 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Fully Distributed Federated Learning with Adaptive Local Links
Mar 23, 2022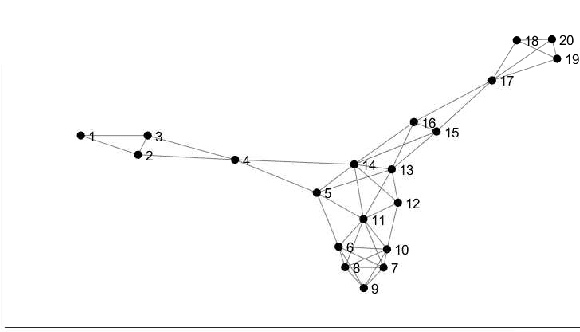
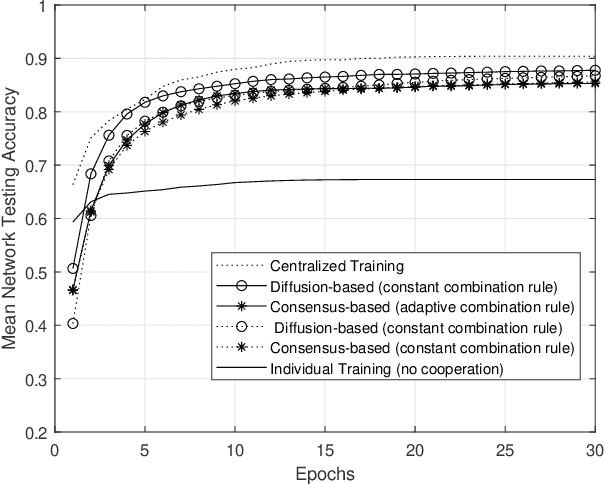
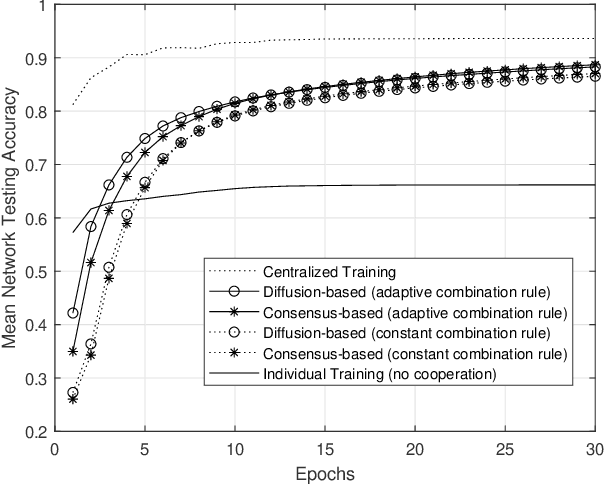
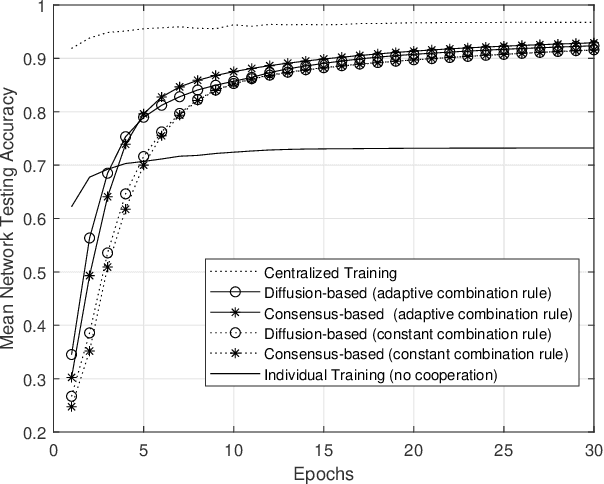
Nowadays, data-driven, machine and deep learning approaches have provided unprecedented performance in various complex tasks, including image classification and object detection, and in a variety of application areas, like autonomous vehicles, medical imaging and wireless communications. Traditionally, such approaches have been deployed, along with the involved datasets, on standalone devices. Recently, a shift has been observed towards the so-called Edge Machine Learning, in which centralized architectures are adopted that allow multiple devices with local computational and storage resources to collaborate with the assistance of a centralized server. The well-known federated learning approach is able to utilize such architectures by allowing the exchange of only parameters with the server, while keeping the datasets private to each contributing device. In this work, we propose a fully distributed, diffusion-based learning algorithm that does not require a central server and propose an adaptive combination rule for the cooperation of the devices. By adopting a classification task on the MNIST dataset, the efficacy of the proposed algorithm over corresponding counterparts is demonstrated via the reduction of the number of collaboration rounds required to achieve an acceptable accuracy level in non- IID dataset scenarios.
