 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrototype-Guided Curriculum Learning for Zero-Shot Learning
Aug 11, 2025In Zero-Shot Learning (ZSL), embedding-based methods enable knowledge transfer from seen to unseen classes by learning a visual-semantic mapping from seen-class images to class-level semantic prototypes (e.g., attributes). However, these semantic prototypes are manually defined and may introduce noisy supervision for two main reasons: (i) instance-level mismatch: variations in perspective, occlusion, and annotation bias will cause discrepancies between individual sample and the class-level semantic prototypes; and (ii) class-level imprecision: the manually defined semantic prototypes may not accurately reflect the true semantics of the class. Consequently, the visual-semantic mapping will be misled, reducing the effectiveness of knowledge transfer to unseen classes. In this work, we propose a prototype-guided curriculum learning framework (dubbed as CLZSL), which mitigates instance-level mismatches through a Prototype-Guided Curriculum Learning (PCL) module and addresses class-level imprecision via a Prototype Update (PUP) module. Specifically, the PCL module prioritizes samples with high cosine similarity between their visual mappings and the class-level semantic prototypes, and progressively advances to less-aligned samples, thereby reducing the interference of instance-level mismatches to achieve accurate visual-semantic mapping. Besides, the PUP module dynamically updates the class-level semantic prototypes by leveraging the visual mappings learned from instances, thereby reducing class-level imprecision and further improving the visual-semantic mapping. Experiments were conducted on standard benchmark datasets-AWA2, SUN, and CUB-to verify the effectiveness of our method.
Semi-supervised Anomaly Detection with Extremely Limited Labels in Dynamic Graphs
Jan 25, 2025Semi-supervised graph anomaly detection (GAD) has recently received increasing attention, which aims to distinguish anomalous patterns from graphs under the guidance of a moderate amount of labeled data and a large volume of unlabeled data. Although these proposed semi-supervised GAD methods have achieved great success, their superior performance will be seriously degraded when the provided labels are extremely limited due to some unpredictable factors. Besides, the existing methods primarily focus on anomaly detection in static graphs, and little effort was paid to consider the continuous evolution characteristic of graphs over time (dynamic graphs). To address these challenges, we propose a novel GAD framework (EL$^{2}$-DGAD) to tackle anomaly detection problem in dynamic graphs with extremely limited labels. Specifically, a transformer-based graph encoder model is designed to more effectively preserve evolving graph structures beyond the local neighborhood. Then, we incorporate an ego-context hypersphere classification loss to classify temporal interactions according to their structure and temporal neighborhoods while ensuring the normal samples are mapped compactly against anomalous data. Finally, the above loss is further augmented with an ego-context contrasting module which utilizes unlabeled data to enhance model generalization. Extensive experiments on four datasets and three label rates demonstrate the effectiveness of the proposed method in comparison to the existing GAD methods.
