 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkillAdaptor: Self-Adapting Skills for LLM Agents from Trajectories
May 31, 2026Large language model (LLM) agents increasingly rely on reusable external skills to solve long-horizon interactive tasks. Existing training-free skill adaptation pipelines usually update skills from full trajectories or session-level feedback, which makes failure attribution coarse and often produces unstable or overly broad revisions. We propose SkillAdaptor, a training-free step-level skill adaptation framework with explicit failure attribution, and it can plug into OpenClaw-class agent harnesses. Given a failed trajectory, SkillAdaptor identifies a first actionable fault step, links responsibility to candidate skills, and applies targeted updates under explicit acceptance checks while keeping the backbone frozen. We evaluate on WebShop, PinchBench, and Claw-Eval with Kimi-K2.5, GLM-5, and GPT-5.2. SkillAdaptor improves over no-skill and skill-adaptation baselines on all three suites, with the largest single-metric improvements of +1.5 points on PinchBench Avg Score%, +1.8 on Claw-Eval Avg Score, and +1.7 on WebShop success rate. These results indicate that step-level attribution supports more stable and auditable training-free skill maintenance\footnote{The code will be released at https://github.com/zjunlp/SkillAdaptor.}.
Every Step Counts: Step-Level Credit Assignment for Tool-Integrated Text-to-SQL
May 06, 2026Tool-integrated Text-to-SQL parsing has emerged as a promising paradigm, framing SQL generation as a sequential decision-making process interleaved with tool execution. However, existing reinforcement learning approaches mainly rely on coarse-grained outcome supervision, resulting in a fundamental credit assignment problem: models receive the same reward for any trajectory that yields the correct answer, even when intermediate steps are redundant, inefficient, or erroneous. Consequently, models are encouraged to explore suboptimal reasoning spaces, limiting both efficiency and generalization. To address this problem, we propose FineStep, a novel framework for step-level credit assignment in tool-augmented Text-to-SQL. First, we introduce a reward design with independent process rewards to alleviate the signal sparsity of outcome supervision. Next, we present a step-level credit assignment mechanism to precisely quantify the value of each reasoning step. Finally, we develop a policy optimization method based on step-level advantages for efficient updates. Extensive experiments on BIRD benchmarks show that FineStep achieves state-of-the-art performance and reduces redundant tool interactions, with a 3.25% average EX gain over GRPO at the 4B scale.
SGA-MCTS: Decoupling Planning from Execution via Training-Free Atomic Experience Retrieval
Apr 16, 2026LLM-powered systems require complex multi-step decision-making abilities to solve real-world tasks, yet current planning approaches face a trade-off between the high latency of inference-time search and the limited generalization of supervised fine-tuning. To address this limitation, we introduce \textbf{SGA-MCTS}, a framework that casts LLM planning as non-parametric retrieval. Offline, we leverage Monte Carlo Tree Search (MCTS) to explore the solution space and distill high-fidelity trajectories into State-Goal-Action (SGA) atoms. These atoms are de-lexicalized primitives that abstract concrete entities into symbolic slots, preserving reusable causal logic while discarding domain-specific noise. Online, a retrieval-augmented agent employs a hybrid symbolic-semantic mechanism to fetch relevant SGAs and re-ground them into the current context as soft reasoning hints. Empirical results on complex benchmarks demonstrate that this paradigm enables frozen, open-weights models to match the performance of SOTA systems (e.g., GPT-5) without task-specific fine-tuning. By effectively amortizing the heavy computational cost of search, SGA-MCTS achieves System 2 reasoning depth at System 1 inference speeds, rendering autonomous planning both scalable and real-time feasible.
