 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFatigueFusion: Latent Space Fusion for Fatigue-Driven Motion Synthesis
Apr 11, 2026Investigating the impact of fatigue on human physiological function and motor behavior is crucial for developing biomechanics and medical applications aimed at mitigating fatigue, reducing injury risk, and creating sophisticated ergonomic designs, as well as for producing physically-plausible 3D animation sequences. While the former has a prominent position in state-of-the-art literature, fatigue-driven motion generation is still an underexplored area. In this study, we present FatigueFusion, a deep-learning architecture for the fusion of fatigue features within a latent representation space, enabling the creation of a variation of novel fatigued movements, intermediate fatigued states, and progressively fatigued motions. Unlike existing approaches that focus on imitating the effects of fatigue accumulation in motion patterns, our framework incorporates algorithmic and data-driven modules to impose subject-specific temporal and spatial fatigue features on nonfatigued motions, while leveraging PINN-based techniques to simulate fatigue intensity. Since all motion modulation tasks are taking place in latent space, FatigueFusion offers an end-to-end architecture that operates directly on non-fatigued joint angle sequences and control parameters, allowing seamless integration into any motion synthesis pipeline, without relying on fatigue input data. Overall, our framework can be employed for various fatigue-driven synthesis tasks, such as fatigue profile transfer and fusion, while it also provides a solution for accurate rendering of the human fatigue state in both animation and simulation pipelines.
Fatigue-PINN: Physics-Informed Fatigue-Driven Motion Modulation and Synthesis
Feb 26, 2025Fatigue modeling is essential for motion synthesis tasks to model human motions under fatigued conditions and biomechanical engineering applications, such as investigating the variations in movement patterns and posture due to fatigue, defining injury risk mitigation and prevention strategies, formulating fatigue minimization schemes and creating improved ergonomic designs. Nevertheless, employing data-driven methods for synthesizing the impact of fatigue on motion, receives little to no attention in the literature. In this work, we present Fatigue-PINN, a deep learning framework based on Physics-Informed Neural Networks, for modeling fatigued human movements, while providing joint-specific fatigue configurations for adaptation and mitigation of motion artifacts on a joint level, resulting in more realistic animations. To account for muscle fatigue, we simulate the fatigue-induced fluctuations in the maximum exerted joint torques by leveraging a PINN adaptation of the Three-Compartment Controller model to exploit physics-domain knowledge for improving accuracy. This model also introduces parametric motion alignment with respect to joint-specific fatigue, hence avoiding sharp frame transitions. Our results indicate that Fatigue-PINN accurately simulates the effects of externally perceived fatigue on open-type human movements being consistent with findings from real-world experimental fatigue studies. Since fatigue is incorporated in torque space, Fatigue-PINN provides an end-to-end encoder-decoder-like architecture, to ensure transforming joint angles to joint torques and vice-versa, thus, being compatible with motion synthesis frameworks operating on joint angles.
Effectiveness of L2 Regularization in Privacy-Preserving Machine Learning
Dec 02, 2024Artificial intelligence, machine learning, and deep learning as a service have become the status quo for many industries, leading to the widespread deployment of models that handle sensitive data. Well-performing models, the industry seeks, usually rely on a large volume of training data. However, the use of such data raises serious privacy concerns due to the potential risks of leaks of highly sensitive information. One prominent threat is the Membership Inference Attack, where adversaries attempt to deduce whether a specific data point was used in a model's training process. An adversary's ability to determine an individual's presence represents a significant privacy threat, especially when related to a group of users sharing sensitive information. Hence, well-designed privacy-preserving machine learning solutions are critically needed in the industry. In this work, we compare the effectiveness of L2 regularization and differential privacy in mitigating Membership Inference Attack risks. Even though regularization techniques like L2 regularization are commonly employed to reduce overfitting, a condition that enhances the effectiveness of Membership Inference Attacks, their impact on mitigating these attacks has not been systematically explored.
