 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA holistic perception system of internal and external monitoring for ground autonomous vehicles: AutoTRUST paradigm
Aug 25, 2025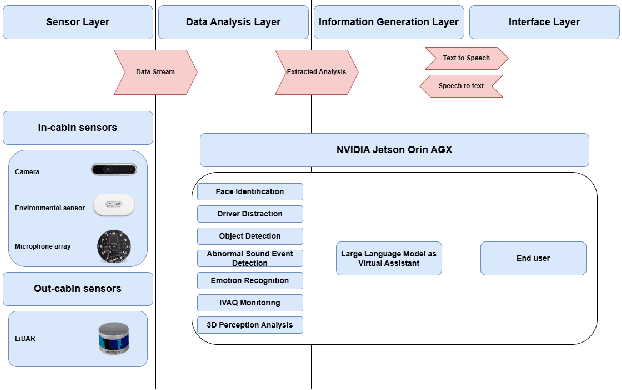

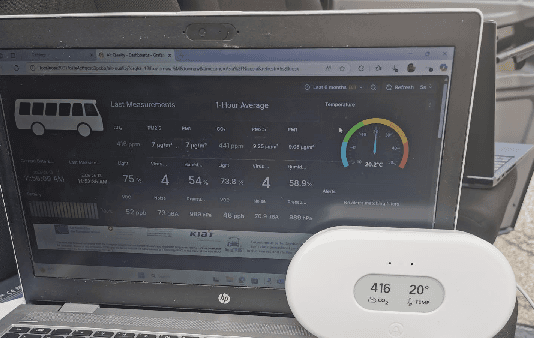

This paper introduces a holistic perception system for internal and external monitoring of autonomous vehicles, with the aim of demonstrating a novel AI-leveraged self-adaptive framework of advanced vehicle technologies and solutions that optimize perception and experience on-board. Internal monitoring system relies on a multi-camera setup designed for predicting and identifying driver and occupant behavior through facial recognition, exploiting in addition a large language model as virtual assistant. Moreover, the in-cabin monitoring system includes AI-empowered smart sensors that measure air-quality and perform thermal comfort analysis for efficient on and off-boarding. On the other hand, external monitoring system perceives the surrounding environment of vehicle, through a LiDAR-based cost-efficient semantic segmentation approach, that performs highly accurate and efficient super-resolution on low-quality raw 3D point clouds. The holistic perception framework is developed in the context of EU's Horizon Europe programm AutoTRUST, and has been integrated and deployed on a real electric vehicle provided by ALKE. Experimental validation and evaluation at the integration site of Joint Research Centre at Ispra, Italy, highlights increased performance and efficiency of the modular blocks of the proposed perception architecture.
Optimizing Cooperative Multi-Object Tracking using Graph Signal Processing
Jun 11, 2025Multi-Object Tracking (MOT) plays a crucial role in autonomous driving systems, as it lays the foundations for advanced perception and precise path planning modules. Nonetheless, single agent based MOT lacks in sensing surroundings due to occlusions, sensors failures, etc. Hence, the integration of multiagent information is essential for comprehensive understanding of the environment. This paper proposes a novel Cooperative MOT framework for tracking objects in 3D LiDAR scene by formulating and solving a graph topology-aware optimization problem so as to fuse information coming from multiple vehicles. By exploiting a fully connected graph topology defined by the detected bounding boxes, we employ the Graph Laplacian processing optimization technique to smooth the position error of bounding boxes and effectively combine them. In that manner, we reveal and leverage inherent coherences of diverse multi-agent detections, and associate the refined bounding boxes to tracked objects at two stages, optimizing localization and tracking accuracies. An extensive evaluation study has been conducted, using the real-world V2V4Real dataset, where the proposed method significantly outperforms the baseline frameworks, including the state-of-the-art deep-learning DMSTrack and V2V4Real, in various testing sequences.