SkillX: Automatically Constructing Skill Knowledge Bases for Agents
Apr 06, 2026Learning from experience is critical for building capable large language model (LLM) agents, yet prevailing self-evolving paradigms remain inefficient: agents learn in isolation, repeatedly rediscover similar behaviors from limited experience, resulting in redundant exploration and poor generalization. To address this problem, we propose SkillX, a fully automated framework for constructing a \textbf{plug-and-play skill knowledge base} that can be reused across agents and environments. SkillX operates through a fully automated pipeline built on three synergistic innovations: \textit{(i) Multi-Level Skills Design}, which distills raw trajectories into three-tiered hierarchy of strategic plans, functional skills, and atomic skills; \textit{(ii) Iterative Skills Refinement}, which automatically revises skills based on execution feedback to continuously improve library quality; and \textit{(iii) Exploratory Skills Expansion}, which proactively generates and validates novel skills to expand coverage beyond seed training data. Using a strong backbone agent (GLM-4.6), we automatically build a reusable skill library and evaluate its transferability on challenging long-horizon, user-interactive benchmarks, including AppWorld, BFCL-v3, and $τ^2$-Bench. Experiments show that SkillKB consistently improves task success and execution efficiency when plugged into weaker base agents, highlighting the importance of structured, hierarchical experience representations for generalizable agent learning. Our code will be publicly available soon at https://github.com/zjunlp/SkillX.
Agentar-Fin-R1: Enhancing Financial Intelligence through Domain Expertise, Training Efficiency, and Advanced Reasoning
Jul 24, 2025Large Language Models (LLMs) exhibit considerable promise in financial applications; however, prevailing models frequently demonstrate limitations when confronted with scenarios that necessitate sophisticated reasoning capabilities, stringent trustworthiness criteria, and efficient adaptation to domain-specific requirements. We introduce the Agentar-Fin-R1 series of financial large language models (8B and 32B parameters), specifically engineered based on the Qwen3 foundation model to enhance reasoning capabilities, reliability, and domain specialization for financial applications. Our optimization approach integrates a high-quality, systematic financial task label system with a comprehensive multi-layered trustworthiness assurance framework. This framework encompasses high-quality trustworthy knowledge engineering, multi-agent trustworthy data synthesis, and rigorous data validation governance. Through label-guided automated difficulty-aware optimization, tow-stage training pipeline, and dynamic attribution systems, we achieve substantial improvements in training efficiency. Our models undergo comprehensive evaluation on mainstream financial benchmarks including Fineva, FinEval, and FinanceIQ, as well as general reasoning datasets such as MATH-500 and GPQA-diamond. To thoroughly assess real-world deployment capabilities, we innovatively propose the Finova evaluation benchmark, which focuses on agent-level financial reasoning and compliance verification. Experimental results demonstrate that Agentar-Fin-R1 not only achieves state-of-the-art performance on financial tasks but also exhibits exceptional general reasoning capabilities, validating its effectiveness as a trustworthy solution for high-stakes financial applications. The Finova bench is available at https://github.com/antgroup/Finova.
BoolQuestions: Does Dense Retrieval Understand Boolean Logic in Language?
Nov 19, 2024



Dense retrieval, which aims to encode the semantic information of arbitrary text into dense vector representations or embeddings, has emerged as an effective and efficient paradigm for text retrieval, consequently becoming an essential component in various natural language processing systems. These systems typically focus on optimizing the embedding space by attending to the relevance of text pairs, while overlooking the Boolean logic inherent in language, which may not be captured by current training objectives. In this work, we first investigate whether current retrieval systems can comprehend the Boolean logic implied in language. To answer this question, we formulate the task of Boolean Dense Retrieval and collect a benchmark dataset, BoolQuestions, which covers complex queries containing basic Boolean logic and corresponding annotated passages. Through extensive experimental results on the proposed task and benchmark dataset, we draw the conclusion that current dense retrieval systems do not fully understand Boolean logic in language, and there is a long way to go to improve our dense retrieval systems. Furthermore, to promote further research on enhancing the understanding of Boolean logic for language models, we explore Boolean operation on decomposed query and propose a contrastive continual training method that serves as a strong baseline for the research community.