PReP: Efficient context-based shape retrieval for missing parts
Oct 18, 2024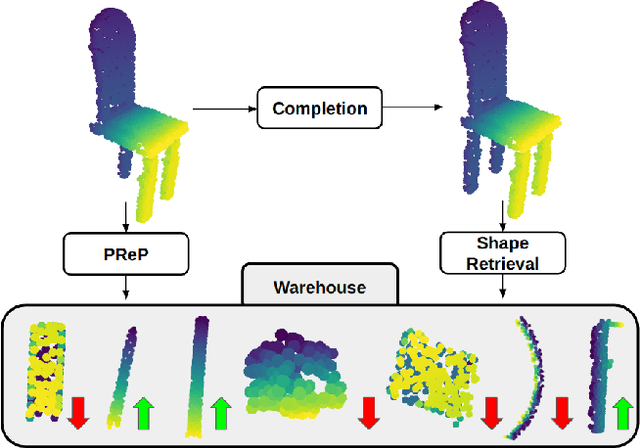
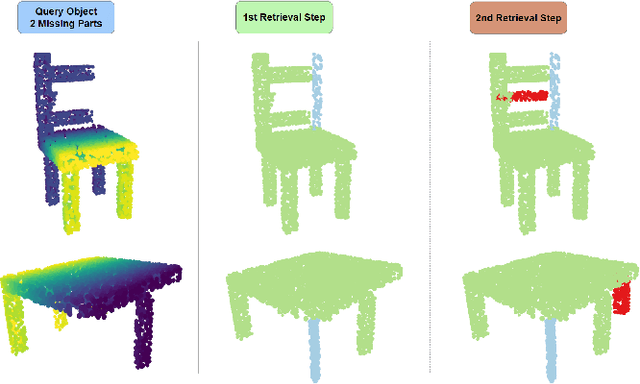
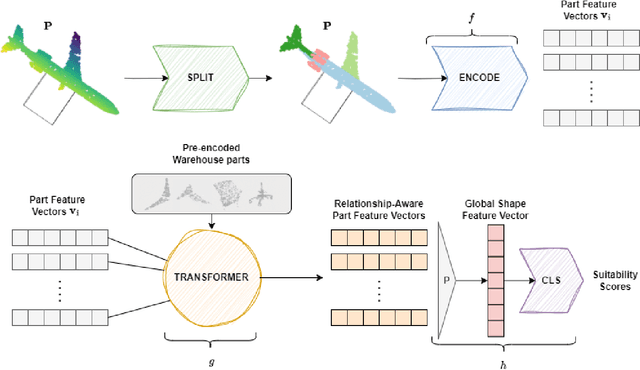
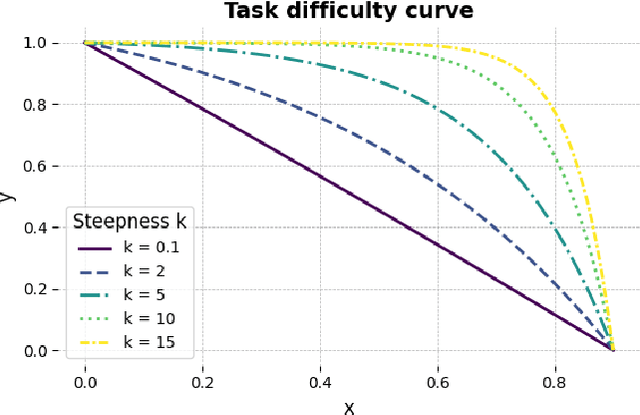
In this paper we study the problem of shape part retrieval in the point cloud domain. Shape retrieval methods in the literature rely on the presence of an existing query object, but what if the part we are looking for is not available? We present Part Retrieval Pipeline (PReP), a pipeline that creatively utilizes metric learning techniques along with a trained classification model to measure the suitability of potential replacement parts from a database, as part of an application scenario targeting circular economy. Through an innovative training procedure with increasing difficulty, it is able to learn to recognize suitable parts relying only on shape context. Thanks to its low parameter size and computational requirements, it can be used to sort through a warehouse of potentially tens of thousand of spare parts in just a few seconds. We also establish an alternative baseline approach to compare against, and extensively document the unique challenges associated with this task, as well as identify the design choices to solve them.