Accelerating deep neural networks for efficient scene understanding in automotive cyber-physical systems
Jul 19, 2021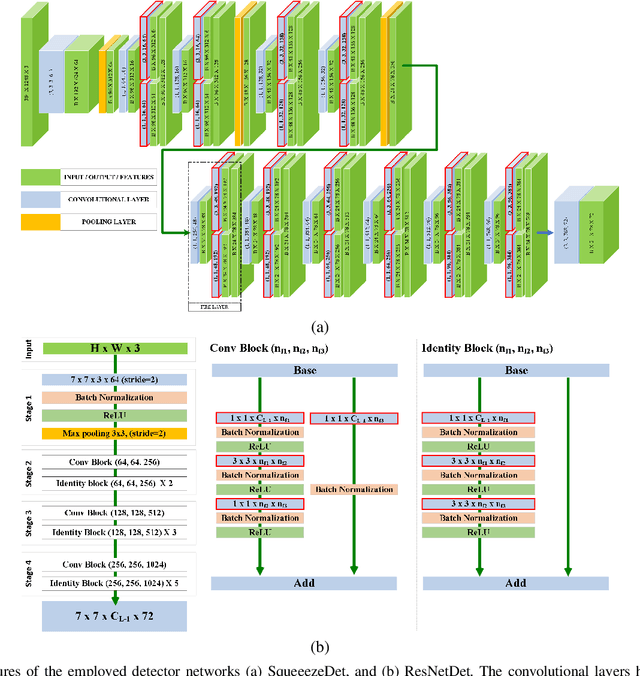
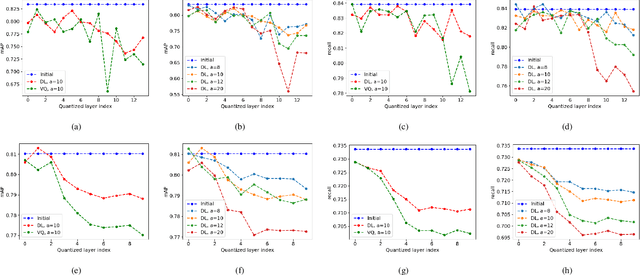

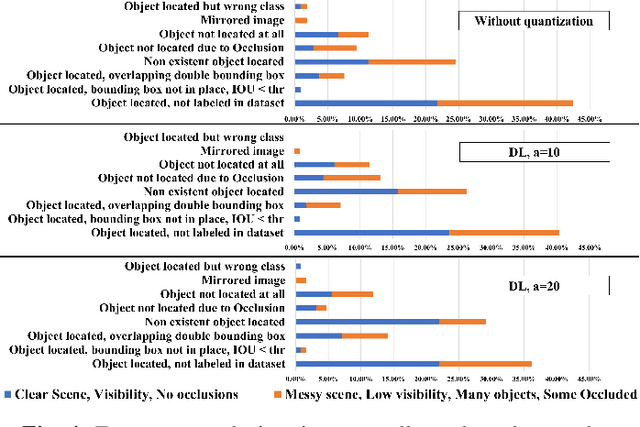
Automotive Cyber-Physical Systems (ACPS) have attracted a significant amount of interest in the past few decades, while one of the most critical operations in these systems is the perception of the environment. Deep learning and, especially, the use of Deep Neural Networks (DNNs) provides impressive results in analyzing and understanding complex and dynamic scenes from visual data. The prediction horizons for those perception systems are very short and inference must often be performed in real time, stressing the need of transforming the original large pre-trained networks into new smaller models, by utilizing Model Compression and Acceleration (MCA) techniques. Our goal in this work is to investigate best practices for appropriately applying novel weight sharing techniques, optimizing the available variables and the training procedures towards the significant acceleration of widely adopted DNNs. Extensive evaluation studies carried out using various state-of-the-art DNN models in object detection and tracking experiments, provide details about the type of errors that manifest after the application of weight sharing techniques, resulting in significant acceleration gains with negligible accuracy losses.