Who Walks With You Matters: Perceiving Social Interactions with Groups for Pedestrian Trajectory Prediction
Dec 03, 2024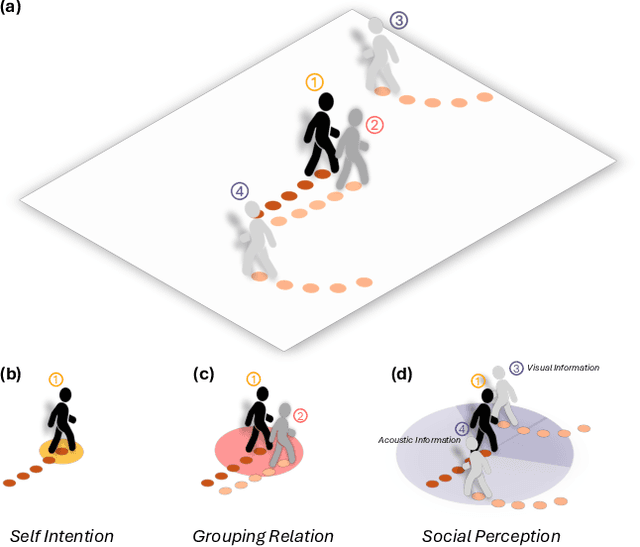
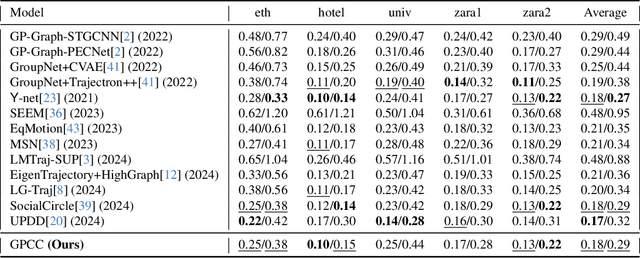
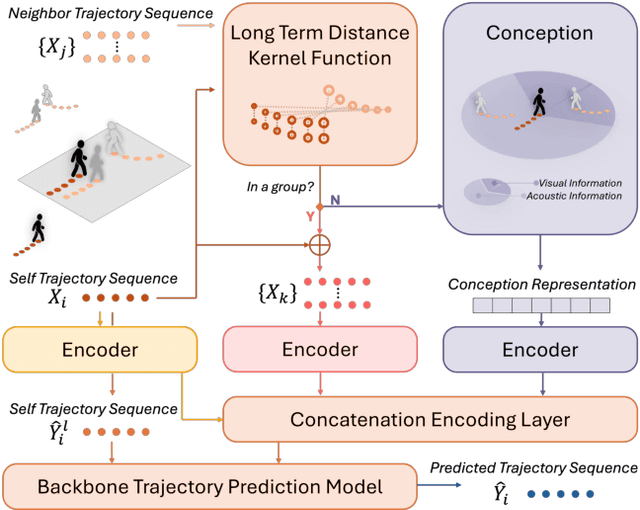
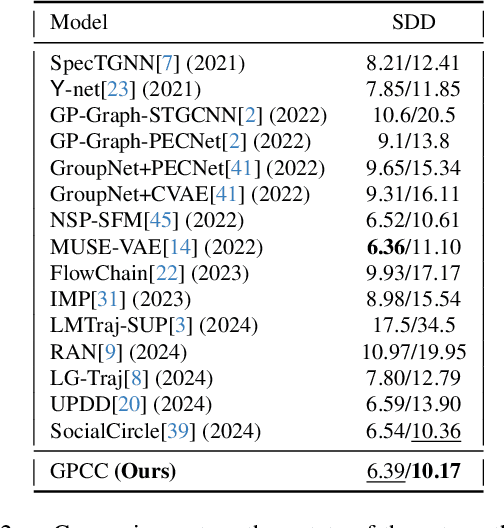
Understanding and anticipating human movement has become more critical and challenging in diverse applications such as autonomous driving and surveillance. The complex interactions brought by different relations between agents are a crucial reason that poses challenges to this task. Researchers have put much effort into designing a system using rule-based or data-based models to extract and validate the patterns between pedestrian trajectories and these interactions, which has not been adequately addressed yet. Inspired by how humans perceive social interactions with different level of relations to themself, this work proposes the GrouP ConCeption (short for GPCC) model composed of the Group method, which categorizes nearby agents into either group members or non-group members based on a long-term distance kernel function, and the Conception module, which perceives both visual and acoustic information surrounding the target agent. Evaluated across multiple datasets, the GPCC model demonstrates significant improvements in trajectory prediction accuracy, validating its effectiveness in modeling both social and individual dynamics. The qualitative analysis also indicates that the GPCC framework successfully leverages grouping and perception cues human-like intuitively to validate the proposed model's explainability in pedestrian trajectory forecasting.