Efficient and Scalable Point Cloud Generation with Sparse Point-Voxel Diffusion Models
Aug 12, 2024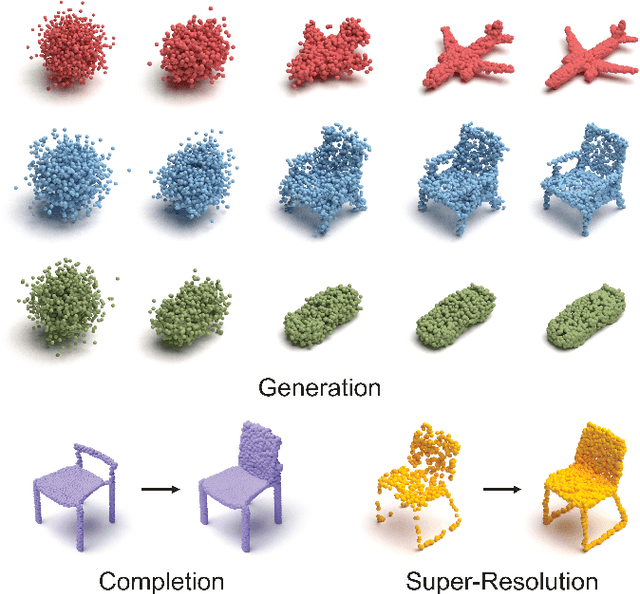
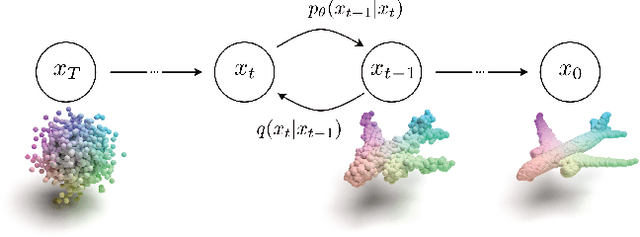
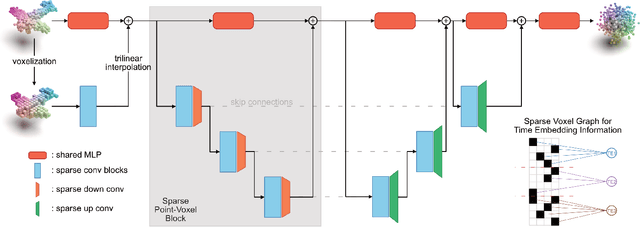
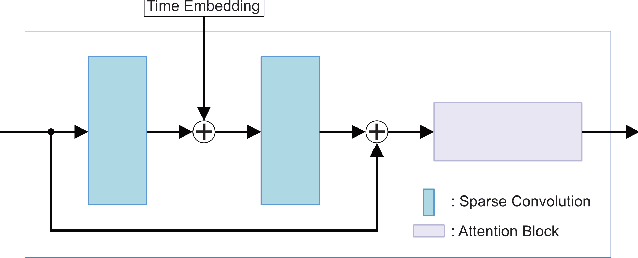
We propose a novel point cloud U-Net diffusion architecture for 3D generative modeling capable of generating high-quality and diverse 3D shapes while maintaining fast generation times. Our network employs a dual-branch architecture, combining the high-resolution representations of points with the computational efficiency of sparse voxels. Our fastest variant outperforms all non-diffusion generative approaches on unconditional shape generation, the most popular benchmark for evaluating point cloud generative models, while our largest model achieves state-of-the-art results among diffusion methods, with a runtime approximately 70% of the previously state-of-the-art PVD. Beyond unconditional generation, we perform extensive evaluations, including conditional generation on all categories of ShapeNet, demonstrating the scalability of our model to larger datasets, and implicit generation which allows our network to produce high quality point clouds on fewer timesteps, further decreasing the generation time. Finally, we evaluate the architecture's performance in point cloud completion and super-resolution. Our model excels in all tasks, establishing it as a state-of-the-art diffusion U-Net for point cloud generative modeling. The code is publicly available at https://github.com/JohnRomanelis/SPVD.git.