A New Clustering-Based Technique for the Acceleration of Deep Convolutional Networks
Jul 19, 2021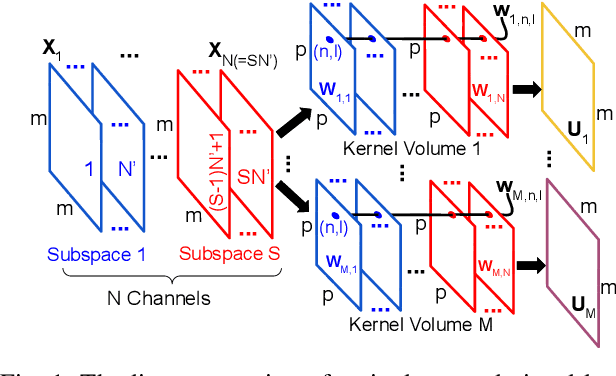
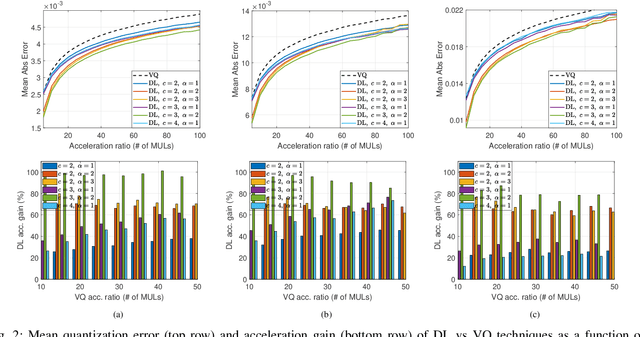
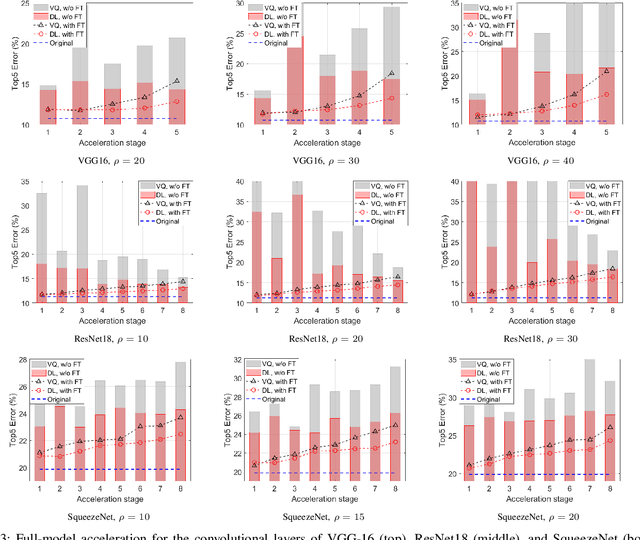

Deep learning and especially the use of Deep Neural Networks (DNNs) provides impressive results in various regression and classification tasks. However, to achieve these results, there is a high demand for computing and storing resources. This becomes problematic when, for instance, real-time, mobile applications are considered, in which the involved (embedded) devices have limited resources. A common way of addressing this problem is to transform the original large pre-trained networks into new smaller models, by utilizing Model Compression and Acceleration (MCA) techniques. Within the MCA framework, we propose a clustering-based approach that is able to increase the number of employed centroids/representatives, while at the same time, have an acceleration gain compared to conventional, $k$-means based approaches. This is achieved by imposing a special structure to the employed representatives, which is enabled by the particularities of the problem at hand. Moreover, the theoretical acceleration gains are presented and the key system hyper-parameters that affect that gain, are identified. Extensive evaluation studies carried out using various state-of-the-art DNN models trained in image classification, validate the superiority of the proposed method as compared for its use in MCA tasks.