 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep g-Pricing for CSI 300 Index Options with Volatility Trajectories and Market Sentiment
Jan 15, 2026Option pricing in real markets faces fundamental challenges. The Black--Scholes--Merton (BSM) model assumes constant volatility and uses a linear generator $g(t,x,y,z)=-ry$, while lacking explicit behavioral factors, resulting in systematic departures from observed dynamics. This paper extends the BSM model by learning a nonlinear generator within a deep Forward--Backward Stochastic Differential Equation (FBSDE) framework. We propose a dual-network architecture where the value network $u_θ$ learns option prices and the generator network $g_φ$ characterizes the pricing mechanism, with the hedging strategy $Z_t=σ_t X_t \nabla_x u_θ$ obtained via automatic differentiation. The framework adopts forward recursion from a learnable initial condition $Y_0=u_θ(0,\cdot)$, naturally accommodating volatility trajectory and sentiment features. Empirical results on CSI 300 index options show that our method reduces Mean Absolute Error (MAE) by 32.2\% and Mean Absolute Percentage Error (MAPE) by 35.3\% compared with BSM. Interpretability analysis indicates that architectural improvements are effective across all option types, while the information advantage is asymmetric between calls and puts. Specifically, call option improvements are primarily driven by sentiment features, whereas put options show more balanced contributions from volatility trajectory and sentiment features. This finding aligns with economic intuition regarding option pricing mechanisms.
Trustworthy Alignment of Retrieval-Augmented Large Language Models via Reinforcement Learning
Oct 22, 2024



Trustworthiness is an essential prerequisite for the real-world application of large language models. In this paper, we focus on the trustworthiness of language models with respect to retrieval augmentation. Despite being supported with external evidence, retrieval-augmented generation still suffers from hallucinations, one primary cause of which is the conflict between contextual and parametric knowledge. We deem that retrieval-augmented language models have the inherent capabilities of supplying response according to both contextual and parametric knowledge. Inspired by aligning language models with human preference, we take the first step towards aligning retrieval-augmented language models to a status where it responds relying merely on the external evidence and disregards the interference of parametric knowledge. Specifically, we propose a reinforcement learning based algorithm Trustworthy-Alignment, theoretically and experimentally demonstrating large language models' capability of reaching a trustworthy status without explicit supervision on how to respond. Our work highlights the potential of large language models on exploring its intrinsic abilities by its own and expands the application scenarios of alignment from fulfilling human preference to creating trustworthy agents.
* ICML 2024
CDLT: A Dataset with Concept Drift and Long-Tailed Distribution for Fine-Grained Visual Categorization
Jun 04, 2023



Data is the foundation for the development of computer vision, and the establishment of datasets plays an important role in advancing the techniques of fine-grained visual categorization~(FGVC). In the existing FGVC datasets used in computer vision, it is generally assumed that each collected instance has fixed characteristics and the distribution of different categories is relatively balanced. In contrast, the real world scenario reveals the fact that the characteristics of instances tend to vary with time and exhibit a long-tailed distribution. Hence, the collected datasets may mislead the optimization of the fine-grained classifiers, resulting in unpleasant performance in real applications. Starting from the real-world conditions and to promote the practical progress of fine-grained visual categorization, we present a Concept Drift and Long-Tailed Distribution dataset. Specifically, the dataset is collected by gathering 11195 images of 250 instances in different species for 47 consecutive months in their natural contexts. The collection process involves dozens of crowd workers for photographing and domain experts for labelling. Extensive baseline experiments using the state-of-the-art fine-grained classification models demonstrate the issues of concept drift and long-tailed distribution existed in the dataset, which require the attention of future researches.
Filter Pruning based on Information Capacity and Independence
Mar 07, 2023
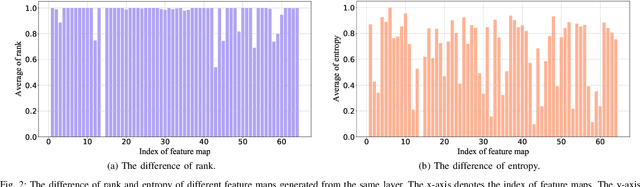