Aggressive saliency-aware point cloud compression
Jul 20, 2023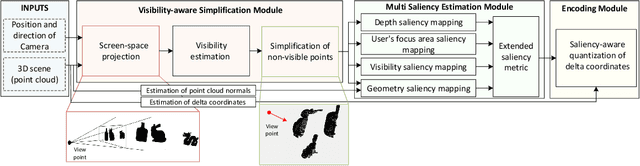
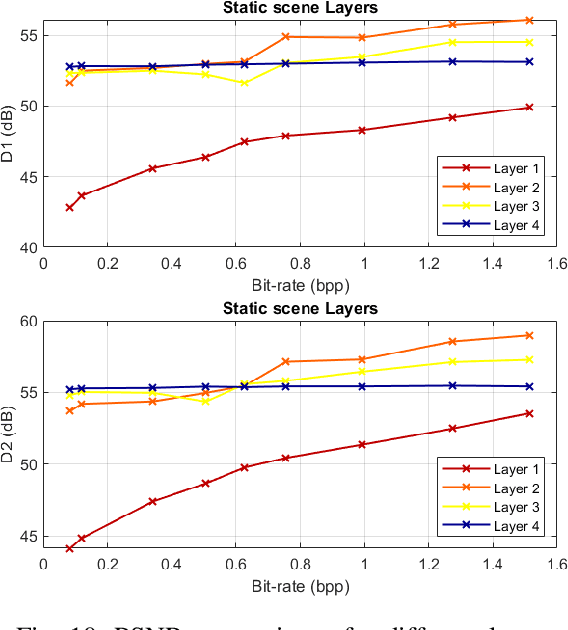
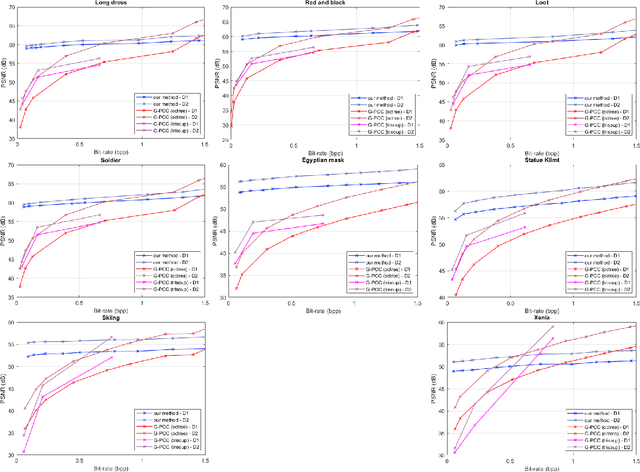

The increasing demand for accurate representations of 3D scenes, combined with immersive technologies has led point clouds to extensive popularity. However, quality point clouds require a large amount of data and therefore the need for compression methods is imperative. In this paper, we present a novel, geometry-based, end-to-end compression scheme, that combines information on the geometrical features of the point cloud and the user's position, achieving remarkable results for aggressive compression schemes demanding very small bit rates. After separating visible and non-visible points, four saliency maps are calculated, utilizing the point cloud's geometry and distance from the user, the visibility information, and the user's focus point. A combination of these maps results in a final saliency map, indicating the overall significance of each point and therefore quantizing different regions with a different number of bits during the encoding process. The decoder reconstructs the point cloud making use of delta coordinates and solving a sparse linear system. Evaluation studies and comparisons with the geometry-based point cloud compression (G-PCC) algorithm by the Moving Picture Experts Group (MPEG), carried out for a variety of point clouds, demonstrate that the proposed method achieves significantly better results for small bit rates.
ExpPoint-MAE: Better interpretability and performance for self-supervised point cloud transformers
Jun 23, 2023



In this paper we delve into the properties of transformers, attained through self-supervision, in the point cloud domain. Specifically, we evaluate the effectiveness of Masked Autoencoding as a pretraining scheme, and explore Momentum Contrast as an alternative. In our study we investigate the impact of data quantity on the learned features, and uncover similarities in the transformer's behavior across domains. Through comprehensive visualiations, we observe that the transformer learns to attend to semantically meaningful regions, indicating that pretraining leads to a better understanding of the underlying geometry. Moreover, we examine the finetuning process and its effect on the learned representations. Based on that, we devise an unfreezing strategy which consistently outperforms our baseline without introducing any other modifications to the model or the training pipeline, and achieve state-of-the-art results in the classification task among transformer models.