Towards Cross-domain Few-shot Graph Anomaly Detection
Oct 11, 2024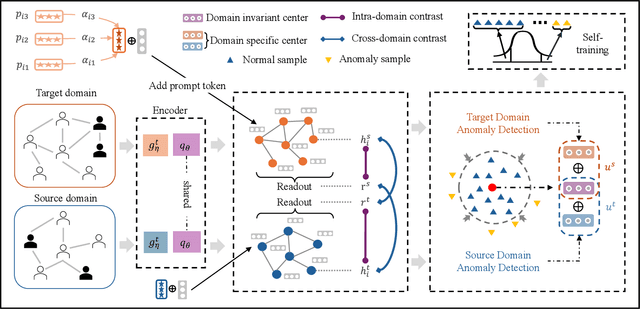
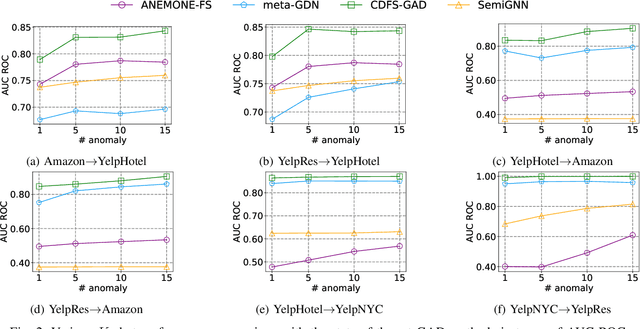
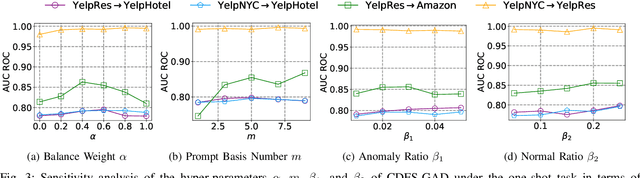
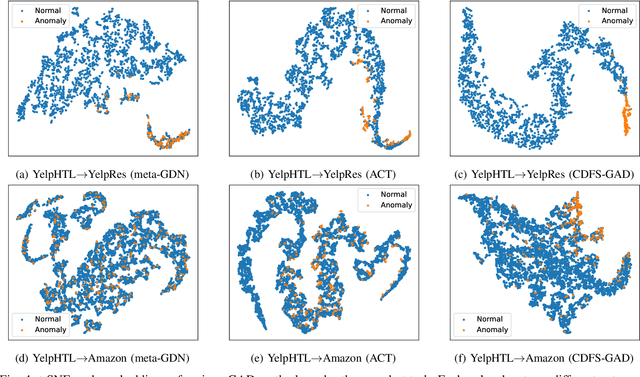
Few-shot graph anomaly detection (GAD) has recently garnered increasing attention, which aims to discern anomalous patterns among abundant unlabeled test nodes under the guidance of a limited number of labeled training nodes. Existing few-shot GAD approaches typically adopt meta-training methods trained on richly labeled auxiliary networks to facilitate rapid adaptation to target networks that possess sparse labels. However, these proposed methods often assume that the auxiliary and target networks exist in the same data distributions-an assumption rarely holds in practical settings. This paper explores a more prevalent and complex scenario of cross-domain few-shot GAD, where the goal is to identify anomalies within sparsely labeled target graphs using auxiliary graphs from a related, yet distinct domain. The challenge here is nontrivial owing to inherent data distribution discrepancies between the source and target domains, compounded by the uncertainties of sparse labeling in the target domain. In this paper, we propose a simple and effective framework, termed CDFS-GAD, specifically designed to tackle the aforementioned challenges. CDFS-GAD first introduces a domain-adaptive graph contrastive learning module, which is aimed at enhancing cross-domain feature alignment. Then, a prompt tuning module is further designed to extract domain-specific features tailored to each domain. Moreover, a domain-adaptive hypersphere classification loss is proposed to enhance the discrimination between normal and anomalous instances under minimal supervision, utilizing domain-sensitive norms. Lastly, a self-training strategy is introduced to further refine the predicted scores, enhancing its reliability in few-shot settings. Extensive experiments on twelve real-world cross-domain data pairs demonstrate the effectiveness of the proposed CDFS-GAD framework in comparison to various existing GAD methods.