Personalized Federated Learning for Cross-view Geo-localization
Nov 07, 2024



In this paper we propose a methodology combining Federated Learning (FL) with Cross-view Image Geo-localization (CVGL) techniques. We address the challenges of data privacy and heterogeneity in autonomous vehicle environments by proposing a personalized Federated Learning scenario that allows selective sharing of model parameters. Our method implements a coarse-to-fine approach, where clients share only the coarse feature extractors while keeping fine-grained features specific to local environments. We evaluate our approach against traditional centralized and single-client training schemes using the KITTI dataset combined with satellite imagery. Results demonstrate that our federated CVGL method achieves performance close to centralized training while maintaining data privacy. The proposed partial model sharing strategy shows comparable or slightly better performance than classical FL, offering significant reduced communication overhead without sacrificing accuracy. Our work contributes to more robust and privacy-preserving localization systems for autonomous vehicles operating in diverse environments
Real time enhancement of operator's ergonomics in physical human - robot collaboration scenarios using a multi-stereo camera system
Apr 11, 2023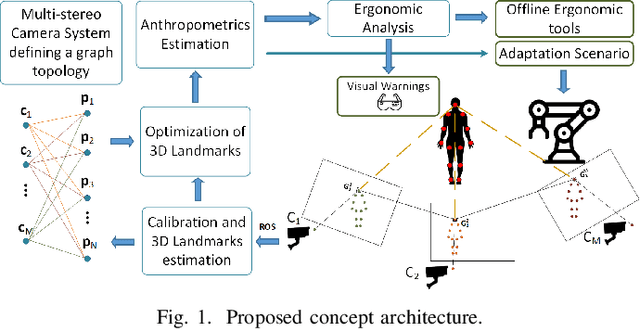
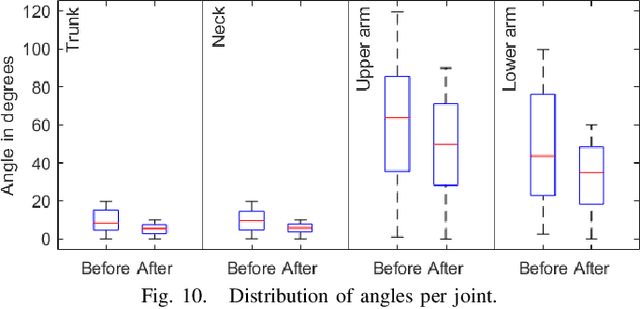

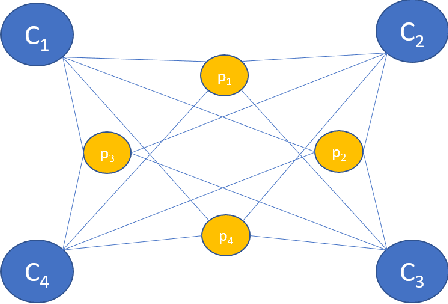
In collaborative tasks where humans work alongside machines, the robot's movements and behaviour can have a significant impact on the operator's safety, health, and comfort. To address this issue, we present a multi-stereo camera system that continuously monitors the operator's posture while they work with the robot. This system uses a novel distributed fusion approach to assess the operator's posture in real-time and to help avoid uncomfortable or unsafe positions. The system adjusts the robot's movements and informs the operator of any incorrect or potentially harmful postures, reducing the risk of accidents, strain, and musculoskeletal disorders. The analysis is personalized, taking into account the unique anthropometric characteristics of each operator, to ensure optimal ergonomics. The results of our experiments show that the proposed approach leads to improved human body postures and offers a promising solution for enhancing the ergonomics of operators in collaborative tasks.
