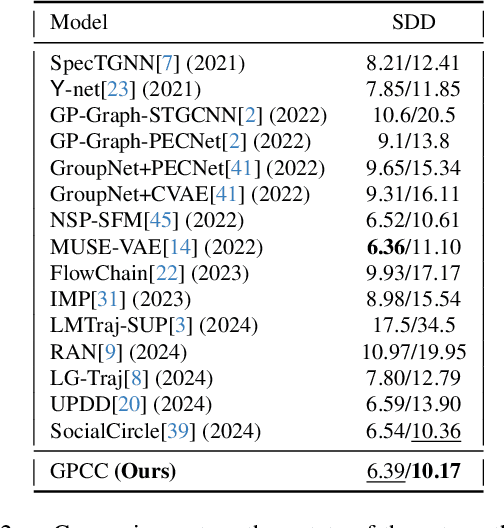
Understanding and anticipating human movement has become more critical and challenging in diverse applications such as autonomous driving and surveillance. The complex interactions brought by different relations between agents are a crucial reason that poses challenges to this task. Researchers have put much effort into designing a system using rule-based or data-based models to extract and validate the patterns between pedestrian trajectories and these interactions, which has not been adequately addressed yet. Inspired by how humans perceive social interactions with different level of relations to themself, this work proposes the GrouP ConCeption (short for GPCC) model composed of the Group method, which categorizes nearby agents into either group members or non-group members based on a long-term distance kernel function, and the Conception module, which perceives both visual and acoustic information surrounding the target agent. Evaluated across multiple datasets, the GPCC model demonstrates significant improvements in trajectory prediction accuracy, validating its effectiveness in modeling both social and individual dynamics. The qualitative analysis also indicates that the GPCC framework successfully leverages grouping and perception cues human-like intuitively to validate the proposed model's explainability in pedestrian trajectory forecasting.
Resonance: Learning to Predict Social-Aware Pedestrian Trajectories as Co-Vibrations
Dec 03, 2024



Learning to forecast the trajectories of intelligent agents like pedestrians has caught more researchers' attention. Despite researchers' efforts, it remains a challenge to accurately account for social interactions among agents when forecasting, and in particular, to simulate such social modifications to future trajectories in an explainable and decoupled way. Inspired by the resonance phenomenon of vibration systems, we propose the Resonance (short for Re) model to forecast pedestrian trajectories as co-vibrations, and regard that social interactions are associated with spectral properties of agents' trajectories. It forecasts future trajectories as three distinct vibration terms to represent agents' future plans from different perspectives in a decoupled way. Also, agents' social interactions and how they modify scheduled trajectories will be considered in a resonance-like manner by learning the similarities of their trajectory spectrums. Experiments on multiple datasets, whether pedestrian or vehicle, have verified the usefulness of our method both quantitatively and qualitatively.
Ranking Distillation for Open-Ended Video Question Answering with Insufficient Labels
Mar 21, 2024
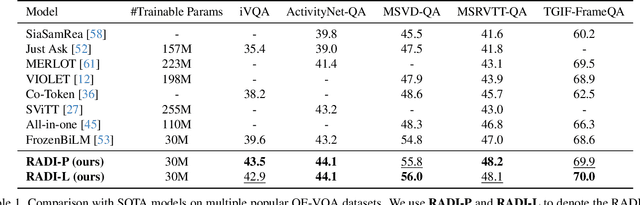
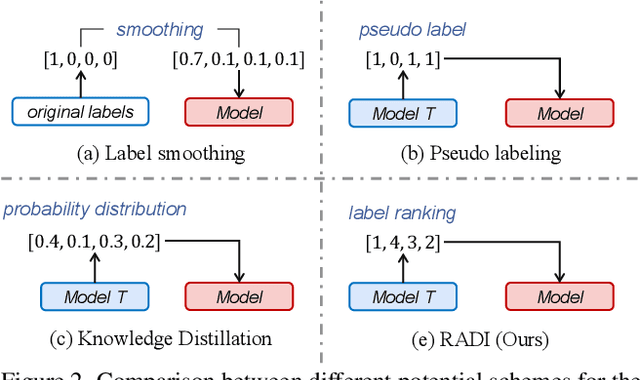
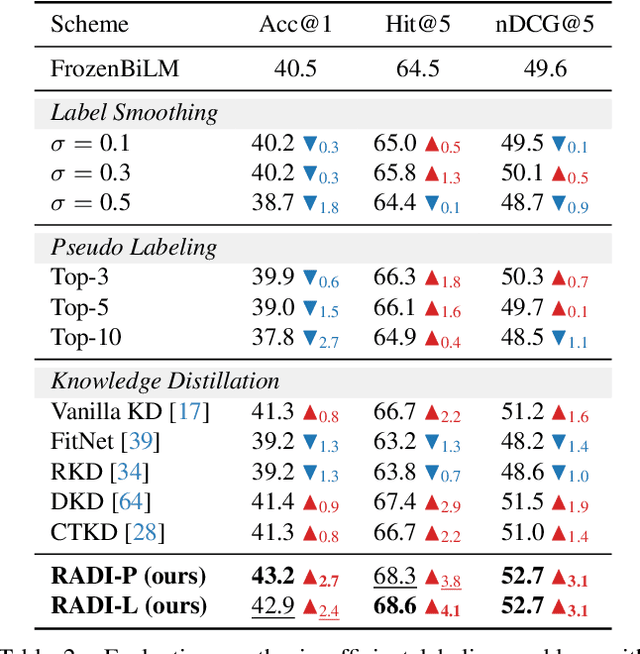
This paper focuses on open-ended video question answering, which aims to find the correct answers from a large answer set in response to a video-related question. This is essentially a multi-label classification task, since a question may have multiple answers. However, due to annotation costs, the labels in existing benchmarks are always extremely insufficient, typically one answer per question. As a result, existing works tend to directly treat all the unlabeled answers as negative labels, leading to limited ability for generalization. In this work, we introduce a simple yet effective ranking distillation framework (RADI) to mitigate this problem without additional manual annotation. RADI employs a teacher model trained with incomplete labels to generate rankings for potential answers, which contain rich knowledge about label priority as well as label-associated visual cues, thereby enriching the insufficient labeling information. To avoid overconfidence in the imperfect teacher model, we further present two robust and parameter-free ranking distillation approaches: a pairwise approach which introduces adaptive soft margins to dynamically refine the optimization constraints on various pairwise rankings, and a listwise approach which adopts sampling-based partial listwise learning to resist the bias in teacher ranking. Extensive experiments on five popular benchmarks consistently show that both our pairwise and listwise RADIs outperform state-of-the-art methods. Further analysis demonstrates the effectiveness of our methods on the insufficient labeling problem.
SocialCircle: Learning the Angle-based Social Interaction Representation for Pedestrian Trajectory Prediction
Oct 09, 2023Analyzing and forecasting trajectories of agents like pedestrians and cars in complex scenes has become more and more significant in many intelligent systems and applications. The diversity and uncertainty in socially interactive behaviors among a rich variety of agents make this task more challenging than other deterministic computer vision tasks. Researchers have made a lot of efforts to quantify the effects of these interactions on future trajectories through different mathematical models and network structures, but this problem has not been well solved. Inspired by marine animals that localize the positions of their companions underwater through echoes, we build a new anglebased trainable social representation, named SocialCircle, for continuously reflecting the context of social interactions at different angular orientations relative to the target agent. We validate the effect of the proposed SocialCircle by training it along with several newly released trajectory prediction models, and experiments show that the SocialCircle not only quantitatively improves the prediction performance, but also qualitatively helps better consider social interactions when forecasting pedestrian trajectories in a way that is consistent with human intuitions.
Efficient Backdoor Attacks for Deep Neural Networks in Real-world Scenarios
Jun 14, 2023



