 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Guided Hypergraph Feature Propagation for Semi-supervised Classification with Missing Node Features
Feb 16, 2023

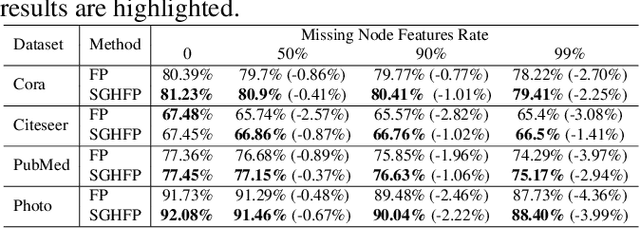

Graph neural networks (GNNs) with missing node features have recently received increasing interest. Such missing node features seriously hurt the performance of the existing GNNs. Some recent methods have been proposed to reconstruct the missing node features by the information propagation among nodes with known and unknown attributes. Although these methods have achieved superior performance, how to exactly exploit the complex data correlations among nodes to reconstruct missing node features is still a great challenge. To solve the above problem, we propose a self-supervised guided hypergraph feature propagation (SGHFP). Specifically, the feature hypergraph is first generated according to the node features with missing information. And then, the reconstructed node features produced by the previous iteration are fed to a two-layer GNNs to construct a pseudo-label hypergraph. Before each iteration, the constructed feature hypergraph and pseudo-label hypergraph are fused effectively, which can better preserve the higher-order data correlations among nodes. After then, we apply the fused hypergraph to the feature propagation for reconstructing missing features. Finally, the reconstructed node features by multi-iteration optimization are applied to the downstream semi-supervised classification task. Extensive experiments demonstrate that the proposed SGHFP outperforms the existing semi-supervised classification with missing node feature methods.
Modelling the semantics of text in complex document layouts using graph transformer networks
Feb 18, 2022
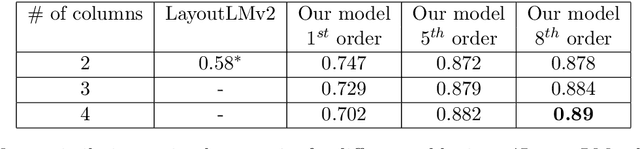
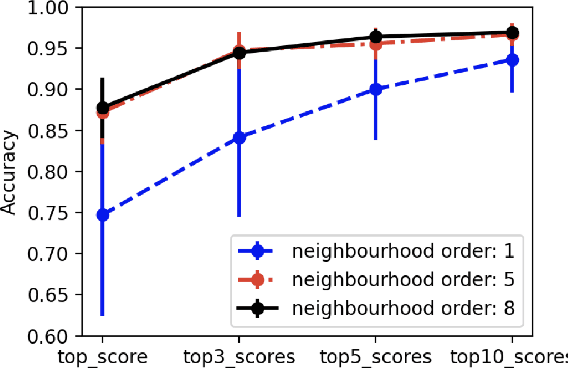
Representing structured text from complex documents typically calls for different machine learning techniques, such as language models for paragraphs and convolutional neural networks (CNNs) for table extraction, which prohibits drawing links between text spans from different content types. In this article we propose a model that approximates the human reading pattern of a document and outputs a unique semantic representation for every text span irrespective of the content type they are found in. We base our architecture on a graph representation of the structured text, and we demonstrate that not only can we retrieve semantically similar information across documents but also that the embedding space we generate captures useful semantic information, similar to language models that work only on text sequences.