Real time enhancement of operator's ergonomics in physical human - robot collaboration scenarios using a multi-stereo camera system
Apr 11, 2023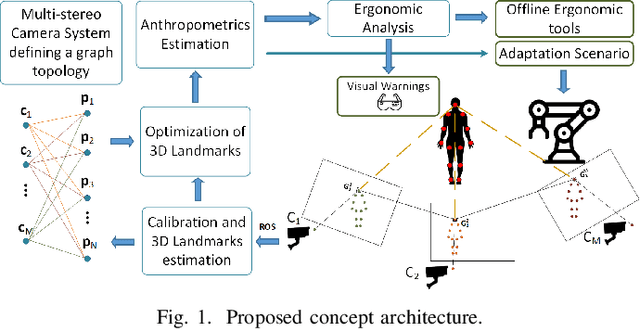
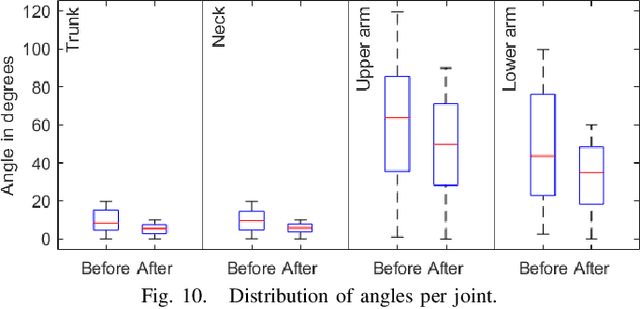

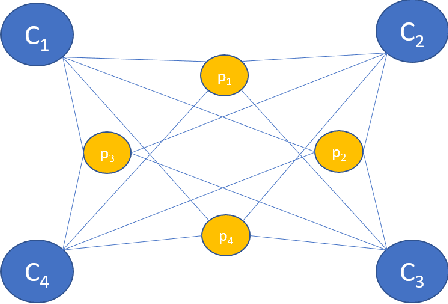
In collaborative tasks where humans work alongside machines, the robot's movements and behaviour can have a significant impact on the operator's safety, health, and comfort. To address this issue, we present a multi-stereo camera system that continuously monitors the operator's posture while they work with the robot. This system uses a novel distributed fusion approach to assess the operator's posture in real-time and to help avoid uncomfortable or unsafe positions. The system adjusts the robot's movements and informs the operator of any incorrect or potentially harmful postures, reducing the risk of accidents, strain, and musculoskeletal disorders. The analysis is personalized, taking into account the unique anthropometric characteristics of each operator, to ensure optimal ergonomics. The results of our experiments show that the proposed approach leads to improved human body postures and offers a promising solution for enhancing the ergonomics of operators in collaborative tasks.
Cooperative Saliency-based Obstacle Detection and AR Rendering for Increased Situational Awareness
Feb 02, 2023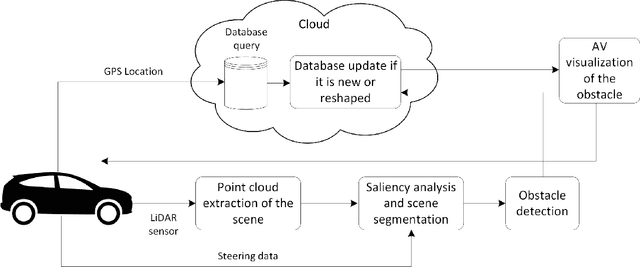

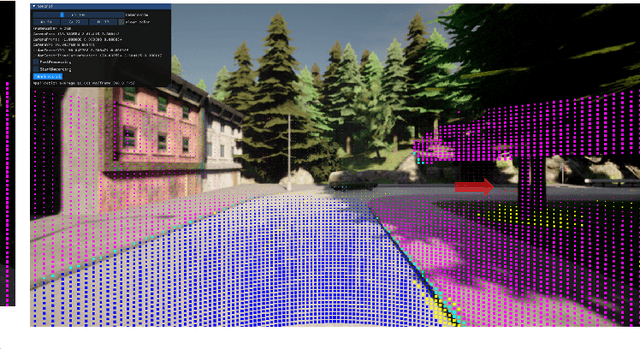

Autonomous vehicles are expected to operate safely in real-life road conditions in the next years. Nevertheless, unanticipated events such as the existence of unexpected objects in the range of the road, can put safety at risk. The advancement of sensing and communication technologies and Internet of Things may facilitate the recognition of hazardous situations and information exchange in a cooperative driving scheme, providing new opportunities for the increase of collaborative situational awareness. Safe and unobtrusive visualization of the obtained information may nowadays be enabled through the adoption of novel Augmented Reality (AR) interfaces in the form of windshields. Motivated by these technological opportunities, we propose in this work a saliency-based distributed, cooperative obstacle detection and rendering scheme for increasing the driver's situational awareness through (i) automated obstacle detection, (ii) AR visualization and (iii) information sharing (upcoming potential dangers) with other connected vehicles or road infrastructure. An extensive evaluation study using a variety of real datasets for pothole detection showed that the proposed method provides favorable results and features compared to other recent and relevant approaches.
