 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvery Step Counts: Step-Level Credit Assignment for Tool-Integrated Text-to-SQL
May 06, 2026Tool-integrated Text-to-SQL parsing has emerged as a promising paradigm, framing SQL generation as a sequential decision-making process interleaved with tool execution. However, existing reinforcement learning approaches mainly rely on coarse-grained outcome supervision, resulting in a fundamental credit assignment problem: models receive the same reward for any trajectory that yields the correct answer, even when intermediate steps are redundant, inefficient, or erroneous. Consequently, models are encouraged to explore suboptimal reasoning spaces, limiting both efficiency and generalization. To address this problem, we propose FineStep, a novel framework for step-level credit assignment in tool-augmented Text-to-SQL. First, we introduce a reward design with independent process rewards to alleviate the signal sparsity of outcome supervision. Next, we present a step-level credit assignment mechanism to precisely quantify the value of each reasoning step. Finally, we develop a policy optimization method based on step-level advantages for efficient updates. Extensive experiments on BIRD benchmarks show that FineStep achieves state-of-the-art performance and reduces redundant tool interactions, with a 3.25% average EX gain over GRPO at the 4B scale.
Metastatic Cancer Image Classification Based On Deep Learning Method
Nov 13, 2020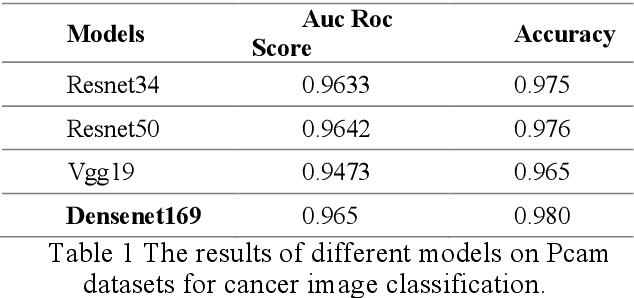
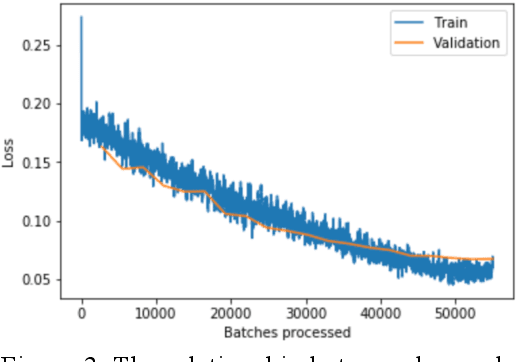
Using histopathological images to automatically classify cancer is a difficult task for accurately detecting cancer, especially to identify metastatic cancer in small image patches obtained from larger digital pathology scans. Computer diagnosis technology has attracted wide attention from researchers. In this paper, we propose a noval method which combines the deep learning algorithm in image classification, the DenseNet169 framework and Rectified Adam optimization algorithm. The connectivity pattern of DenseNet is direct connections from any layer to all consecutive layers, which can effectively improve the information flow between different layers. With the fact that RAdam is not easy to fall into a local optimal solution, and it can converge quickly in model training. The experimental results shows that our model achieves superior performance over the other classical convolutional neural networks approaches, such as Vgg19, Resnet34, Resnet50. In particular, the Auc-Roc score of our DenseNet169 model is 1.77% higher than Vgg19 model, and the Accuracy score is 1.50% higher. Moreover, we also study the relationship between loss value and batches processed during the training stage and validation stage, and obtain some important and interesting findings.
Revisiting Regex Generation for Modeling Industrial Applications by Incorporating Byte Pair Encoder
May 06, 2020
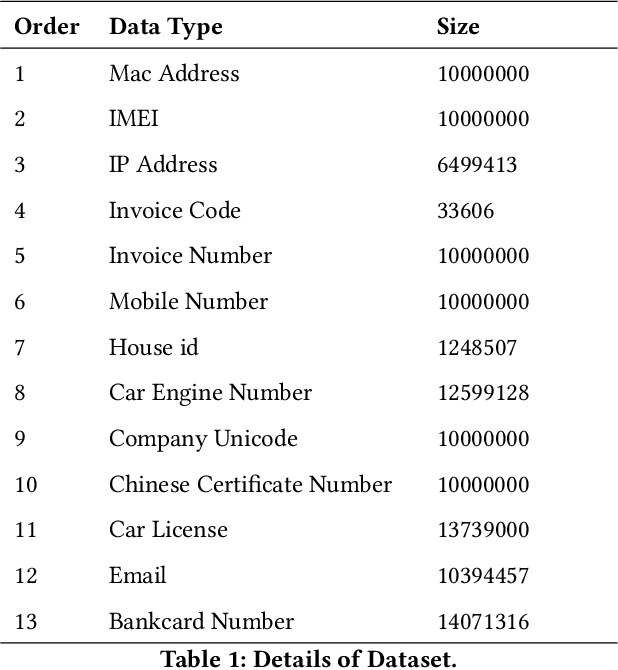
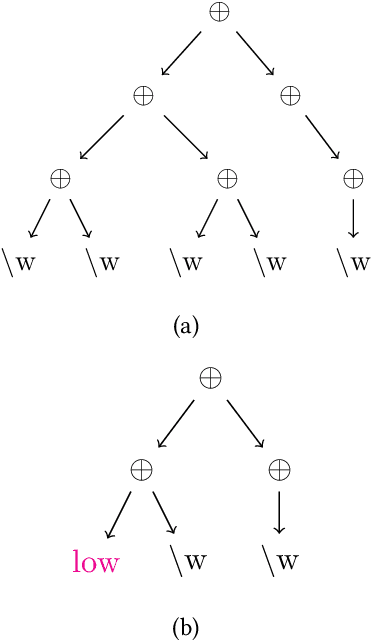

Regular expression is important for many natural language processing tasks especially when used to deal with unstructured and semi-structured data. This work focuses on automatically generating regular expressions and proposes a novel genetic algorithm to deal with this problem. Different from the methods which generate regular expressions from character level, we first utilize byte pair encoder (BPE) to extract some frequent items, which are then used to construct regular expressions. The fitness function of our genetic algorithm contains multi objectives and is solved based on evolutionary procedure including crossover and mutation operation. In the fitness function, we take the length of generated regular expression, the maximum matching characters and samples for positive training samples, and the minimum matching characters and samples for negative training samples into consideration. In addition, to accelerate the training process, we do exponential decay on the population size of the genetic algorithm. Our method together with a strong baseline is tested on 13 kinds of challenging datasets. The results demonstrate the effectiveness of our method, which outperforms the baseline on 10 kinds of data and achieves nearly 50 percent improvement on average. By doing exponential decay, the training speed is approximately 100 times faster than the methods without using exponential decay. In summary, our method possesses both effectiveness and efficiency, and can be implemented for the industry application.