 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemonstrating DVS: Dynamic Virtual-Real Simulation Platform for Mobile Robotic Tasks
Apr 26, 2025



With the development of embodied artificial intelligence, robotic research has increasingly focused on complex tasks. Existing simulation platforms, however, are often limited to idealized environments, simple task scenarios and lack data interoperability. This restricts task decomposition and multi-task learning. Additionally, current simulation platforms face challenges in dynamic pedestrian modeling, scene editability, and synchronization between virtual and real assets. These limitations hinder real world robot deployment and feedback. To address these challenges, we propose DVS (Dynamic Virtual-Real Simulation Platform), a platform for dynamic virtual-real synchronization in mobile robotic tasks. DVS integrates a random pedestrian behavior modeling plugin and large-scale, customizable indoor scenes for generating annotated training datasets. It features an optical motion capture system, synchronizing object poses and coordinates between virtual and real world to support dynamic task benchmarking. Experimental validation shows that DVS supports tasks such as pedestrian trajectory prediction, robot path planning, and robotic arm grasping, with potential for both simulation and real world deployment. In this way, DVS represents more than just a versatile robotic platform; it paves the way for research in human intervention in robot execution tasks and real-time feedback algorithms in virtual-real fusion environments. More information about the simulation platform is available on https://immvlab.github.io/DVS/.
Implicit factorized transformer approach to fast prediction of turbulent channel flows
Dec 25, 2024



Transformer neural operators have recently become an effective approach for surrogate modeling of nonlinear systems governed by partial differential equations (PDEs). In this paper, we introduce a modified implicit factorized transformer (IFactFormer-m) model which replaces the original chained factorized attention with parallel factorized attention. The IFactFormer-m model successfully performs long-term predictions for turbulent channel flow, whereas the original IFactFormer (IFactFormer-o), Fourier neural operator (FNO), and implicit Fourier neural operator (IFNO) exhibit a poor performance. Turbulent channel flows are simulated by direct numerical simulation using fine grids at friction Reynolds numbers $\text{Re}_{\tau}\approx 180,395,590$, and filtered to coarse grids for training neural operator. The neural operator takes the current flow field as input and predicts the flow field at the next time step, and long-term prediction is achieved in the posterior through an autoregressive approach. The prediction results show that IFactFormer-m, compared to other neural operators and the traditional large eddy simulation (LES) methods including dynamic Smagorinsky model (DSM) and the wall-adapted local eddy-viscosity (WALE) model, reduces prediction errors in the short term, and achieves stable and accurate long-term prediction of various statistical properties and flow structures, including the energy spectrum, mean streamwise velocity, root mean square (rms) values of fluctuating velocities, Reynolds shear stress, and spatial structures of instantaneous velocity. Moreover, the trained IFactFormer-m is much faster than traditional LES methods.
