 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Robust Enhancement for Coastal Water Segmentation: A Systematic HSV-Guided Framework
Sep 10, 2025Coastal water segmentation from satellite imagery presents unique challenges due to complex spectral characteristics and irregular boundary patterns. Traditional RGB-based approaches often suffer from training instability and poor generalization in diverse maritime environments. This paper introduces a systematic robust enhancement framework, referred to as Robust U-Net, that leverages HSV color space supervision and multi-modal constraints for improved coastal water segmentation. Our approach integrates five synergistic components: HSV-guided color supervision, gradient-based coastline optimization, morphological post-processing, sea area cleanup, and connectivity control. Through comprehensive ablation studies, we demonstrate that HSV supervision provides the highest impact (0.85 influence score), while the complete framework achieves superior training stability (84\% variance reduction) and enhanced segmentation quality. Our method shows consistent improvements across multiple evaluation metrics while maintaining computational efficiency. For reproducibility, our training configurations and code are available here: https://github.com/UofgCoastline/ICASSP-2026-Robust-Unet.
A holistic perception system of internal and external monitoring for ground autonomous vehicles: AutoTRUST paradigm
Aug 25, 2025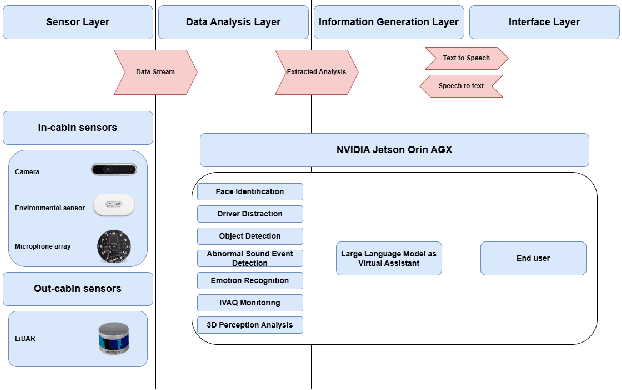


This paper introduces a holistic perception system for internal and external monitoring of autonomous vehicles, with the aim of demonstrating a novel AI-leveraged self-adaptive framework of advanced vehicle technologies and solutions that optimize perception and experience on-board. Internal monitoring system relies on a multi-camera setup designed for predicting and identifying driver and occupant behavior through facial recognition, exploiting in addition a large language model as virtual assistant. Moreover, the in-cabin monitoring system includes AI-empowered smart sensors that measure air-quality and perform thermal comfort analysis for efficient on and off-boarding. On the other hand, external monitoring system perceives the surrounding environment of vehicle, through a LiDAR-based cost-efficient semantic segmentation approach, that performs highly accurate and efficient super-resolution on low-quality raw 3D point clouds. The holistic perception framework is developed in the context of EU's Horizon Europe programm AutoTRUST, and has been integrated and deployed on a real electric vehicle provided by ALKE. Experimental validation and evaluation at the integration site of Joint Research Centre at Ispra, Italy, highlights increased performance and efficiency of the modular blocks of the proposed perception architecture.
FedPhD: Federated Pruning with Hierarchical Learning of Diffusion Models
Jul 08, 2025Federated Learning (FL), as a distributed learning paradigm, trains models over distributed clients' data. FL is particularly beneficial for distributed training of Diffusion Models (DMs), which are high-quality image generators that require diverse data. However, challenges such as high communication costs and data heterogeneity persist in training DMs similar to training Transformers and Convolutional Neural Networks. Limited research has addressed these issues in FL environments. To address this gap and challenges, we introduce a novel approach, FedPhD, designed to efficiently train DMs in FL environments. FedPhD leverages Hierarchical FL with homogeneity-aware model aggregation and selection policy to tackle data heterogeneity while reducing communication costs. The distributed structured pruning of FedPhD enhances computational efficiency and reduces model storage requirements in clients. Our experiments across multiple datasets demonstrate that FedPhD achieves high model performance regarding Fr\'echet Inception Distance (FID) scores while reducing communication costs by up to $88\%$. FedPhD outperforms baseline methods achieving at least a $34\%$ improvement in FID, while utilizing only $56\%$ of the total computation and communication resources.
STaRFormer: Semi-Supervised Task-Informed Representation Learning via Dynamic Attention-Based Regional Masking for Sequential Data
Apr 14, 2025



