 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Regex Generation for Modeling Industrial Applications by Incorporating Byte Pair Encoder
Paper and Code
May 06, 2020
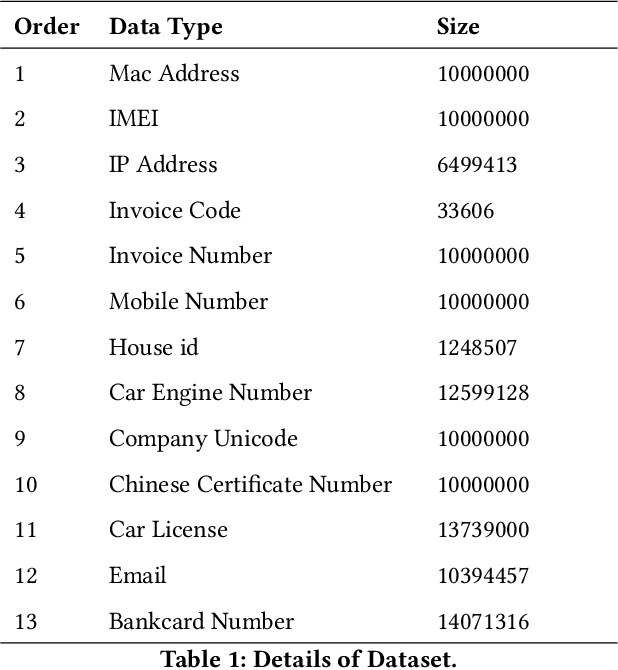
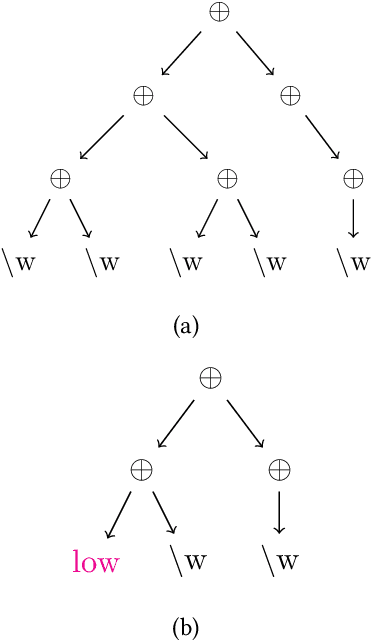

Regular expression is important for many natural language processing tasks especially when used to deal with unstructured and semi-structured data. This work focuses on automatically generating regular expressions and proposes a novel genetic algorithm to deal with this problem. Different from the methods which generate regular expressions from character level, we first utilize byte pair encoder (BPE) to extract some frequent items, which are then used to construct regular expressions. The fitness function of our genetic algorithm contains multi objectives and is solved based on evolutionary procedure including crossover and mutation operation. In the fitness function, we take the length of generated regular expression, the maximum matching characters and samples for positive training samples, and the minimum matching characters and samples for negative training samples into consideration. In addition, to accelerate the training process, we do exponential decay on the population size of the genetic algorithm. Our method together with a strong baseline is tested on 13 kinds of challenging datasets. The results demonstrate the effectiveness of our method, which outperforms the baseline on 10 kinds of data and achieves nearly 50 percent improvement on average. By doing exponential decay, the training speed is approximately 100 times faster than the methods without using exponential decay. In summary, our method possesses both effectiveness and efficiency, and can be implemented for the industry application.