Fast mesh denoising with data driven normal filtering using deep variational autoencoders
Nov 24, 2021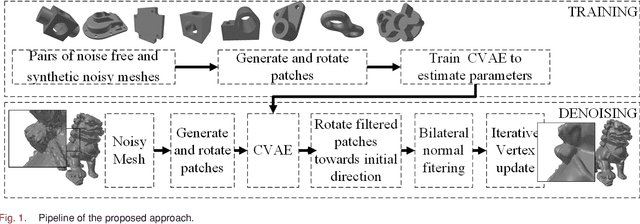
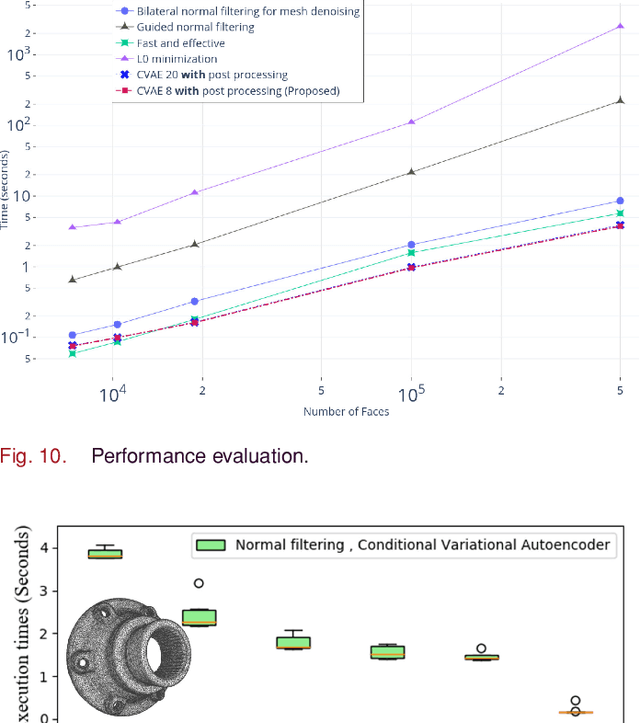
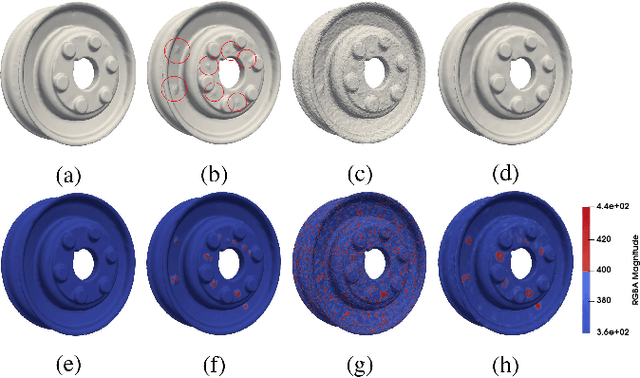
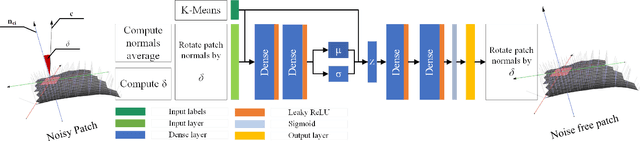
Recent advances in 3D scanning technology have enabled the deployment of 3D models in various industrial applications like digital twins, remote inspection and reverse engineering. Despite their evolving performance, 3D scanners, still introduce noise and artifacts in the acquired dense models. In this work, we propose a fast and robust denoising method for dense 3D scanned industrial models. The proposed approach employs conditional variational autoencoders to effectively filter face normals. Training and inference are performed in a sliding patch setup reducing the size of the required training data and execution times. We conducted extensive evaluation studies using 3D scanned and CAD models. The results verify plausible denoising outcomes, demonstrating similar or higher reconstruction accuracy, compared to other state-of-the-art approaches. Specifically, for 3D models with more than 1e4 faces, the presented pipeline is twice as fast as methods with equivalent reconstruction error.
* 12 pages, 12 figures