Generalized Sparse Additive Model with Unknown Link Function
Oct 08, 2024



Generalized additive models (GAM) have been successfully applied to high dimensional data analysis. However, most existing methods cannot simultaneously estimate the link function, the component functions and the variable interaction. To alleviate this problem, we propose a new sparse additive model, named generalized sparse additive model with unknown link function (GSAMUL), in which the component functions are estimated by B-spline basis and the unknown link function is estimated by a multi-layer perceptron (MLP) network. Furthermore, $\ell_{2,1}$-norm regularizer is used for variable selection. The proposed GSAMUL can realize both variable selection and hidden interaction. We integrate this estimation into a bilevel optimization problem, where the data is split into training set and validation set. In theory, we provide the guarantees about the convergence of the approximate procedure. In applications, experimental evaluations on both synthetic and real world data sets consistently validate the effectiveness of the proposed approach.
What Happens Without Background? Constructing Foreground-Only Data for Fine-Grained Tasks
Aug 04, 2024



Fine-grained recognition, a pivotal task in visual signal processing, aims to distinguish between similar subclasses based on discriminative information present in samples. However, prevailing methods often erroneously focus on background areas, neglecting the capture of genuinely effective discriminative information from the subject, thus impeding practical application. To facilitate research into the impact of background noise on models and enhance their ability to concentrate on the subject's discriminative features, we propose an engineered pipeline that leverages the capabilities of SAM and Detic to create fine-grained datasets with only foreground subjects, devoid of background. Extensive cross-experiments validate this approach as a preprocessing step prior to training, enhancing algorithmic performance and holding potential for further modal expansion of the data.
Detail Reinforcement Diffusion Model: Augmentation Fine-Grained Visual Categorization in Few-Shot Conditions
Sep 15, 2023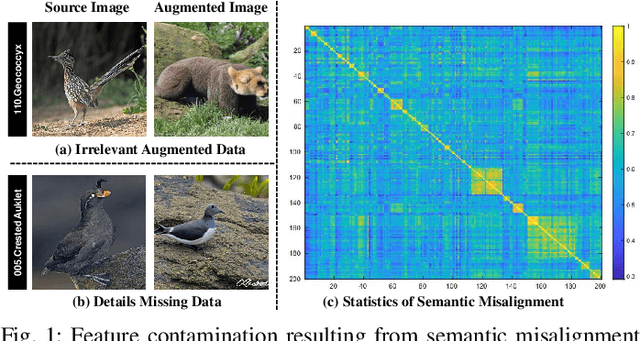
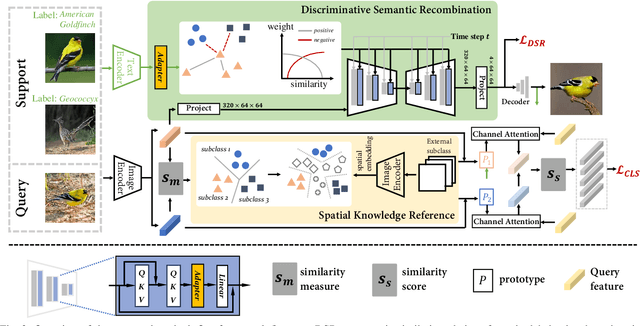
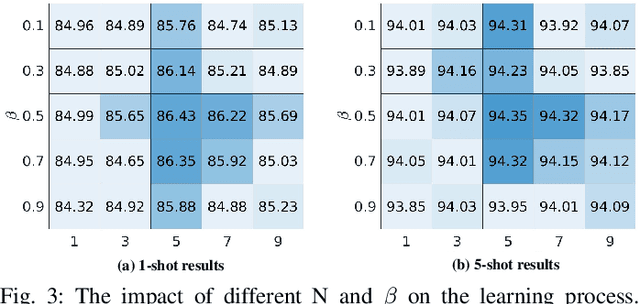

The challenge in fine-grained visual categorization lies in how to explore the subtle differences between different subclasses and achieve accurate discrimination. Previous research has relied on large-scale annotated data and pre-trained deep models to achieve the objective. However, when only a limited amount of samples is available, similar methods may become less effective. Diffusion models have been widely adopted in data augmentation due to their outstanding diversity in data generation. However, the high level of detail required for fine-grained images makes it challenging for existing methods to be directly employed. To address this issue, we propose a novel approach termed the detail reinforcement diffusion model~(DRDM), which leverages the rich knowledge of large models for fine-grained data augmentation and comprises two key components including discriminative semantic recombination (DSR) and spatial knowledge reference~(SKR). Specifically, DSR is designed to extract implicit similarity relationships from the labels and reconstruct the semantic mapping between labels and instances, which enables better discrimination of subtle differences between different subclasses. Furthermore, we introduce the SKR module, which incorporates the distributions of different datasets as references in the feature space. This allows the SKR to aggregate the high-dimensional distribution of subclass features in few-shot FGVC tasks, thus expanding the decision boundary. Through these two critical components, we effectively utilize the knowledge from large models to address the issue of data scarcity, resulting in improved performance for fine-grained visual recognition tasks. Extensive experiments demonstrate the consistent performance gain offered by our DRDM.
