 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-visual Guided Transformer for Few-shot Class-incremental Learning
Mar 27, 2023



Few-shot class-incremental learning (FSCIL) has recently attracted extensive attention in various areas. Existing FSCIL methods highly depend on the robustness of the feature backbone pre-trained on base classes. In recent years, different Transformer variants have obtained significant processes in the feature representation learning of massive fields. Nevertheless, the progress of the Transformer in FSCIL scenarios has not achieved the potential promised in other fields so far. In this paper, we develop a semantic-visual guided Transformer (SV-T) to enhance the feature extracting capacity of the pre-trained feature backbone on incremental classes. Specifically, we first utilize the visual (image) labels provided by the base classes to supervise the optimization of the Transformer. And then, a text encoder is introduced to automatically generate the corresponding semantic (text) labels for each image from the base classes. Finally, the constructed semantic labels are further applied to the Transformer for guiding its hyperparameters updating. Our SV-T can take full advantage of more supervision information from base classes and further enhance the training robustness of the feature backbone. More importantly, our SV-T is an independent method, which can directly apply to the existing FSCIL architectures for acquiring embeddings of various incremental classes. Extensive experiments on three benchmarks, two FSCIL architectures, and two Transformer variants show that our proposed SV-T obtains a significant improvement in comparison to the existing state-of-the-art FSCIL methods.
Self-supervised Guided Hypergraph Feature Propagation for Semi-supervised Classification with Missing Node Features
Feb 16, 2023

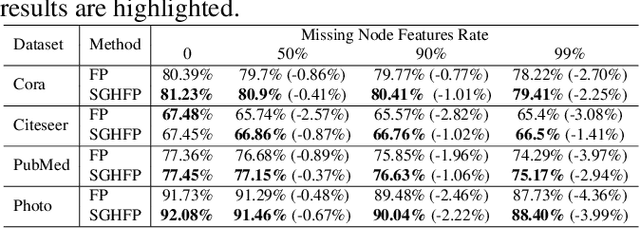

Graph neural networks (GNNs) with missing node features have recently received increasing interest. Such missing node features seriously hurt the performance of the existing GNNs. Some recent methods have been proposed to reconstruct the missing node features by the information propagation among nodes with known and unknown attributes. Although these methods have achieved superior performance, how to exactly exploit the complex data correlations among nodes to reconstruct missing node features is still a great challenge. To solve the above problem, we propose a self-supervised guided hypergraph feature propagation (SGHFP). Specifically, the feature hypergraph is first generated according to the node features with missing information. And then, the reconstructed node features produced by the previous iteration are fed to a two-layer GNNs to construct a pseudo-label hypergraph. Before each iteration, the constructed feature hypergraph and pseudo-label hypergraph are fused effectively, which can better preserve the higher-order data correlations among nodes. After then, we apply the fused hypergraph to the feature propagation for reconstructing missing features. Finally, the reconstructed node features by multi-iteration optimization are applied to the downstream semi-supervised classification task. Extensive experiments demonstrate that the proposed SGHFP outperforms the existing semi-supervised classification with missing node feature methods.
Acoustic SLAM based on the Direction-of-Arrival and the Direct-to-Reverberant Energy Ratio
Sep 22, 2022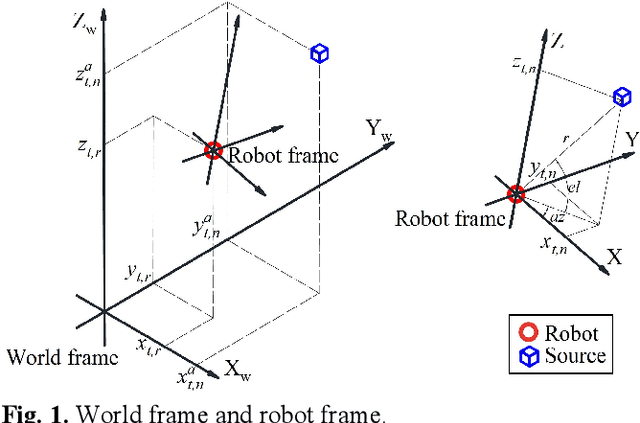
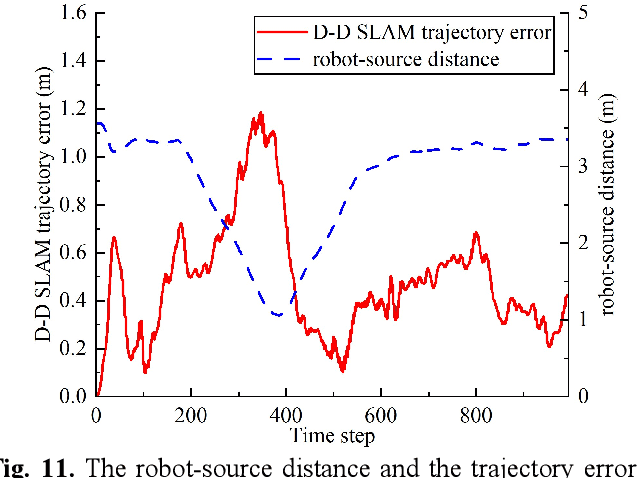
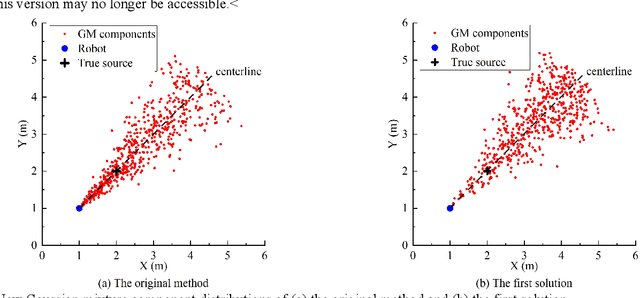
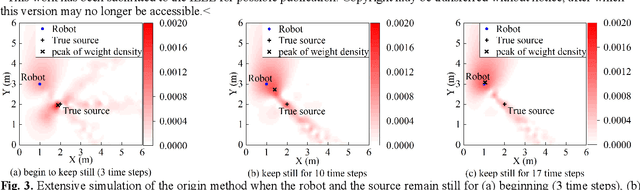
This paper proposes a new method that fuses acoustic measurements in the reverberation field and low-accuracy inertial measurement unit (IMU) motion reports for simultaneous localization and mapping (SLAM). Different from existing studies that only use acoustic data for direction-of-arrival (DoA) estimates, the source's distance from sensors is calculated with the direct-to-reverberant energy ratio (DRR) and applied as a new constraint to eliminate the nonlinear noise from motion reports. A particle filter is applied to estimate the critical distance, which is key for associating the source's distance with the DRR. A keyframe method is used to eliminate the deviation of the source position estimation toward the robot. The proposed DoA-DRR acoustic SLAM (D-D SLAM) is designed for three-dimensional motion and is suitable for most robots. The method is the first acoustic SLAM algorithm that has been validated on a real-world indoor scene dataset that contains only acoustic data and IMU measurements. Compared with previous methods, D-D SLAM has acceptable performance in locating the robot and building a source map from a real-world indoor dataset. The average location accuracy is 0.48 m, while the source position error converges to less than 0.25 m within 2.8 s. These results prove the effectiveness of D-D SLAM in real-world indoor scenes, which may be especially useful in search and rescue missions after disasters where the environment is foggy, i.e., unsuitable for light or laser irradiation.