X-Recon: Learning-based Patient-specific High-Resolution CT Reconstruction from Orthogonal X-Ray Images
Jul 22, 2024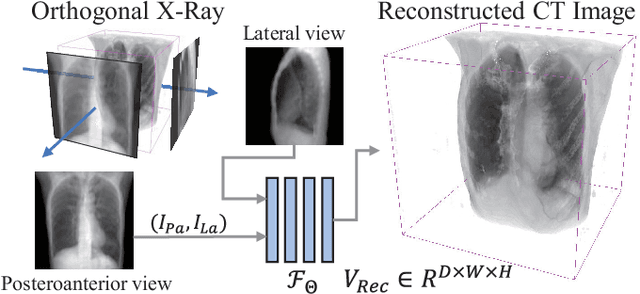
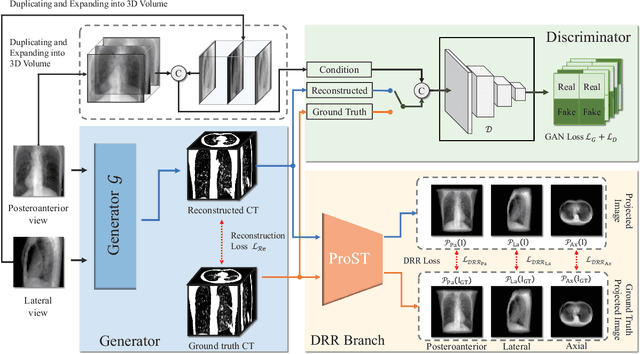
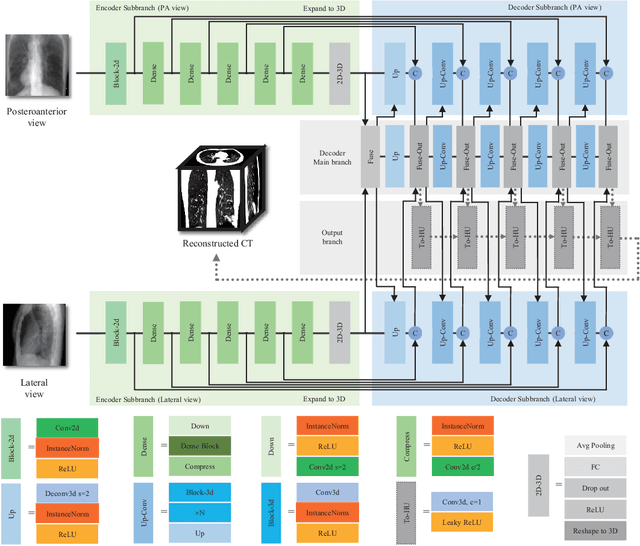
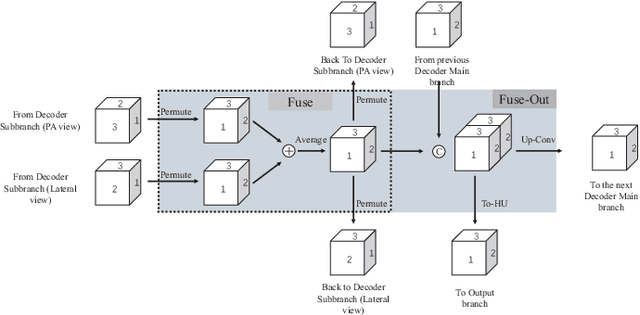
Rapid and accurate diagnosis of pneumothorax, utilizing chest X-ray and computed tomography (CT), is crucial for assisted diagnosis. Chest X-ray is commonly used for initial localization of pneumothorax, while CT ensures accurate quantification. However, CT scans involve high radiation doses and can be costly. To achieve precise quantitative diagnosis while minimizing radiation exposure, we proposed X-Recon, a CT ultra-sparse reconstruction network based on ortho-lateral chest X-ray images. X-Recon integrates generative adversarial networks (GANs), including a generator with a multi-scale fusion rendering module and a discriminator enhanced by 3D coordinate convolutional layers, designed to facilitate CT reconstruction. To improve precision, a projective spatial transformer is utilized to incorporate multi-angle projection loss. Additionally, we proposed PTX-Seg, a zero-shot pneumothorax segmentation algorithm, combining image processing techniques with deep-learning models for the segmentation of air-accumulated regions and lung structures. Experiments on a large-scale dataset demonstrate its superiority over existing approaches. X-Recon achieved a significantly higher reconstruction resolution with a higher average spatial resolution and a lower average slice thickness. The reconstruction metrics achieved state-of-the-art performance in terms of several metrics including peak signal-to-noise ratio. The zero-shot segmentation algorithm, PTX-Seg, also demonstrated high segmentation precision for the air-accumulated region, the left lung, and the right lung. Moreover, the consistency analysis for the pneumothorax chest occupancy ratio between reconstructed CT and original CT obtained a high correlation coefficient. Code will be available at: https://github.com/wangyunpengbio/X-Recon
AI-Generated Content Enhanced Computer-Aided Diagnosis Model for Thyroid Nodules: A ChatGPT-Style Assistant
Feb 04, 2024An artificial intelligence-generated content-enhanced computer-aided diagnosis (AIGC-CAD) model, designated as ThyGPT, has been developed. This model, inspired by the architecture of ChatGPT, could assist radiologists in assessing the risk of thyroid nodules through semantic-level human-machine interaction. A dataset comprising 19,165 thyroid nodule ultrasound cases from Zhejiang Cancer Hospital was assembled to facilitate the training and validation of the model. After training, ThyGPT could automatically evaluate thyroid nodule and engage in effective communication with physicians through human-computer interaction. The performance of ThyGPT was rigorously quantified using established metrics such as the receiver operating characteristic (ROC) curve, area under the curve (AUC), sensitivity, and specificity. The empirical findings revealed that radiologists, when supplemented with ThyGPT, markedly surpassed the diagnostic acumen of their peers utilizing traditional methods as well as the performance of the model in isolation. These findings suggest that AIGC-CAD systems, exemplified by ThyGPT, hold the promise to fundamentally transform the diagnostic workflows of radiologists in forthcoming years.