Fast Spatio-temporal Compression of Dynamic 3D Meshes
Nov 19, 2021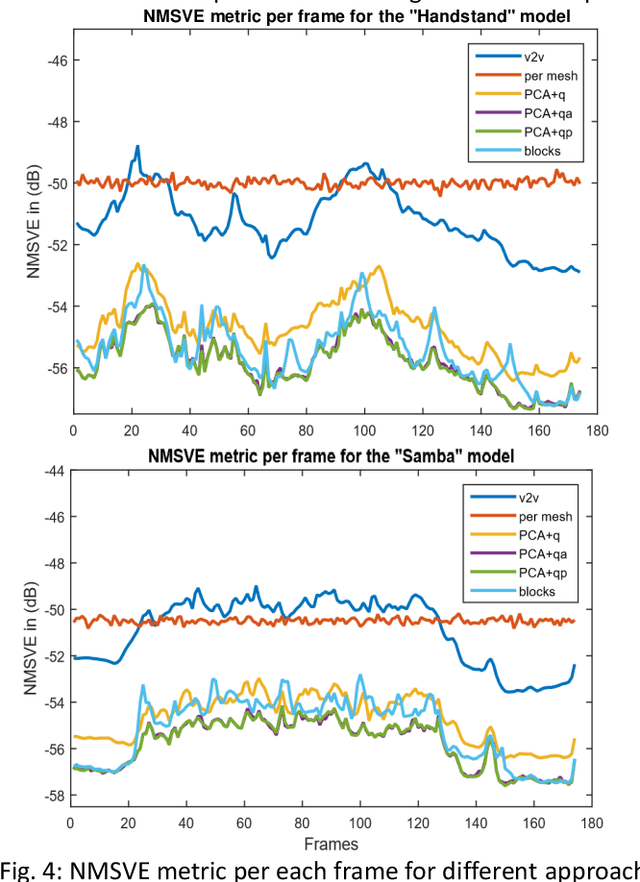
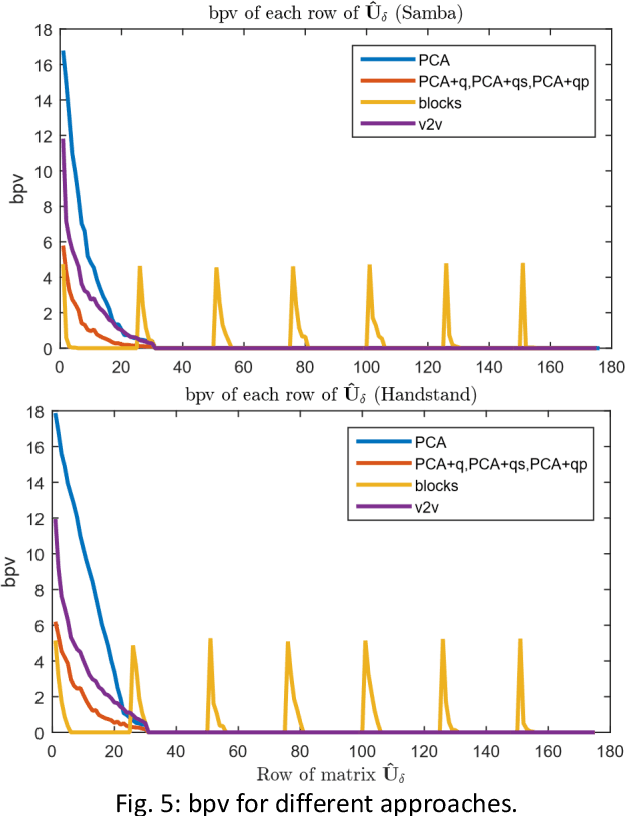

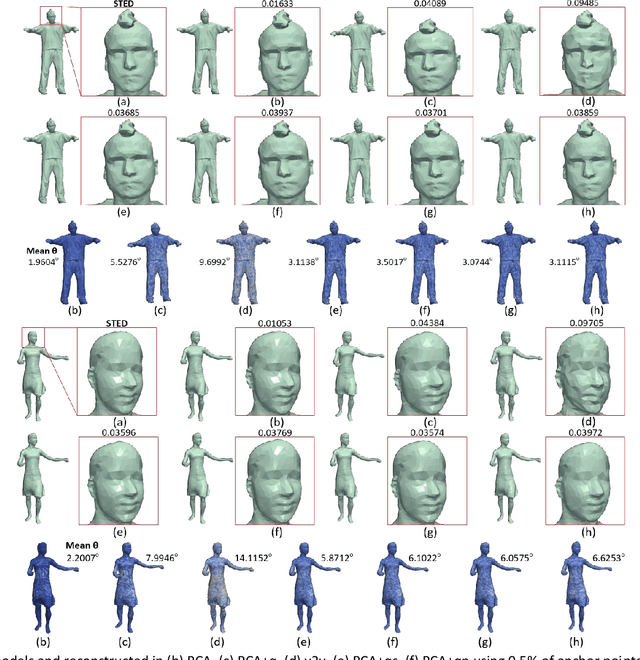
3D representations of highly deformable 3D models, such as dynamic 3D meshes, have recently become very popular due to their wide applicability in various domains. This trend inevitably leads to a demand for storage and transmission of voluminous data sets, making the need for the design of a robust and reliable compression scheme a necessity. In this work, we present an approach for dynamic 3D mesh compression, that effectively exploits the spatio-temporal coherence of animated sequences, achieving low compression ratios without noticeably affecting the visual quality of the animation. We show that, on contrary to mainstream approaches that either exploit spatial (e.g., spectral coding) or temporal redundancies (e.g., PCA-based method), the proposed scheme, achieves increased efficiency, by projecting the differential coordinates sequence to the subspace of the covariance of the point trajectories. An extensive evaluation study, using different dynamic 3D models, highlights the benefits of the proposed approach in terms of both execution time and reconstruction quality, providing extremely low bit-per-vertex per-frame (bpvf) rates.