Towards Unsupervised Graph Completion Learning on Graphs with Features and Structure Missing
Sep 06, 2023



In recent years, graph neural networks (GNN) have achieved significant developments in a variety of graph analytical tasks. Nevertheless, GNN's superior performance will suffer from serious damage when the collected node features or structure relationships are partially missing owning to numerous unpredictable factors. Recently emerged graph completion learning (GCL) has received increasing attention, which aims to reconstruct the missing node features or structure relationships under the guidance of a specifically supervised task. Although these proposed GCL methods have made great success, they still exist the following problems: the reliance on labels, the bias of the reconstructed node features and structure relationships. Besides, the generalization ability of the existing GCL still faces a huge challenge when both collected node features and structure relationships are partially missing at the same time. To solve the above issues, we propose a more general GCL framework with the aid of self-supervised learning for improving the task performance of the existing GNN variants on graphs with features and structure missing, termed unsupervised GCL (UGCL). Specifically, to avoid the mismatch between missing node features and structure during the message-passing process of GNN, we separate the feature reconstruction and structure reconstruction and design its personalized model in turn. Then, a dual contrastive loss on the structure level and feature level is introduced to maximize the mutual information of node representations from feature reconstructing and structure reconstructing paths for providing more supervision signals. Finally, the reconstructed node features and structure can be applied to the downstream node classification task. Extensive experiments on eight datasets, three GNN variants and five missing rates demonstrate the effectiveness of our proposed method.
Another Vertical View: A Hierarchical Network for Heterogeneous Trajectory Prediction via Spectrums
Apr 11, 2023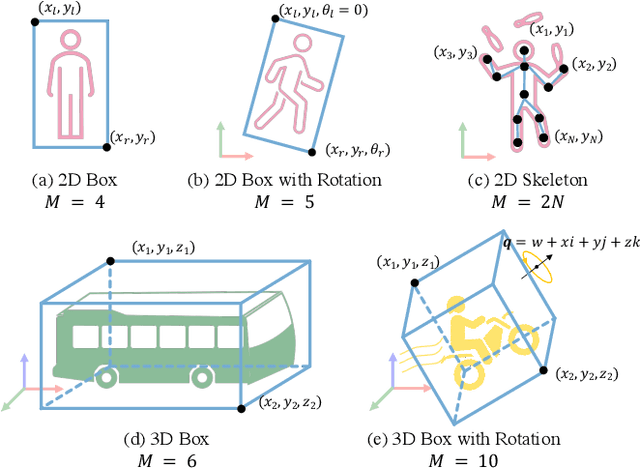

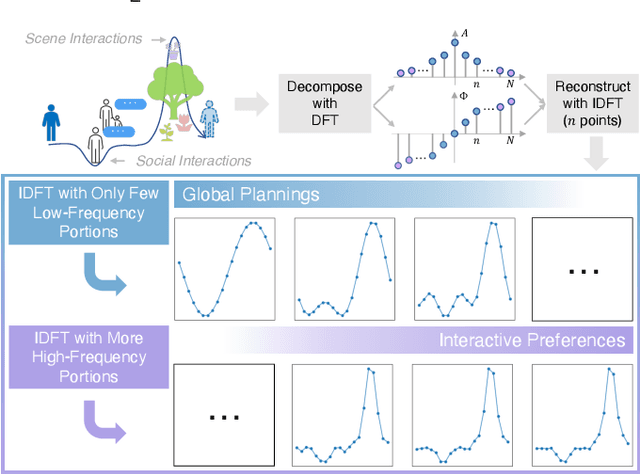
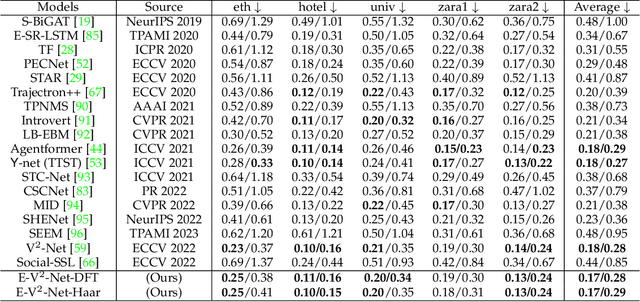
With the fast development of AI-related techniques, the applications of trajectory prediction are no longer limited to easier scenes and trajectories. More and more heterogeneous trajectories with different representation forms, such as 2D or 3D coordinates, 2D or 3D bounding boxes, and even high-dimensional human skeletons, need to be analyzed and forecasted. Among these heterogeneous trajectories, interactions between different elements within a frame of trajectory, which we call the ``Dimension-Wise Interactions'', would be more complex and challenging. However, most previous approaches focus mainly on a specific form of trajectories, which means these methods could not