Nexus sine qua non: Essentially connected neural networks for spatial-temporal forecasting of multivariate time series
Jul 04, 2023



Modeling and forecasting multivariate time series not only facilitates the decision making of practitioners, but also deepens our scientific understanding of the underlying dynamical systems. Spatial-temporal graph neural networks (STGNNs) are emerged as powerful predictors and have become the de facto models for learning spatiotemporal representations in recent years. However, existing architectures of STGNNs tend to be complicated by stacking a series of fancy layers. The designed models could be either redundant or enigmatic, which pose great challenges on their complexity and scalability. Such concerns prompt us to re-examine the designs of modern STGNNs and identify core principles that contribute to a powerful and efficient neural predictor. Here we present a compact predictive model that is fully defined by a dense encoder-decoder and a message-passing layer, powered by node identifications, without any complex sequential modules, e.g., TCNs, RNNs, and Transformers. Empirical results demonstrate how a simple and elegant model with proper inductive basis can compare favorably w.r.t. the state of the art with elaborate designs, while being much more interpretable and computationally efficient for spatial-temporal forecasting problem. We hope our findings would open new horizons for future studies to revisit the design of more concise neural forecasting architectures.
Towards better traffic volume estimation: Tackling both underdetermined and non-equilibrium problems via a correlation-adaptive graph convolution network
Mar 14, 2023



Traffic volume is an indispensable ingredient to provide fine-grained information for traffic management and control. However, due to limited deployment of traffic sensors, obtaining full-scale volume information is far from easy. Existing works on this topic primarily focus on improving the overall estimation accuracy of a particular method and ignore the underlying challenges of volume estimation, thereby having inferior performances on some critical tasks. This paper studies two key problems with regard to traffic volume estimation: (1) underdetermined traffic flows caused by undetected movements, and (2) non-equilibrium traffic flows arise from congestion propagation. Here we demonstrate a graph-based deep learning method that can offer a data-driven, model-free and correlation adaptive approach to tackle the above issues and perform accurate network-wide traffic volume estimation. Particularly, in order to quantify the dynamic and nonlinear relationships between traffic speed and volume for the estimation of underdetermined flows, a speed patternadaptive