Recent deep neural networks (DNNs) have come to rely on vast amounts of training data, providing an opportunity for malicious attackers to exploit and contaminate the data to carry out backdoor attacks. These attacks significantly undermine the reliability of DNNs. However, existing backdoor attack methods make unrealistic assumptions, assuming that all training data comes from a single source and that attackers have full access to the training data. In this paper, we address this limitation by introducing a more realistic attack scenario where victims collect data from multiple sources, and attackers cannot access the complete training data. We refer to this scenario as data-constrained backdoor attacks. In such cases, previous attack methods suffer from severe efficiency degradation due to the entanglement between benign and poisoning features during the backdoor injection process. To tackle this problem, we propose a novel approach that leverages the pre-trained Contrastive Language-Image Pre-Training (CLIP) model. We introduce three CLIP-based technologies from two distinct streams: Clean Feature Suppression, which aims to suppress the influence of clean features to enhance the prominence of poisoning features, and Poisoning Feature Augmentation, which focuses on augmenting the presence and impact of poisoning features to effectively manipulate the model's behavior. To evaluate the effectiveness, harmlessness to benign accuracy, and stealthiness of our method, we conduct extensive experiments on 3 target models, 3 datasets, and over 15 different settings. The results demonstrate remarkable improvements, with some settings achieving over 100% improvement compared to existing attacks in data-constrained scenarios. Our research contributes to addressing the limitations of existing methods and provides a practical and effective solution for data-constrained backdoor attacks.
A Proxy-Free Strategy for Practically Improving the Poisoning Efficiency in Backdoor Attacks
Jun 14, 2023



Poisoning efficiency is a crucial factor in poisoning-based backdoor attacks. Attackers prefer to use as few poisoned samples as possible to achieve the same level of attack strength, in order to remain undetected. Efficient triggers have significantly improved poisoning efficiency, but there is still room for improvement. Recently, selecting efficient samples has shown promise, but it requires a proxy backdoor injection task to find an efficient poisoned sample set, which can lead to performance degradation if the proxy attack settings are different from the actual settings used by the victims. In this paper, we propose a novel Proxy-Free Strategy (PFS) that selects efficient poisoned samples based on individual similarity and set diversity, effectively addressing this issue. We evaluate the proposed strategy on several datasets, triggers, poisoning ratios, architectures, and training hyperparameters. Our experimental results demonstrate that PFS achieves higher backdoor attack strength while x500 faster than previous proxy-based selection approaches.