Graph Laplacian Diffusion Localization of Connected and Automated Vehicles
Aug 24, 2021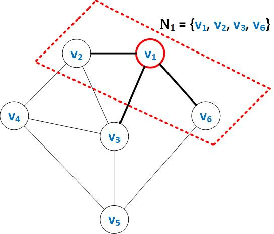
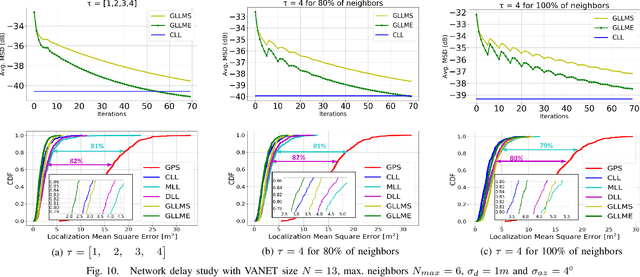
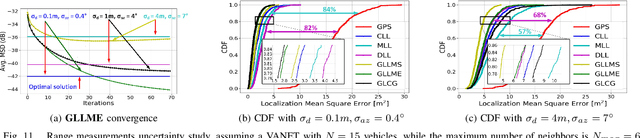
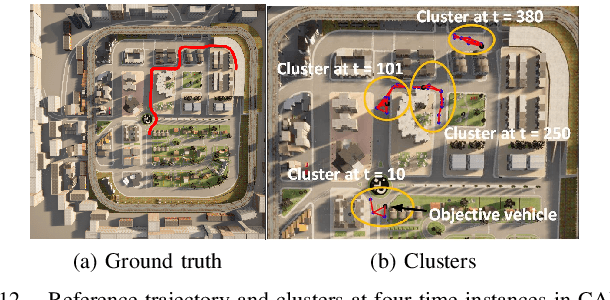
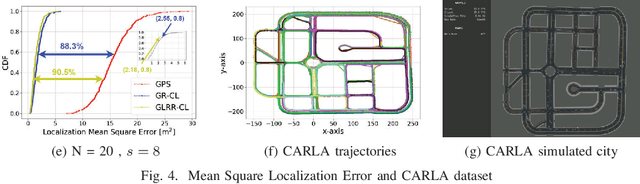
In this paper, we design distributed multi-modal localization approaches for Connected and Automated vehicles. We utilize information diffusion on graphs formed by moving vehicles, based on Adapt-then-Combine strategies combined with the Least-Mean-Squares and the Conjugate Gradient algorithms. We treat the vehicular network as an undirected graph, where vehicles communicate with each other by means of Vehicle-to- Vehicle communication protocols. Connected vehicles perform cooperative fusion of different measurement modalities, including location and range measurements, in order to estimate both their positions and the positions of all other networked vehicles, by interacting only with their local neighborhood. The trajectories of vehicles were generated either by a well-known kinematic model, or by using the CARLA autonomous driving simulator. The various proposed distributed and diffusion localization schemes significantly reduce the GPS error and do not only converge to the global solution, but they even outperformed it. Extensive simulation studies highlight the benefits of the various approaches, outperforming the accuracy of the state of the art approaches. The impact of the network connections and the network latency are also investigated.