Revisiting Audio Pattern Recognition for Asthma Medication Adherence: Evaluation with the RDA Benchmark Suite
Jun 01, 2022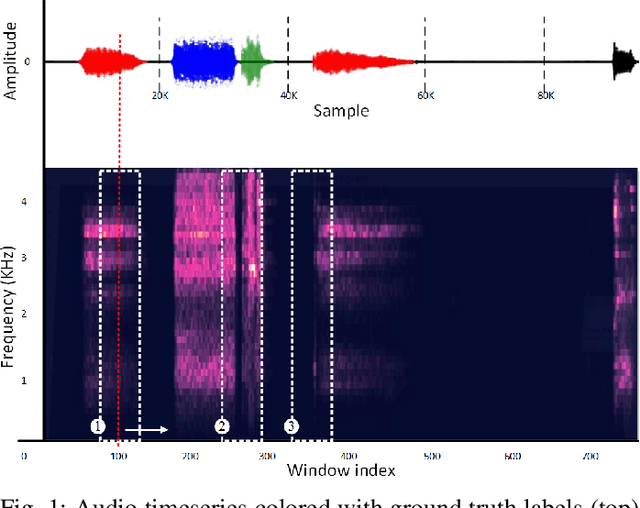
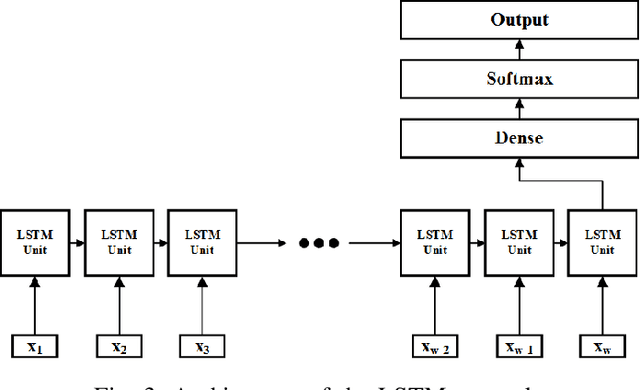
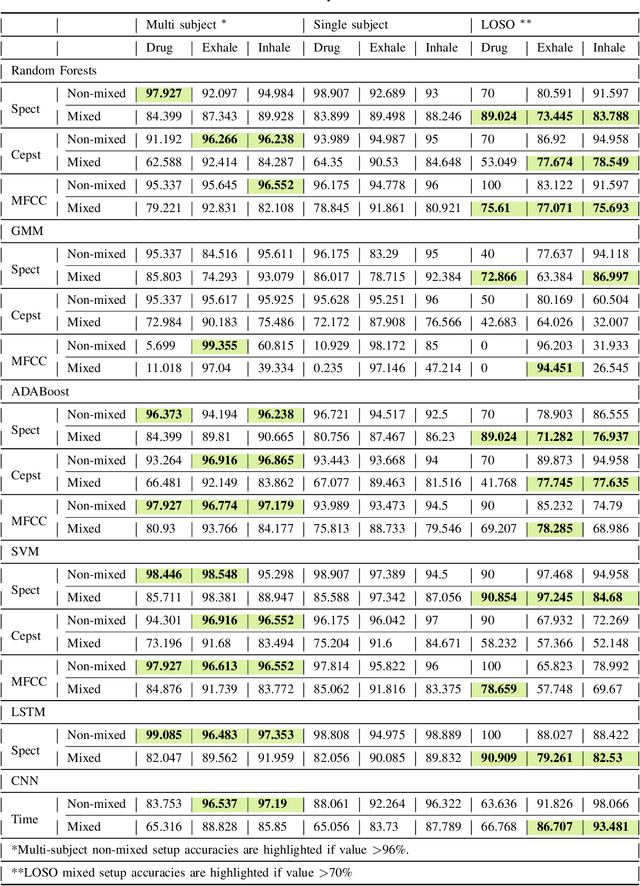
Asthma is a common, usually long-term respiratory disease with negative impact on society and the economy worldwide. Treatment involves using medical devices (inhalers) that distribute medication to the airways, and its efficiency depends on the precision of the inhalation technique. Health monitoring systems equipped with sensors and embedded with sound signal detection enable the recognition of drug actuation and could be powerful tools for reliable audio content analysis. This paper revisits audio pattern recognition and machine learning techniques for asthma medication adherence assessment and presents the Respiratory and Drug Actuation (RDA) Suite(https://gitlab.com/vvr/monitoring-medication-adherence/rda-benchmark) for benchmarking and further research. The RDA Suite includes a set of tools for audio processing, feature extraction and classification and is provided along with a dataset consisting of respiratory and drug actuation sounds. The classification models in RDA are implemented based on conventional and advanced machine learning and deep network architectures. This study provides a comparative evaluation of the implemented approaches, examines potential improvements and discusses challenges and future tendencies.