adjacent matrix based on graph attention is developed and integrated into the graph convolution process, to capture non-local correlations between sensors. To measure the impacts of non-equilibrium flows, a temporal masked and clipped attention combined with a gated temporal convolution layer is customized to capture time-asynchronous correlations between upstream and downstream sensors. We then evaluate our model on a real-world highway traffic volume dataset and compare it with several benchmark models. It is demonstrated that the proposed model achieves high estimation accuracy even under 20% sensor coverage rate and outperforms other baselines significantly, especially on underdetermined and non-equilibrium flow locations. Furthermore, comprehensive quantitative model analysis are also carried out to justify the model designs.
TrajGen: Generating Realistic and Diverse Trajectories with Reactive and Feasible Agent Behaviors for Autonomous Driving
Mar 31, 2022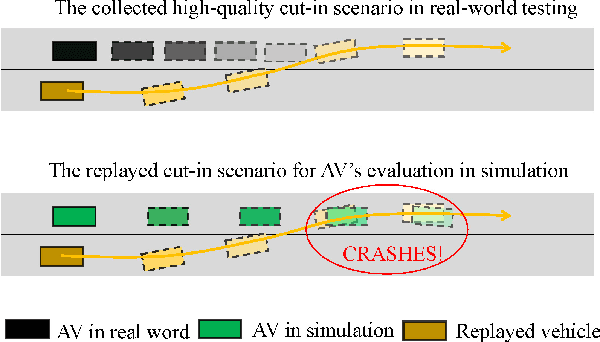
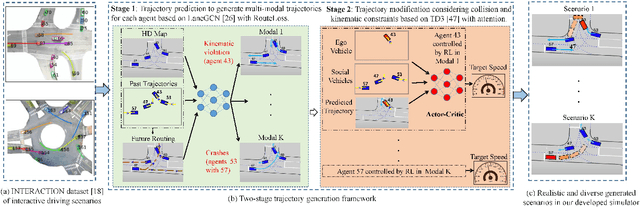
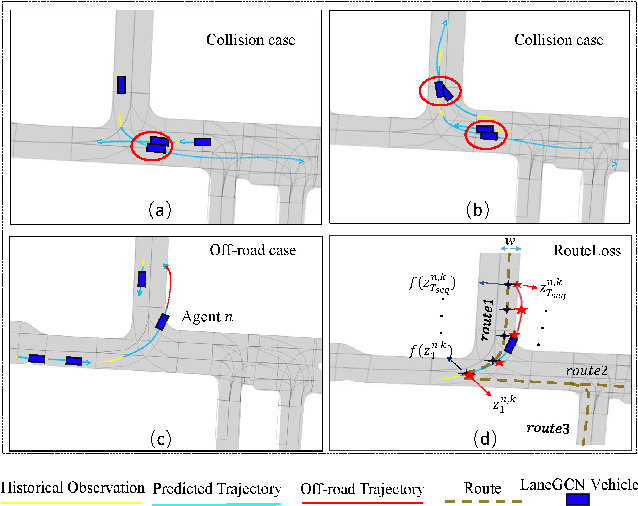
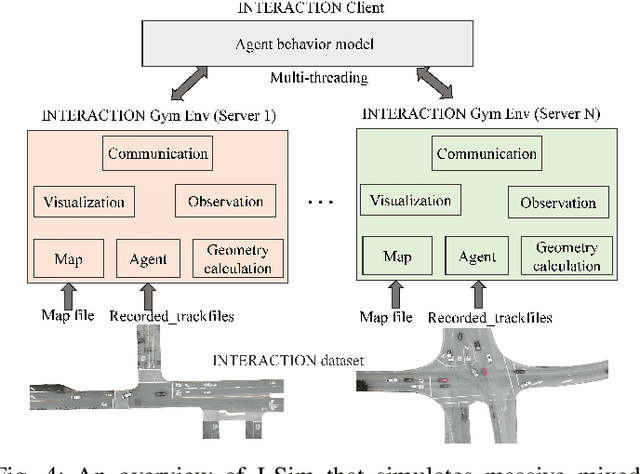
Realistic and diverse simulation scenarios with reactive and feasible agent behaviors can be used for validation and verification of self-driving system performance without relying on expensive and time-consuming real-world testing. Existing simulators rely on heuristic-based behavior models for background vehicles, which cannot capture the complex interactive behaviors in real-world scenarios. To bridge the gap between simulation and the real world, we propose TrajGen, a two-stage trajectory generation framework, which can capture more realistic behaviors directly from human demonstration. In particular, TrajGen consists of the multi-modal trajectory prediction stage and the reinforcement learning based trajectory modification stage. In the first stage, we propose a novel auxiliary RouteLoss for the trajectory prediction model to generate multi-modal diverse trajectories in the drivable area. In the second stage, reinforcement learning is used to track the predicted trajectories while avoiding collisions, which can improve the feasibility of generated trajectories. In addition, we develop a data-driven simulator I-Sim that can be used to train reinforcement learning models in parallel based on naturalistic driving data. The vehicle model in I-Sim can guarantee that the generated trajectories by TrajGen satisfy vehicle kinematic constraints. Finally, we give comprehensive metrics to evaluate generated trajectories for simulation scenarios, which shows that TrajGen outperforms either trajectory prediction or inverse reinforcement learning in terms of fidelity, reactivity, feasibility, and diversity.