Accelerating deep neural networks for efficient scene understanding in automotive cyber-physical systems
Jul 19, 2021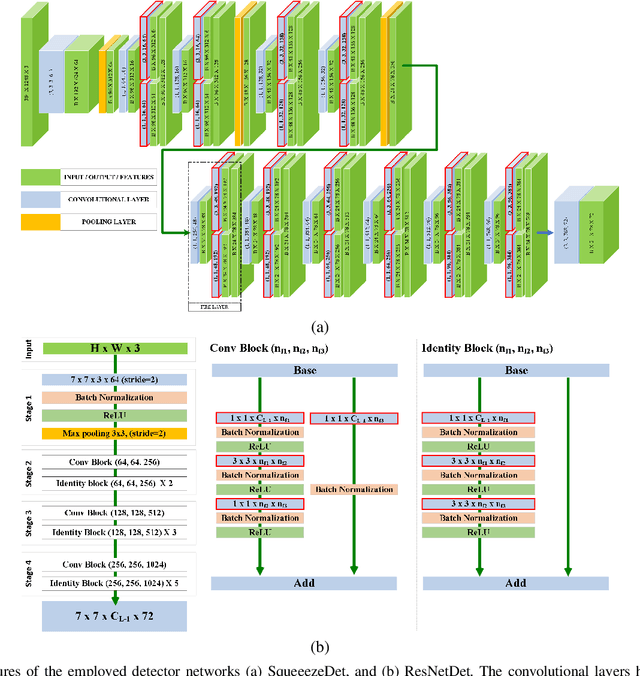
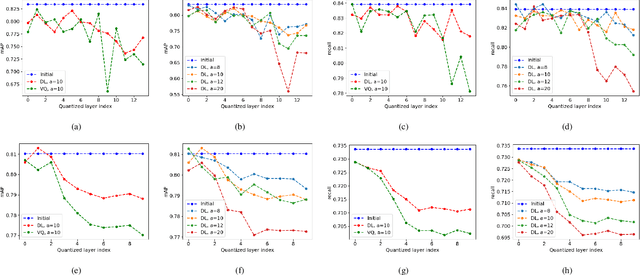

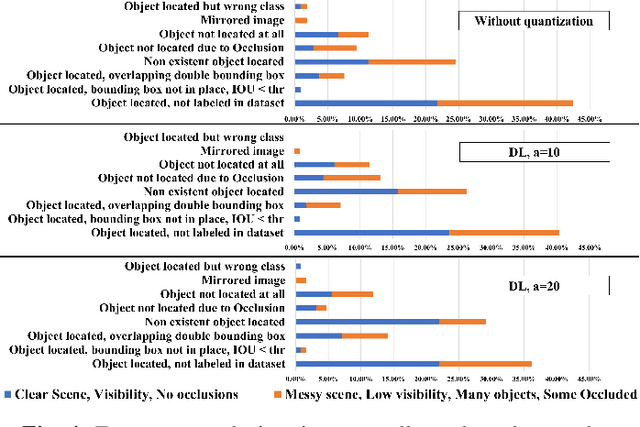
Automotive Cyber-Physical Systems (ACPS) have attracted a significant amount of interest in the past few decades, while one of the most critical operations in these systems is the perception of the environment. Deep learning and, especially, the use of Deep Neural Networks (DNNs) provides impressive results in analyzing and understanding complex and dynamic scenes from visual data. The prediction horizons for those perception systems are very short and inference must often be performed in real time, stressing the need of transforming the original large pre-trained networks into new smaller models, by utilizing Model Compression and Acceleration (MCA) techniques. Our goal in this work is to investigate best practices for appropriately applying novel weight sharing techniques, optimizing the available variables and the training procedures towards the significant acceleration of widely adopted DNNs. Extensive evaluation studies carried out using various state-of-the-art DNN models in object detection and tracking experiments, provide details about the type of errors that manifest after the application of weight sharing techniques, resulting in significant acceleration gains with negligible accuracy losses.