be used to forecast heterogeneous trajectories, not to mention the dimension-wise interaction. Besides, previous methods mostly treat trajectory prediction as a normal time sequence generation task, indicating that these methods may require more work to directly analyze agents' behaviors and social interactions at different temporal scales. In this paper, we bring a new ``view'' for trajectory prediction to model and forecast trajectories hierarchically according to different frequency portions from the spectral domain to learn to forecast trajectories by considering their frequency responses. Moreover, we try to expand the current trajectory prediction task by introducing the dimension $M$ from ``another view'', thus extending its application scenarios to heterogeneous trajectories vertically. Finally, we adopt the bilinear structure to fuse two factors, including the frequency response and the dimension-wise interaction, to forecast heterogeneous trajectories via spectrums hierarchically in a generic way. Experiments show that the proposed model outperforms most state-of-the-art methods on ETH-UCY, Stanford Drone Dataset and nuScenes with heterogeneous trajectories, including 2D coordinates, 2D and 3D bounding boxes.
Semantic-visual Guided Transformer for Few-shot Class-incremental Learning
Mar 27, 2023



Few-shot class-incremental learning (FSCIL) has recently attracted extensive attention in various areas. Existing FSCIL methods highly depend on the robustness of the feature backbone pre-trained on base classes. In recent years, different Transformer variants have obtained significant processes in the feature representation learning of massive fields. Nevertheless, the progress of the Transformer in FSCIL scenarios has not achieved the potential promised in other fields so far. In this paper, we develop a semantic-visual guided Transformer (SV-T) to enhance the feature extracting capacity of the pre-trained feature backbone on incremental classes. Specifically, we first utilize the visual (image) labels provided by the base classes to supervise the optimization of the Transformer. And then, a text encoder is introduced to automatically generate the corresponding semantic (text) labels for each image from the base classes. Finally, the constructed semantic labels are further applied to the Transformer for guiding its hyperparameters updating. Our SV-T can take full advantage of more supervision information from base classes and further enhance the training robustness of the feature backbone. More importantly, our SV-T is an independent method, which can directly apply to the existing FSCIL architectures for acquiring embeddings of various incremental classes. Extensive experiments on three benchmarks, two FSCIL architectures, and two Transformer variants show that our proposed SV-T obtains a significant improvement in comparison to the existing state-of-the-art FSCIL methods.