Example Perplexity
Mar 16, 2022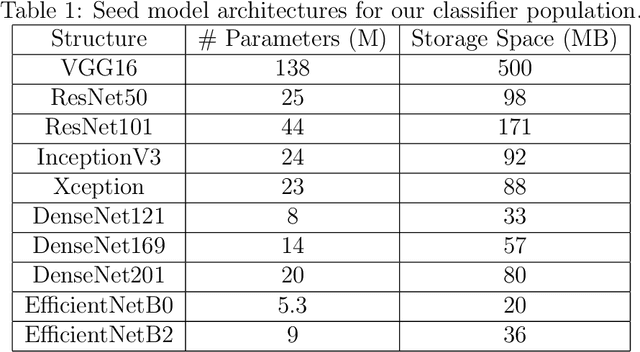
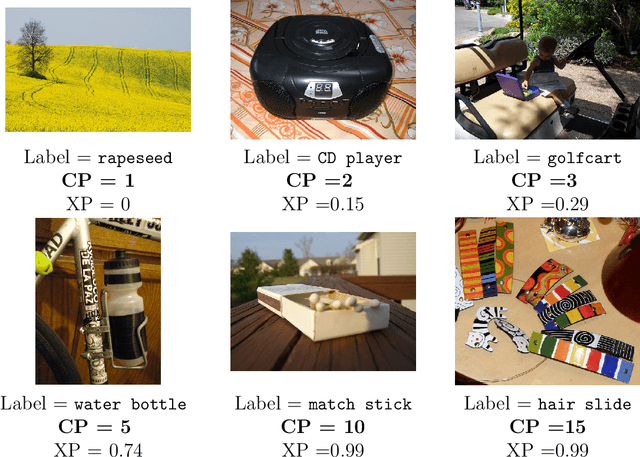

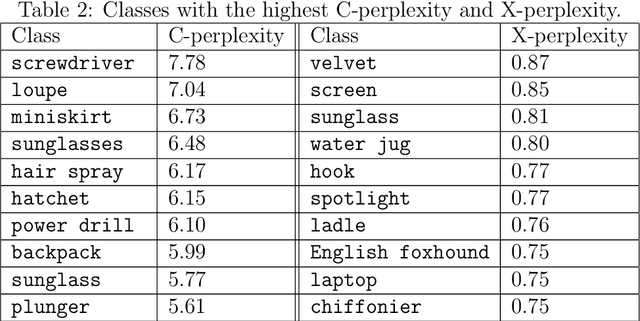
Some examples are easier for humans to classify than others. The same should be true for deep neural networks (DNNs). We use the term example perplexity to refer to the level of difficulty of classifying an example. In this paper, we propose a method to measure the perplexity of an example and investigate what factors contribute to high example perplexity. The related codes and resources are available at https://github.com/vaynexie/Example-Perplexity.
Metastatic Cancer Image Classification Based On Deep Learning Method
Nov 13, 2020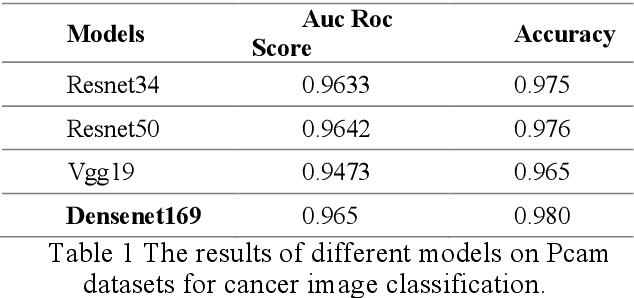
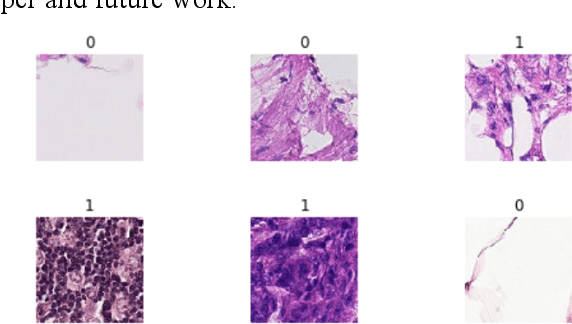
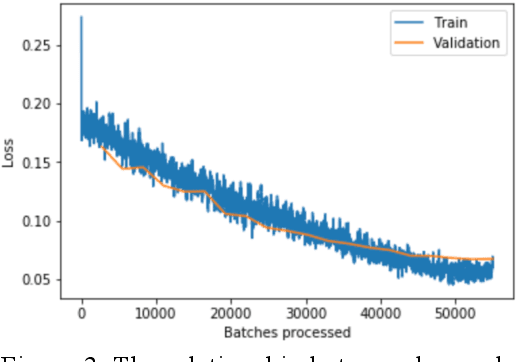
Using histopathological images to automatically classify cancer is a difficult task for accurately detecting cancer, especially to identify metastatic cancer in small image patches obtained from larger digital pathology scans. Computer diagnosis technology has attracted wide attention from researchers. In this paper, we propose a noval method which combines the deep learning algorithm in image classification, the DenseNet169 framework and Rectified Adam optimization algorithm. The connectivity pattern of DenseNet is direct connections from any layer to all consecutive layers, which can effectively improve the information flow between different layers. With the fact that RAdam is not easy to fall into a local optimal solution, and it can converge quickly in model training. The experimental results shows that our model achieves superior performance over the other classical convolutional neural networks approaches, such as Vgg19, Resnet34, Resnet50. In particular, the Auc-Roc score of our DenseNet169 model is 1.77% higher than Vgg19 model, and the Accuracy score is 1.50% higher. Moreover, we also study the relationship between loss value and batches processed during the training stage and validation stage, and obtain some important and interesting findings.
