 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDensity-aware Sample-specific Attack
May 28, 2026Despite recent progress in backdoor attacks, existing methods remain susceptible to post-training defenses that erase the backdoor through fine-tuning or pruning. We revisit the core objectives of backdoor attacks and derive principled criteria characterizing optimal sample-specific trigger construction under a Bayes-optimal model of the victim's training. Our analysis reveals that both attack success and clean-accuracy preservation are simultaneously optimized when triggered samples are steered into low-density regions of the clean data distribution, a distributional condition that controls all moments of the poisoned distribution at once rather than a handful of input-space summary statistics. We introduce a bilevel optimization framework that estimates density ratios via conditional time-score matching and optimizes a mixture-model objective to place triggered samples in these sparse regions. Extensive evaluations on MNIST, CIFAR-10, GTSRB, and TinyImageNet demonstrate that our method achieves above 99\% attack success rate before defense and retains 50--85 percentage points higher post-defense ASR than the strongest baselines under fine-tuning defenses. Against neuron-pruning defenses, the method exhibits complete immunity, with zero neurons identified for removal across all pruning thresholds. These results expose a fundamental gap in current defense paradigms and underscore the need for defenses that operate beyond the support of the clean distribution.
Multi-Modal Robust Enhancement for Coastal Water Segmentation: A Systematic HSV-Guided Framework
Sep 10, 2025Coastal water segmentation from satellite imagery presents unique challenges due to complex spectral characteristics and irregular boundary patterns. Traditional RGB-based approaches often suffer from training instability and poor generalization in diverse maritime environments. This paper introduces a systematic robust enhancement framework, referred to as Robust U-Net, that leverages HSV color space supervision and multi-modal constraints for improved coastal water segmentation. Our approach integrates five synergistic components: HSV-guided color supervision, gradient-based coastline optimization, morphological post-processing, sea area cleanup, and connectivity control. Through comprehensive ablation studies, we demonstrate that HSV supervision provides the highest impact (0.85 influence score), while the complete framework achieves superior training stability (84\% variance reduction) and enhanced segmentation quality. Our method shows consistent improvements across multiple evaluation metrics while maintaining computational efficiency. For reproducibility, our training configurations and code are available here: https://github.com/UofgCoastline/ICASSP-2026-Robust-Unet.
FedPhD: Federated Pruning with Hierarchical Learning of Diffusion Models
Jul 08, 2025



Federated Learning (FL), as a distributed learning paradigm, trains models over distributed clients' data. FL is particularly beneficial for distributed training of Diffusion Models (DMs), which are high-quality image generators that require diverse data. However, challenges such as high communication costs and data heterogeneity persist in training DMs similar to training Transformers and Convolutional Neural Networks. Limited research has addressed these issues in FL environments. To address this gap and challenges, we introduce a novel approach, FedPhD, designed to efficiently train DMs in FL environments. FedPhD leverages Hierarchical FL with homogeneity-aware model aggregation and selection policy to tackle data heterogeneity while reducing communication costs. The distributed structured pruning of FedPhD enhances computational efficiency and reduces model storage requirements in clients. Our experiments across multiple datasets demonstrate that FedPhD achieves high model performance regarding Fr\'echet Inception Distance (FID) scores while reducing communication costs by up to $88\%$. FedPhD outperforms baseline methods achieving at least a $34\%$ improvement in FID, while utilizing only $56\%$ of the total computation and communication resources.