A New Clustering-Based Technique for the Acceleration of Deep Convolutional Networks
Jul 19, 2021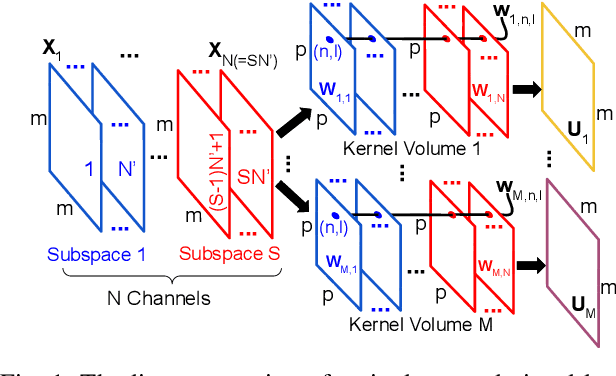
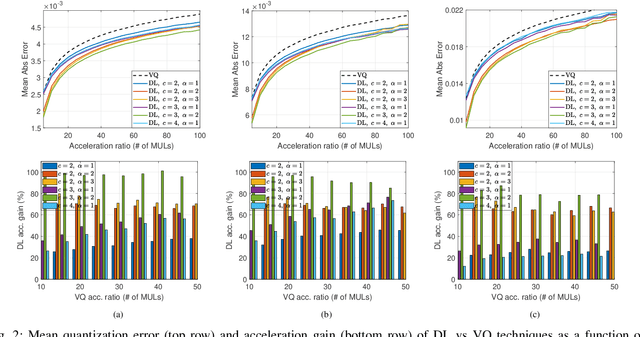
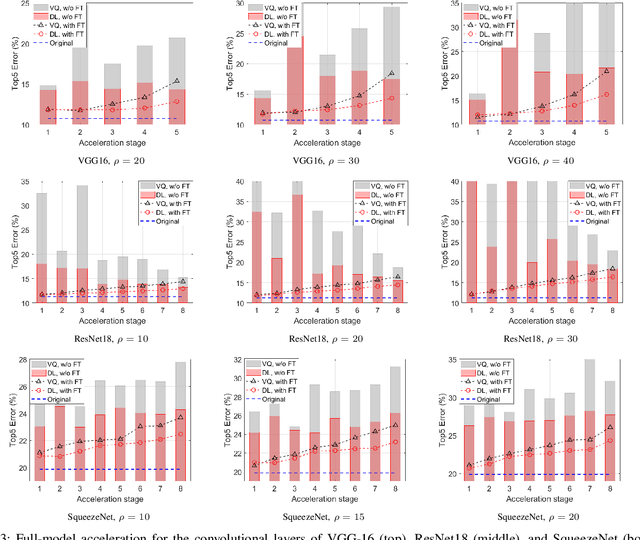

Deep learning and especially the use of Deep Neural Networks (DNNs) provides impressive results in various regression and classification tasks. However, to achieve these results, there is a high demand for computing and storing resources. This becomes problematic when, for instance, real-time, mobile applications are considered, in which the involved (embedded) devices have limited resources. A common way of addressing this problem is to transform the original large pre-trained networks into new smaller models, by utilizing Model Compression and Acceleration (MCA) techniques. Within the MCA framework, we propose a clustering-based approach that is able to increase the number of employed centroids/representatives, while at the same time, have an acceleration gain compared to conventional, $k$-means based approaches. This is achieved by imposing a special structure to the employed representatives, which is enabled by the particularities of the problem at hand. Moreover, the theoretical acceleration gains are presented and the key system hyper-parameters that affect that gain, are identified. Extensive evaluation studies carried out using various state-of-the-art DNN models trained in image classification, validate the superiority of the proposed method as compared for its use in MCA tasks.
Cooperative Multi-Modal Localization in Connected and Autonomous Vehicles
Jul 16, 2021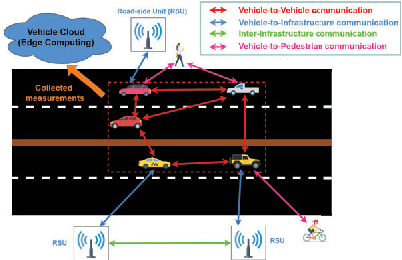
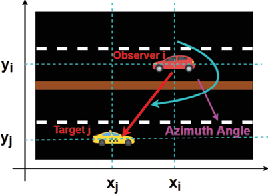
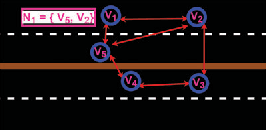
Cooperative Localization is expected to play a crucial role in various applications in the field of Connected and Autonomous vehicles (CAVs). Future 5G wireless systems are expected to enable cost-effective Vehicle-to-Everything (V2X)systems, allowing CAVs to share with the other entities of the network the data they collect and measure. Typical measurement models usually deployed for this problem, are absolute position from Global Positioning System (GPS), relative distance and azimuth angle to neighbouring vehicles, extracted from Light Detection and Ranging (LIDAR) or Radio Detection and Ranging(RADAR) sensors. In this paper, we provide a cooperative localization approach that performs multi modal-fusion between the interconnected vehicles, by representing a fleet of connected cars as an undirected graph, encoding each vehicle position relative to its neighbouring vehicles. This method is based on:i) the Laplacian Processing, a Graph Signal Processing tool that allows to capture intrinsic geometry of the undirected graph of vehicles rather than their absolute position on global coordinate system and ii) the temporal coherence due to motion patterns of the moving vehicles.