Accurate predictions using sequential spatiotemporal data are crucial for various applications. Utilizing real-world data, we aim to learn the intent of a smart device user within confined areas of a vehicle's surroundings. However, in real-world scenarios, environmental factors and sensor limitations result in non-stationary and irregularly sampled data, posing significant challenges. To address these issues, we developed a Transformer-based approach, STaRFormer, which serves as a universal framework for sequential modeling. STaRFormer employs a novel, dynamic attention-based regional masking scheme combined with semi-supervised contrastive learning to enhance task-specific latent representations. Comprehensive experiments on 15 datasets varying in types (including non-stationary and irregularly sampled), domains, sequence lengths, training samples, and applications, demonstrate the efficacy and practicality of STaRFormer. We achieve notable improvements over state-of-the-art approaches. Code and data will be made available.
Artificial Intelligence-Driven Clinical Decision Support Systems
Jan 16, 2025



As artificial intelligence (AI) becomes increasingly embedded in healthcare delivery, this chapter explores the critical aspects of developing reliable and ethical Clinical Decision Support Systems (CDSS). Beginning with the fundamental transition from traditional statistical models to sophisticated machine learning approaches, this work examines rigorous validation strategies and performance assessment methods, including the crucial role of model calibration and decision curve analysis. The chapter emphasizes that creating trustworthy AI systems in healthcare requires more than just technical accuracy; it demands careful consideration of fairness, explainability, and privacy. The challenge of ensuring equitable healthcare delivery through AI is stressed, discussing methods to identify and mitigate bias in clinical predictive models. The chapter then delves into explainability as a cornerstone of human-centered CDSS. This focus reflects the understanding that healthcare professionals must not only trust AI recommendations but also comprehend their underlying reasoning. The discussion advances in an analysis of privacy vulnerabilities in medical AI systems, from data leakage in deep learning models to sophisticated attacks against model explanations. The text explores privacy-preservation strategies such as differential privacy and federated learning, while acknowledging the inherent trade-offs between privacy protection and model performance. This progression, from technical validation to ethical considerations, reflects the multifaceted challenges of developing AI systems that can be seamlessly and reliably integrated into daily clinical practice while maintaining the highest standards of patient care and data protection.
Personalized Federated Learning for Cross-view Geo-localization
Nov 07, 2024



In this paper we propose a methodology combining Federated Learning (FL) with Cross-view Image Geo-localization (CVGL) techniques. We address the challenges of data privacy and heterogeneity in autonomous vehicle environments by proposing a personalized Federated Learning scenario that allows selective sharing of model parameters. Our method implements a coarse-to-fine approach, where clients share only the coarse feature extractors while keeping fine-grained features specific to local environments. We evaluate our approach against traditional centralized and single-client training schemes using the KITTI dataset combined with satellite imagery. Results demonstrate that our federated CVGL method achieves performance close to centralized training while maintaining data privacy. The proposed partial model sharing strategy shows comparable or slightly better performance than classical FL, offering significant reduced communication overhead without sacrificing accuracy. Our work contributes to more robust and privacy-preserving localization systems for autonomous vehicles operating in diverse environments
Decentralized Personalized Federated Learning based on a Conditional Sparse-to-Sparser Scheme
Apr 25, 2024