LACOSTE: Exploiting stereo and temporal contexts for surgical instrument segmentation
Sep 14, 2024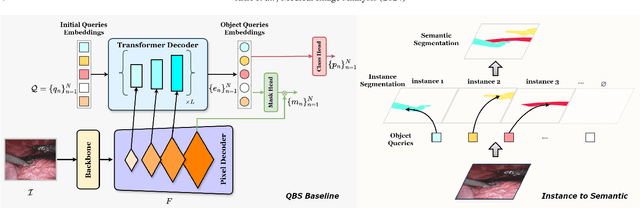
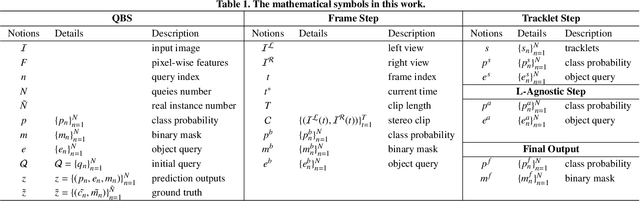
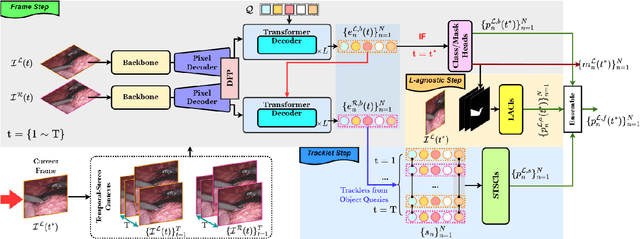
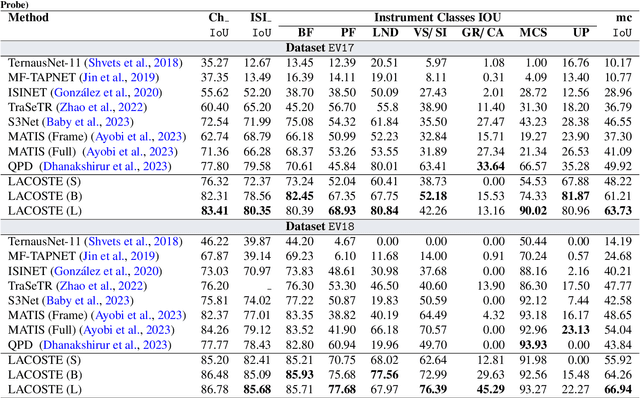
Surgical instrument segmentation is instrumental to minimally invasive surgeries and related applications. Most previous methods formulate this task as single-frame-based instance segmentation while ignoring the natural temporal and stereo attributes of a surgical video. As a result, these methods are less robust against the appearance variation through temporal motion and view change. In this work, we propose a novel LACOSTE model that exploits Location-Agnostic COntexts in Stereo and TEmporal images for improved surgical instrument segmentation. Leveraging a query-based segmentation model as core, we design three performance-enhancing modules. Firstly, we design a disparity-guided feature propagation module to enhance depth-aware features explicitly. To generalize well for even only a monocular video, we apply a pseudo stereo scheme to generate complementary right images. Secondly, we propose a stereo-temporal set classifier, which aggregates stereo-temporal contexts in a universal way for making a consolidated prediction and mitigates transient failures. Finally, we propose a location-agnostic classifier to decouple the location bias from mask prediction and enhance the feature semantics. We extensively validate our approach on three public surgical video datasets, including two benchmarks from EndoVis Challenges and one real radical prostatectomy surgery dataset GraSP. Experimental results demonstrate the promising performances of our method, which consistently achieves comparable or favorable results with previous state-of-the-art approaches.
