 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMutually Causal Semantic Distillation Network for Zero-Shot Learning
Mar 18, 2026Zero-shot learning (ZSL) aims to recognize the unseen classes in the open-world guided by the side-information (e.g., attributes). Its key task is how to infer the latent semantic knowledge between visual and attribute features on seen classes, and thus conducting a desirable semantic knowledge transfer from seen classes to unseen ones. Prior works simply utilize unidirectional attention within a weakly-supervised manner to learn the spurious and limited latent semantic representations, which fail to effectively discover the intrinsic semantic knowledge (e.g., attribute semantic) between visual and attribute features. To solve the above challenges, we propose a mutually causal semantic distillation network (termed MSDN++) to distill the intrinsic and sufficient semantic representations for ZSL. MSDN++ consists of an attribute$\rightarrow$visual causal attention sub-net that learns attribute-based visual features, and a visual$\rightarrow$attribute causal attention sub-net that learns visual-based attribute features. The causal attentions encourages the two sub-nets to learn causal vision-attribute associations for representing reliable features with causal visual/attribute learning. With the guidance of semantic distillation loss, the two mutual attention sub-nets learn collaboratively and teach each other throughout the training process. Extensive experiments on three widely-used benchmark datasets (e.g., CUB, SUN, AWA2, and FLO) show that our MSDN++ yields significant improvements over the strong baselines, leading to new state-of-the-art performances.
Discriminative Image Generation with Diffusion Models for Zero-Shot Learning
Dec 23, 2024



Generative Zero-Shot Learning (ZSL) methods synthesize class-related features based on predefined class semantic prototypes, showcasing superior performance. However, this feature generation paradigm falls short of providing interpretable insights. In addition, existing approaches rely on semantic prototypes annotated by human experts, which exhibit a significant limitation in their scalability to generalized scenes. To overcome these deficiencies, a natural solution is to generate images for unseen classes using text prompts. To this end, We present DIG-ZSL, a novel Discriminative Image Generation framework for Zero-Shot Learning. Specifically, to ensure the generation of discriminative images for training an effective ZSL classifier, we learn a discriminative class token (DCT) for each unseen class under the guidance of a pre-trained category discrimination model (CDM). Harnessing DCTs, we can generate diverse and high-quality images, which serve as informative unseen samples for ZSL tasks. In this paper, the extensive experiments and visualizations on four datasets show that our DIG-ZSL: (1) generates diverse and high-quality images, (2) outperforms previous state-of-the-art nonhuman-annotated semantic prototype-based methods by a large margin, and (3) achieves comparable or better performance than baselines that leverage human-annotated semantic prototypes. The codes will be made available upon acceptance of the paper.
Visual-Augmented Dynamic Semantic Prototype for Generative Zero-Shot Learning
Apr 23, 2024



Generative Zero-shot learning (ZSL) learns a generator to synthesize visual samples for unseen classes, which is an effective way to advance ZSL. However, existing generative methods rely on the conditions of Gaussian noise and the predefined semantic prototype, which limit the generator only optimized on specific seen classes rather than characterizing each visual instance, resulting in poor generalizations (\textit{e.g.}, overfitting to seen classes). To address this issue, we propose a novel Visual-Augmented Dynamic Semantic prototype method (termed VADS) to boost the generator to learn accurate semantic-visual mapping by fully exploiting the visual-augmented knowledge into semantic conditions. In detail, VADS consists of two modules: (1) Visual-aware Domain Knowledge Learning module (VDKL) learns the local bias and global prior of the visual features (referred to as domain visual knowledge), which replace pure Gaussian noise to provide richer prior noise information; (2) Vision-Oriented Semantic Updation module (VOSU) updates the semantic prototype according to the visual representations of the samples. Ultimately, we concatenate their output as a dynamic semantic prototype, which serves as the condition of the generator. Extensive experiments demonstrate that our VADS achieves superior CZSL and GZSL performances on three prominent datasets and outperforms other state-of-the-art methods with averaging increases by 6.4\%, 5.9\% and 4.2\% on SUN, CUB and AWA2, respectively.
Detail Reinforcement Diffusion Model: Augmentation Fine-Grained Visual Categorization in Few-Shot Conditions
Sep 15, 2023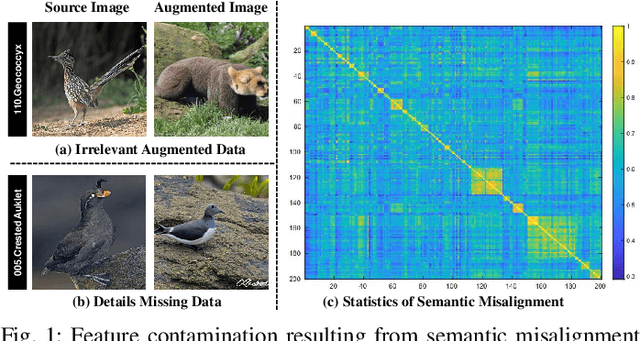
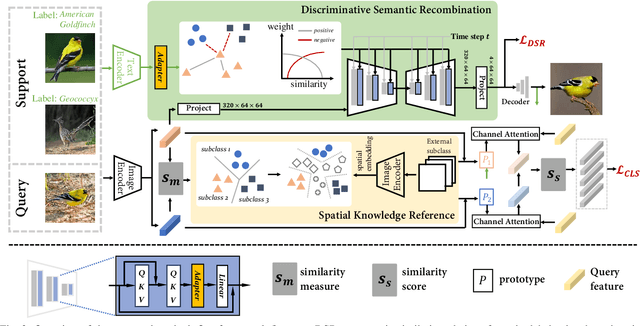
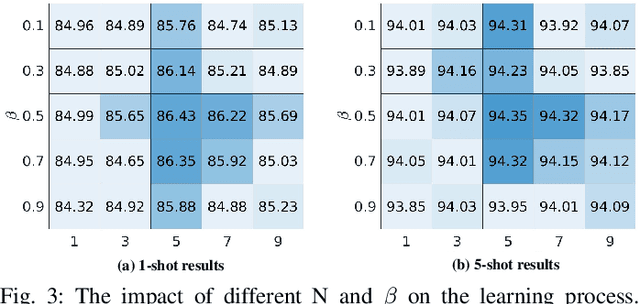