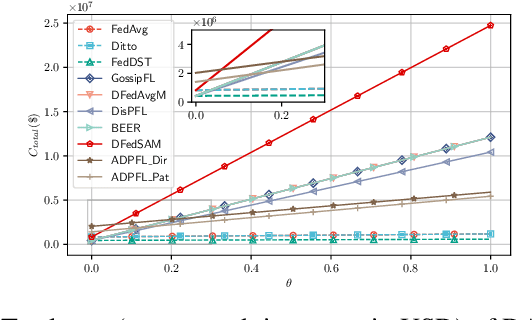

Decentralized Federated Learning (DFL) has become popular due to its robustness and avoidance of centralized coordination. In this paradigm, clients actively engage in training by exchanging models with their networked neighbors. However, DFL introduces increased costs in terms of training and communication. Existing methods focus on minimizing communication often overlooking training efficiency and data heterogeneity. To address this gap, we propose a novel \textit{sparse-to-sparser} training scheme: DA-DPFL. DA-DPFL initializes with a subset of model parameters, which progressively reduces during training via \textit{dynamic aggregation} and leads to substantial energy savings while retaining adequate information during critical learning periods. Our experiments showcase that DA-DPFL substantially outperforms DFL baselines in test accuracy, while achieving up to $5$ times reduction in energy costs. We provide a theoretical analysis of DA-DPFL's convergence by solidifying its applicability in decentralized and personalized learning. The code is available at:https://github.com/EricLoong/da-dpfl
FedDIP: Federated Learning with Extreme Dynamic Pruning and Incremental Regularization
Sep 13, 2023Federated Learning (FL) has been successfully adopted for distributed training and inference of large-scale Deep Neural Networks (DNNs). However, DNNs are characterized by an extremely large number of parameters, thus, yielding significant challenges in exchanging these parameters among distributed nodes and managing the memory. Although recent DNN compression methods (e.g., sparsification, pruning) tackle such challenges, they do not holistically consider an adaptively controlled reduction of parameter exchange while maintaining high accuracy levels. We, therefore, contribute with a novel FL framework (coined FedDIP), which combines (i) dynamic model pruning with error feedback to eliminate redundant information exchange, which contributes to significant performance improvement, with (ii) incremental regularization that can achieve \textit{extreme} sparsity of models. We provide convergence analysis of FedDIP and report on a comprehensive performance and comparative assessment against state-of-the-art methods using benchmark data sets and DNN models. Our results showcase that FedDIP not only controls the model sparsity but efficiently achieves similar or better performance compared to other model pruning methods adopting incremental regularization during distributed model training. The code is available at: https://github.com/EricLoong/feddip.
Real time enhancement of operator's ergonomics in physical human - robot collaboration scenarios using a multi-stereo camera system
Apr 11, 2023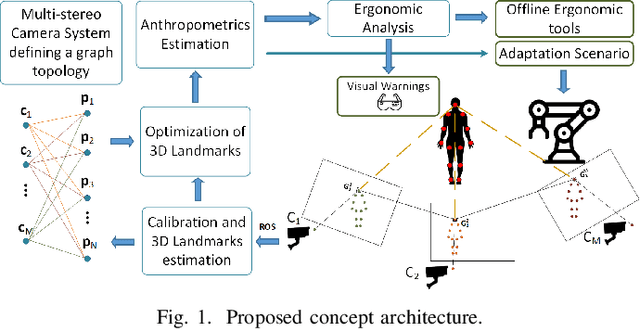
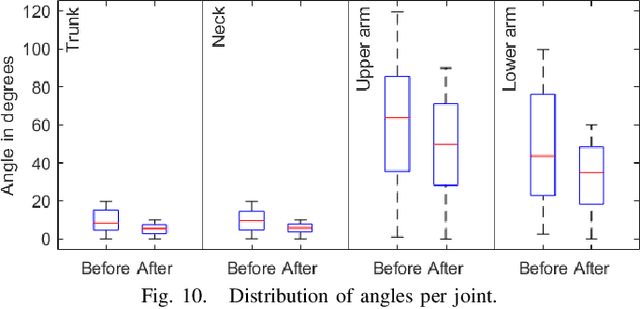