Decentralized Personalized Federated Learning based on a Conditional Sparse-to-Sparser Scheme
Apr 25, 2024

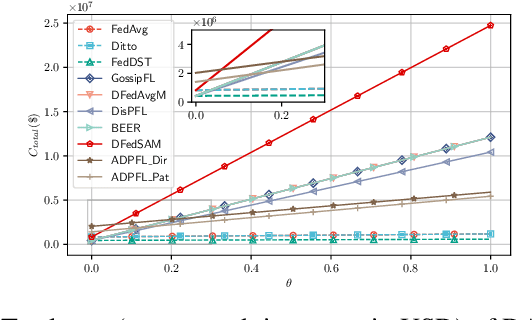

Decentralized Federated Learning (DFL) has become popular due to its robustness and avoidance of centralized coordination. In this paradigm, clients actively engage in training by exchanging models with their networked neighbors. However, DFL introduces increased costs in terms of training and communication. Existing methods focus on minimizing communication often overlooking training efficiency and data heterogeneity. To address this gap, we propose a novel \textit{sparse-to-sparser} training scheme: DA-DPFL. DA-DPFL initializes with a subset of model parameters, which progressively reduces during training via \textit{dynamic aggregation} and leads to substantial energy savings while retaining adequate information during critical learning periods. Our experiments showcase that DA-DPFL substantially outperforms DFL baselines in test accuracy, while achieving up to $5$ times reduction in energy costs. We provide a theoretical analysis of DA-DPFL's convergence by solidifying its applicability in decentralized and personalized learning. The code is available at:https://github.com/EricLoong/da-dpfl
S^2MVTC: a Simple yet Efficient Scalable Multi-View Tensor Clustering
Mar 14, 2024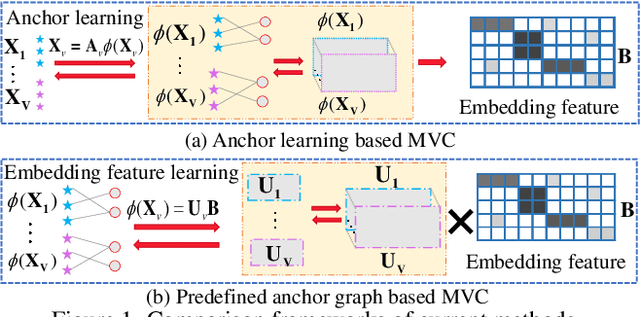

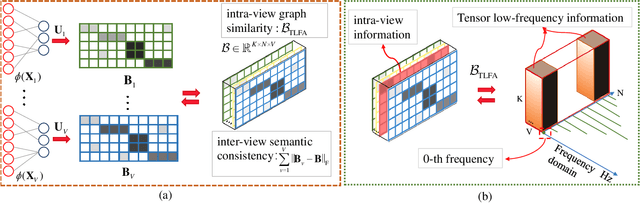
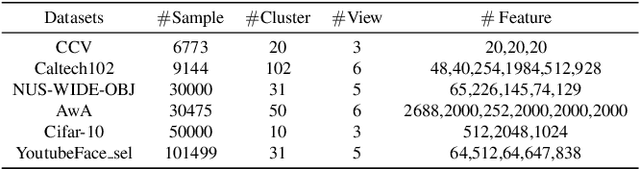
Anchor-based large-scale multi-view clustering has attracted considerable attention for its effectiveness in handling massive datasets. However, current methods mainly seek the consensus embedding feature for clustering by exploring global correlations between anchor graphs or projection matrices.In this paper, we propose a simple yet efficient scalable multi-view tensor clustering (S^2MVTC) approach, where our focus is on learning correlations of embedding features within and across views. Specifically, we first construct the embedding feature tensor by stacking the embedding features of different views into a tensor and rotating it. Additionally, we build a novel tensor low-frequency approximation (TLFA) operator, which incorporates graph similarity into embedding feature learning, efficiently achieving smooth representation of embedding features within different views. Furthermore, consensus constraints are applied to embedding features to ensure inter-view semantic consistency. Experimental results on six large-scale multi-view datasets demonstrate that S^2MVTC significantly outperforms state-of-the-art algorithms in terms of clustering performance and CPU execution time, especially when handling massive data. The code of S^2MVTC is publicly available at https://github.com/longzhen520/S2MVTC.