AbdomenCT-1K: Is Abdominal Organ Segmentation A Solved Problem?
Oct 28, 2020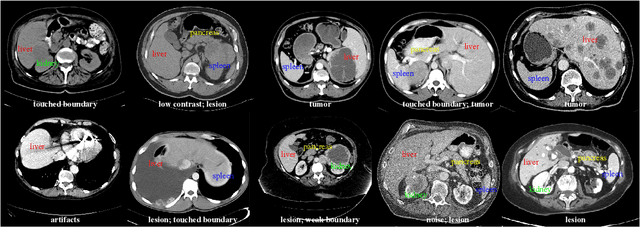
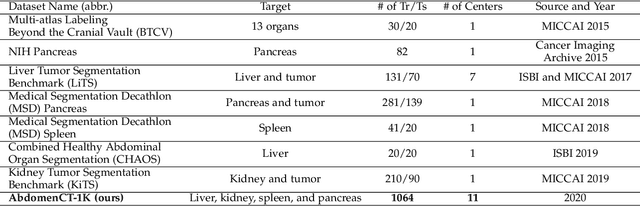
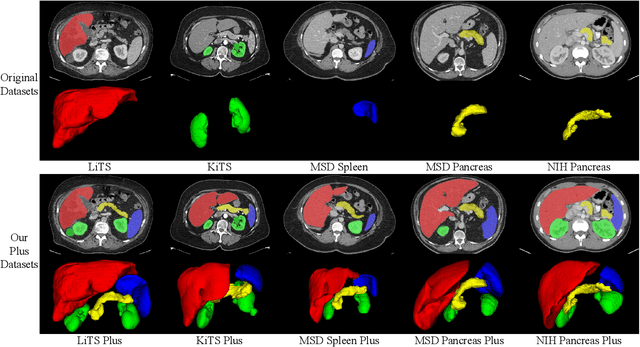
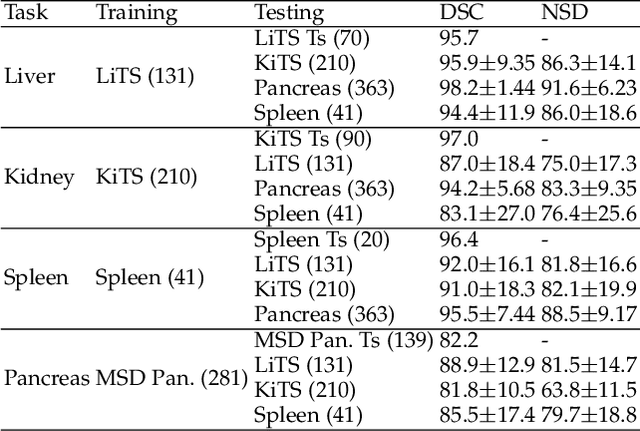
With the unprecedented developments in deep learning, automatic segmentation of main abdominal organs (i.e., liver, kidney, and spleen) seems to be a solved problem as the state-of-the-art (SOTA) methods have achieved comparable results with inter-observer variability on existing benchmark datasets. However, most of the existing abdominal organ segmentation benchmark datasets only contain single-center, single-phase, single-vendor, or single-disease cases, thus, it is unclear whether the excellent performance can generalize on more diverse datasets. In this paper, we present a large and diverse abdominal CT organ segmentation dataset, termed as AbdomenCT-1K, with more than 1000 (1K) CT scans from 11 countries, including multi-center, multi-phase, multi-vendor, and multi-disease cases. Furthermore, we conduct a large-scale study for liver, kidney, spleen, and pancreas segmentation, as well as reveal the unsolved segmentation problems of the SOTA method, such as the limited generalization ability on distinct medical centers, phases, and unseen diseases. To advance the unsolved problems, we build four organ segmentation benchmarks for fully supervised, semi-supervised, weakly supervised, and continual learning, which are currently challenging and active research topics. Accordingly, we develop a simple and effective method for each benchmark, which can be used as out-of-the-box methods and strong baselines. We believe the introduction of the AbdomenCT-1K dataset will promote future in-depth research towards clinical applicable abdominal organ segmentation methods. Moreover, the datasets, codes, and trained models of baseline methods will be publicly available at https://github.com/JunMa11/AbdomenCT-1K.