Filter pruning has been widely used in the compression and acceleration of convolutional neural networks (CNNs). However, most existing methods are still challenged by heavy compute cost and biased filter selection. Moreover, most designs for filter evaluation miss interpretability due to the lack of appropriate theoretical guidance. In this paper, we propose a novel filter pruning method which evaluates filters in a interpretable, multi-persepective and data-free manner. We introduce information capacity, a metric that represents the amount of information contained in a filter. Based on the interpretability and validity of information entropy, we propose to use that as a quantitative index of information quantity. Besides, we experimently show that the obvious correlation between the entropy of the feature map and the corresponding filter, so as to propose an interpretable, data-driven scheme to measure the information capacity of the filter. Further, we introduce information independence, another metric that represents the correlation among differrent filters. Consequently, the least impotant filters, which have less information capacity and less information independence, will be pruned. We evaluate our method on two benchmarks using multiple representative CNN architectures, including VGG-16 and ResNet. On CIFAR-10, we reduce 71.9% of floating-point operations (FLOPs) and 69.4% of parameters for ResNet-110 with 0.28% accuracy increase. On ILSVRC-2012, we reduce 76.6% of floating-point operations (FLOPs) and 68.6% of parameters for ResNet-50 with only 2.80% accuracy decrease, which outperforms the state-of-the-arts.
Deep Manifold Hashing: A Divide-and-Conquer Approach for Semi-Paired Unsupervised Cross-Modal Retrieval
Sep 26, 2022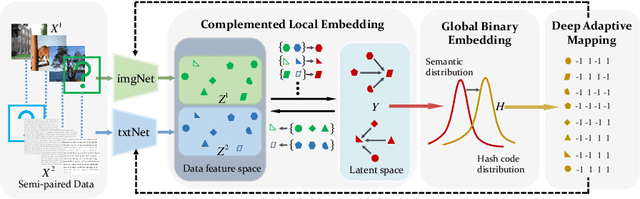