WeakSurg: Weakly supervised surgical instrument segmentation using temporal equivariance and semantic continuity
Mar 14, 2024
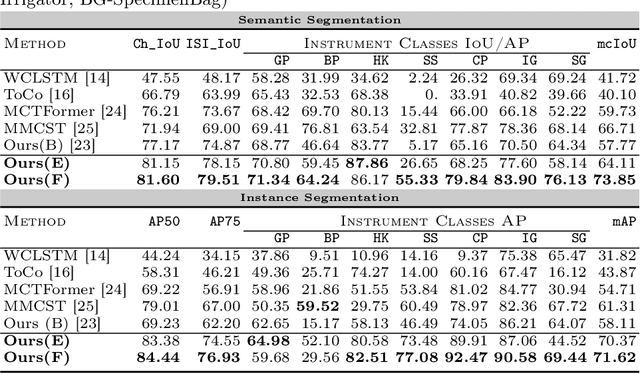


Weakly supervised surgical instrument segmentation with only instrument presence labels has been rarely explored in surgical domain. To mitigate the highly under-constrained challenges, we extend a two-stage weakly supervised segmentation paradigm with temporal attributes from two perspectives. From a temporal equivariance perspective, we propose a prototype-based temporal equivariance regulation loss to enhance pixel-wise consistency between adjacent features. From a semantic continuity perspective, we propose a class-aware temporal semantic continuity loss to constrain the semantic consistency between a global view of target frame and local non-discriminative regions of adjacent reference frame. To the best of our knowledge, WeakSurg is the first instrument-presence-only weakly supervised segmentation architecture to take temporal information into account for surgical scenarios. Extensive experiments are validated on Cholec80, an open benchmark for phase and instrument recognition. We annotate instance-wise instrument labels with fixed time-steps which are double checked by a clinician with 3-years experience. Our results show that WeakSurg compares favorably with state-of-the-art methods not only on semantic segmentation metrics but also on instance segmentation metrics.
Optimizing multi-user sound communications in reverberating environments with acoustic reconfigurable metasurfaces
Aug 03, 2023How do you ensure that, in a reverberant room, several people can speak simultaneously to several other people, making themselves perfectly understood and without any crosstalk between messages? In this work, we report a conceptual solution to this problem by developing an intelligent acoustic wall, which can be reconfigured electronically and is controlled by a learning algorithm that adapts to the geometry of the room and the positions of sources and receivers. To this end, a portion of the room boundaries is covered with a smart mirror made of a broadband acoustic reconfigurable metasurface (ARMs) designed to provide a two-state (0 or {\pi}) phase shift in the reflected waves by 200 independently tunable units. The whole phase pattern is optimized to maximize the Shannon capacity while minimizing crosstalk between the different sources and receivers. We demonstrate the control of multi-spectral sound fields covering a spectrum much larger than the coherence bandwidth of the room for diverse striking functionalities, including crosstalk-free acoustic communication, frequency-multiplexed communications, and multi-user communications. An experiment conducted with two music sources for two different people demonstrates a crosstalk-free simultaneous music playback. Our work opens new routes for the control of sound waves in complex media and for a new generation of acoustic devices.