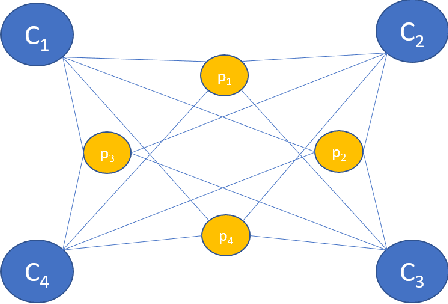
In collaborative tasks where humans work alongside machines, the robot's movements and behaviour can have a significant impact on the operator's safety, health, and comfort. To address this issue, we present a multi-stereo camera system that continuously monitors the operator's posture while they work with the robot. This system uses a novel distributed fusion approach to assess the operator's posture in real-time and to help avoid uncomfortable or unsafe positions. The system adjusts the robot's movements and informs the operator of any incorrect or potentially harmful postures, reducing the risk of accidents, strain, and musculoskeletal disorders. The analysis is personalized, taking into account the unique anthropometric characteristics of each operator, to ensure optimal ergonomics. The results of our experiments show that the proposed approach leads to improved human body postures and offers a promising solution for enhancing the ergonomics of operators in collaborative tasks.
Optimizing Vision Transformers for Medical Image Segmentation and Few-Shot Domain Adaptation
Oct 14, 2022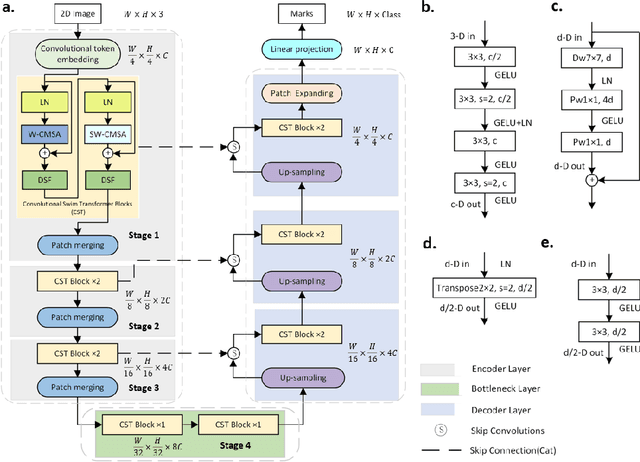
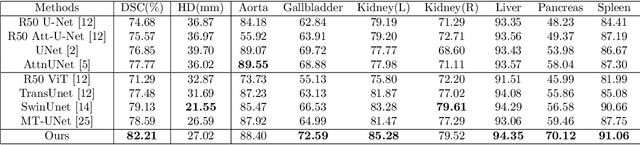
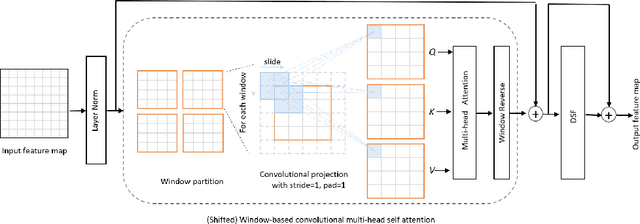
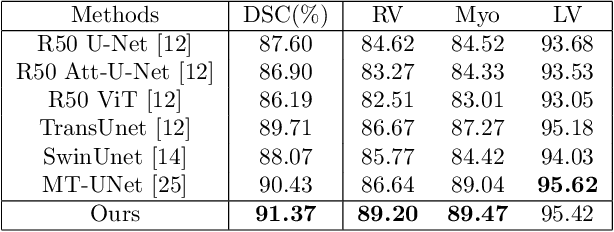
The adaptation of transformers to computer vision is not straightforward because the modelling of image contextual information results in quadratic computational complexity with relation to the input features. Most of existing methods require extensive pre-training on massive datasets such as ImageNet and therefore their application to fields such as healthcare is less effective. CNNs are the dominant architecture in computer vision tasks because convolutional filters can effectively model local dependencies and reduce drastically the parameters required. However, convolutional filters cannot handle more complex interactions, which are beyond a small neighbour of pixels. Furthermore, their weights are fixed after training and thus they do not take into consideration changes in the visual input. Inspired by recent work on hybrid visual transformers with convolutions and hierarchical transformers, we propose Convolutional Swin-Unet (CS-Unet) transformer blocks and optimise their settings with relation to patch embedding, projection, the feed-forward network, up sampling and skip connections. CS-Unet can be trained from scratch and inherits the superiority of convolutions in each feature process phase. It helps to encode precise spatial information and produce hierarchical representations that contribute to object concepts at various scales. Experiments show that CS-Unet without pre-training surpasses other state-of-the-art counterparts by large margins on two medical CT and MRI datasets with fewer parameters. In addition, two domain-adaptation experiments on optic disc and polyp image segmentation further prove that our method is highly generalizable and effectively bridges the domain gap between images from different sources.