The challenge in fine-grained visual categorization lies in how to explore the subtle differences between different subclasses and achieve accurate discrimination. Previous research has relied on large-scale annotated data and pre-trained deep models to achieve the objective. However, when only a limited amount of samples is available, similar methods may become less effective. Diffusion models have been widely adopted in data augmentation due to their outstanding diversity in data generation. However, the high level of detail required for fine-grained images makes it challenging for existing methods to be directly employed. To address this issue, we propose a novel approach termed the detail reinforcement diffusion model~(DRDM), which leverages the rich knowledge of large models for fine-grained data augmentation and comprises two key components including discriminative semantic recombination (DSR) and spatial knowledge reference~(SKR). Specifically, DSR is designed to extract implicit similarity relationships from the labels and reconstruct the semantic mapping between labels and instances, which enables better discrimination of subtle differences between different subclasses. Furthermore, we introduce the SKR module, which incorporates the distributions of different datasets as references in the feature space. This allows the SKR to aggregate the high-dimensional distribution of subclass features in few-shot FGVC tasks, thus expanding the decision boundary. Through these two critical components, we effectively utilize the knowledge from large models to address the issue of data scarcity, resulting in improved performance for fine-grained visual recognition tasks. Extensive experiments demonstrate the consistent performance gain offered by our DRDM.
Deep Supervised Information Bottleneck Hashing for Cross-modal Retrieval based Computer-aided Diagnosis
May 06, 2022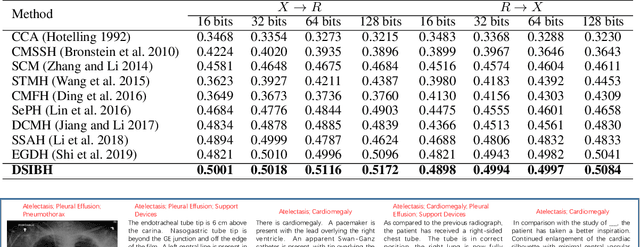
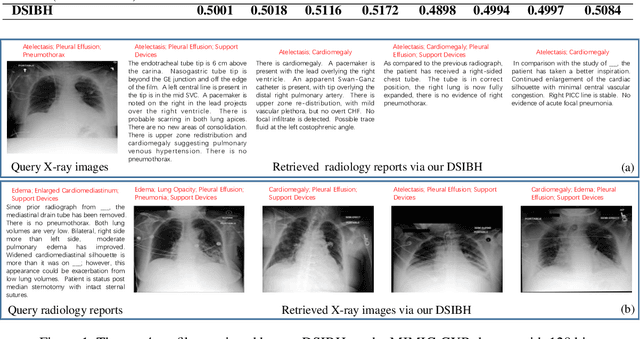
Mapping X-ray images, radiology reports, and other medical data as binary codes in the common space, which can assist clinicians to retrieve pathology-related data from heterogeneous modalities (i.e., hashing-based cross-modal medical data retrieval), provides a new view to promot computeraided diagnosis. Nevertheless, there remains a barrier to boost medical retrieval accuracy: how to reveal the ambiguous semantics of medical data without the distraction of superfluous information. To circumvent this drawback, we propose Deep Supervised Information Bottleneck Hashing (DSIBH), which effectively strengthens the discriminability of hash codes. Specifically, the Deep Deterministic Information Bottleneck (Yu, Yu, and Principe 2021) for single modality is extended to the cross-modal scenario. Benefiting from this, the superfluous information is reduced, which facilitates the discriminability of hash codes. Experimental results demonstrate the superior accuracy of the proposed DSIBH compared with state-of-the-arts in cross-modal medical data retrieval tasks.
* 7 pages, 1 figure