* Findings of the Association for Computational Linguistics: EMNLP 2024
Trustworthy Alignment of Retrieval-Augmented Large Language Models via Reinforcement Learning
Oct 22, 2024



Trustworthiness is an essential prerequisite for the real-world application of large language models. In this paper, we focus on the trustworthiness of language models with respect to retrieval augmentation. Despite being supported with external evidence, retrieval-augmented generation still suffers from hallucinations, one primary cause of which is the conflict between contextual and parametric knowledge. We deem that retrieval-augmented language models have the inherent capabilities of supplying response according to both contextual and parametric knowledge. Inspired by aligning language models with human preference, we take the first step towards aligning retrieval-augmented language models to a status where it responds relying merely on the external evidence and disregards the interference of parametric knowledge. Specifically, we propose a reinforcement learning based algorithm Trustworthy-Alignment, theoretically and experimentally demonstrating large language models' capability of reaching a trustworthy status without explicit supervision on how to respond. Our work highlights the potential of large language models on exploring its intrinsic abilities by its own and expands the application scenarios of alignment from fulfilling human preference to creating trustworthy agents.
* ICML 2024
Revisiting Regex Generation for Modeling Industrial Applications by Incorporating Byte Pair Encoder
May 06, 2020
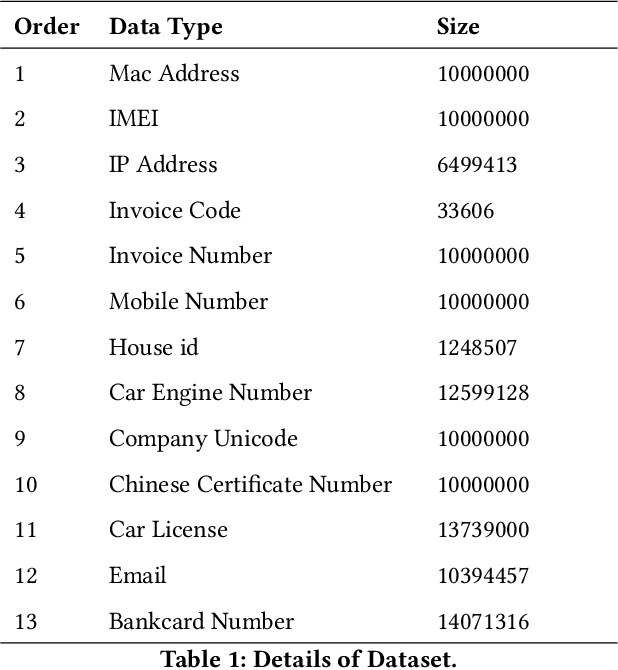
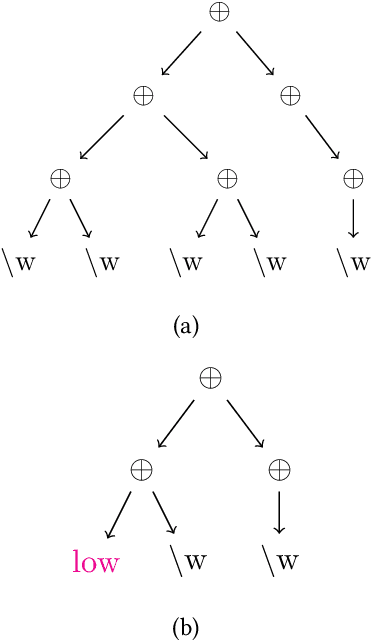

Regular expression is important for many natural language processing tasks especially when used to deal with unstructured and semi-structured data. This work focuses on automatically generating regular expressions and proposes a novel genetic algorithm to deal with this problem. Different from the methods which generate regular expressions from character level, we first utilize byte pair encoder (BPE) to extract some frequent items, which are then used to construct regular expressions. The fitness function of our genetic algorithm contains multi objectives and is solved based on evolutionary procedure including crossover and mutation operation. In the fitness function, we take the length of generated regular expression, the maximum matching characters and samples for positive training samples, and the minimum matching characters and samples for negative training samples into consideration. In addition, to accelerate the training process, we do exponential decay on the population size of the genetic algorithm. Our method together with a strong baseline is tested on 13 kinds of challenging datasets. The results demonstrate the effectiveness of our method, which outperforms the baseline on 10 kinds of data and achieves nearly 50 percent improvement on average. By doing exponential decay, the training speed is approximately 100 times faster than the methods without using exponential decay. In summary, our method possesses both effectiveness and efficiency, and can be implemented for the industry application.