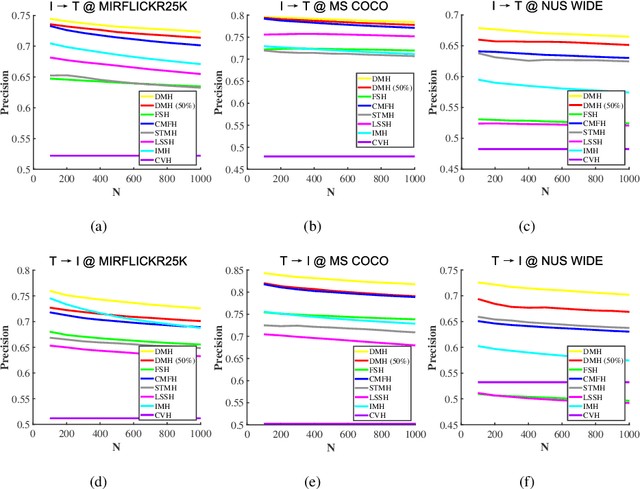

Hashing that projects data into binary codes has shown extraordinary talents in cross-modal retrieval due to its low storage usage and high query speed. Despite their empirical success on some scenarios, existing cross-modal hashing methods usually fail to cross modality gap when fully-paired data with plenty of labeled information is nonexistent. To circumvent this drawback, motivated by the Divide-and-Conquer strategy, we propose Deep Manifold Hashing (DMH), a novel method of dividing the problem of semi-paired unsupervised cross-modal retrieval into three sub-problems and building one simple yet efficiency model for each sub-problem. Specifically, the first model is constructed for obtaining modality-invariant features by complementing semi-paired data based on manifold learning, whereas the second model and the third model aim to learn hash codes and hash functions respectively. Extensive experiments on three benchmarks demonstrate the superiority of our DMH compared with the state-of-the-art fully-paired and semi-paired unsupervised cross-modal hashing methods.
Information-Theoretic Hashing for Zero-Shot Cross-Modal Retrieval
Sep 26, 2022Zero-shot cross-modal retrieval (ZS-CMR) deals with the retrieval problem among heterogenous data from unseen classes. Typically, to guarantee generalization, the pre-defined class embeddings from natural language processing (NLP) models are used to build a common space. In this paper, instead of using an extra NLP model to define a common space beforehand, we consider a totally different way to construct (or learn) a common hamming space from an information-theoretic perspective. We term our model the Information-Theoretic Hashing (ITH), which is composed of two cascading modules: an Adaptive Information Aggregation (AIA) module; and a Semantic Preserving Encoding (SPE) module. Specifically, our AIA module takes the inspiration from the Principle of Relevant Information (PRI) to construct a common space that adaptively aggregates the intrinsic semantics of different modalities of data and filters out redundant or irrelevant information. On the other hand, our SPE module further generates the hashing codes of different modalities by preserving the similarity of intrinsic semantics with the element-wise Kullback-Leibler (KL) divergence. A total correlation regularization term is also imposed to reduce the redundancy amongst different dimensions of hash codes. Sufficient experiments on three benchmark datasets demonstrate the superiority of the proposed ITH in ZS-CMR. Source code is available in the supplementary material.
Deep Supervised Information Bottleneck Hashing for Cross-modal Retrieval based Computer-aided Diagnosis
May 06, 2022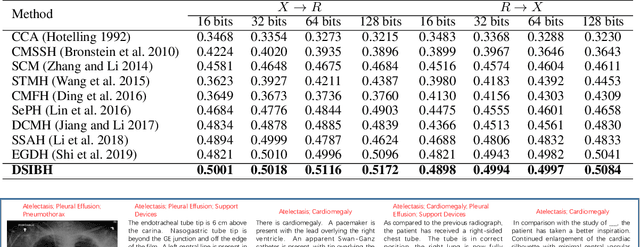
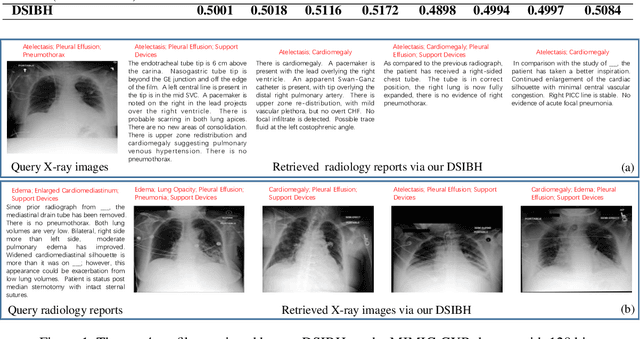
Mapping X-ray images, radiology reports, and other medical data as binary codes in the common space, which can assist clinicians to retrieve pathology-related data from heterogeneous modalities (i.e., hashing-based cross-modal medical data retrieval), provides a new view to promot computeraided diagnosis. Nevertheless, there remains a barrier to boost medical retrieval accuracy: how to reveal the ambiguous semantics of medical data without the distraction of superfluous information. To circumvent this drawback, we propose Deep Supervised Information Bottleneck Hashing (DSIBH), which effectively strengthens the discriminability of hash codes. Specifically, the Deep Deterministic Information Bottleneck (Yu, Yu, and Principe 2021) for single modality is extended to the cross-modal scenario. Benefiting from this, the superfluous information is reduced, which facilitates the discriminability of hash codes. Experimental results demonstrate the superior accuracy of the proposed DSIBH compared with state-of-the-arts in cross-modal medical data retrieval tasks.
* 7 pages, 1 figure