Subjective and Objective Quality Assessment for in-the-Wild Computer Graphics Images
Mar 14, 2023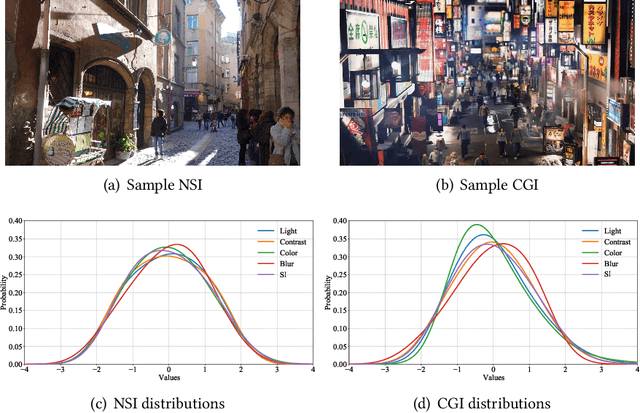
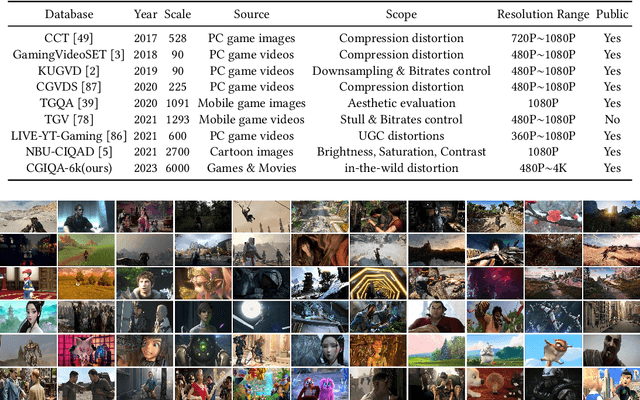

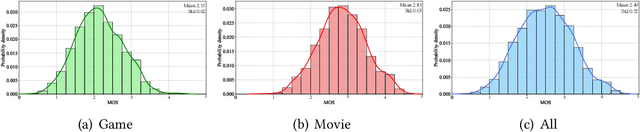
Computer graphics images (CGIs) are artificially generated by means of computer programs and are widely perceived under various scenarios, such as games, streaming media, etc. In practical, the quality of CGIs consistently suffers from poor rendering during the production and inevitable compression artifacts during the transmission of multimedia applications. However, few works have been dedicated to dealing with the challenge of computer graphics images quality assessment (CGIQA). Most image quality assessment (IQA) metrics are developed for natural scene images (NSIs) and validated on the databases consisting of NSIs with synthetic distortions, which are not suitable for in-the-wild CGIs. To bridge the gap between evaluating the quality of NSIs and CGIs, we construct a large-scale in-the-wild CGIQA database consisting of 6,000 CGIs (CGIQA-6k) and carry out the subjective experiment in a well-controlled laboratory environment to obtain the accurate perceptual ratings of the CGIs. Then, we propose an effective deep learning-based no-reference (NR) IQA model by utilizing multi-stage feature fusion strategy and multi-stage channel attention mechanism. The major motivation of the proposed model is to make full use of inter-channel information from low-level to high-level since CGIs have apparent patterns as well as rich interactive semantic content. Experimental results show that the proposed method outperforms all other state-of-the-art NR IQA methods on the constructed CGIQA-6k database and other CGIQA-related databases. The database along with the code will be released to facilitate further research.
MURPHY: Relations Matter in Surgical Workflow Analysis
Dec 24, 2022Autonomous robotic surgery has advanced significantly based on analysis of visual and temporal cues in surgical workflow, but relational cues from domain knowledge remain under investigation. Complex relations in surgical annotations can be divided into intra- and inter-relations, both valuable to autonomous systems to comprehend surgical workflows. Intra- and inter-relations describe the relevance of various categories within a particular annotation type and the relevance of different annotation types, respectively. This paper aims to systematically investigate the importance of relational cues in surgery. First, we contribute the RLLS12M dataset, a large-scale collection of robotic left lateral sectionectomy (RLLS), by curating 50 videos of 50 patients operated by 5 surgeons and annotating a hierarchical workflow, which consists of 3 inter- and 6 intra-relations, 6 steps, 15 tasks, and 38 activities represented as the triplet of 11 instruments, 8 actions, and 16 objects, totaling 2,113,510 video frames and 12,681,060 annotation entities. Correspondingly, we propose a multi-relation purification hybrid network (MURPHY), which aptly incorporates novel relation modules to augment the feature representation by purifying relational features using the intra- and inter-relations embodied in annotations. The intra-relation module leverages a R-GCN to implant visual features in different graph relations, which are aggregated using a targeted relation purification with affinity information measuring label consistency and feature similarity. The inter-relation module is motivated by attention mechanisms to regularize the influence of relational features based on the hierarchy of annotation types from the domain knowledge. Extensive experimental results on the curated RLLS dataset confirm the effectiveness of our approach, demonstrating that relations matter in surgical workflow analysis.