 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Calibrated Prediction of Randomly-Timed Biomarker Trajectories with Conformal Bands
Nov 17, 2025Despite recent progress in predicting biomarker trajectories from real clinical data, uncertainty in the predictions poses high-stakes risks (e.g., misdiagnosis) that limit their clinical deployment. To enable safe and reliable use of such predictions in healthcare, we introduce a conformal method for uncertainty-calibrated prediction of biomarker trajectories resulting from randomly-timed clinical visits of patients. Our approach extends conformal prediction to the setting of randomly-timed trajectories via a novel nonconformity score that produces prediction bands guaranteed to cover the unknown biomarker trajectories with a user-prescribed probability. We apply our method across a wide range of standard and state-of-the-art predictors for two well-established brain biomarkers of Alzheimer's disease, using neuroimaging data from real clinical studies. We observe that our conformal prediction bands consistently achieve the desired coverage, while also being tighter than baseline prediction bands. To further account for population heterogeneity, we develop group-conditional conformal bands and test their coverage guarantees across various demographic and clinically relevant subpopulations. Moreover, we demonstrate the clinical utility of our conformal bands in identifying subjects at high risk of progression to Alzheimer's disease. Specifically, we introduce an uncertainty-calibrated risk score that enables the identification of 17.5% more high-risk subjects compared to standard risk scores, highlighting the value of uncertainty calibration in real-world clinical decision making. Our code is available at github.com/vatass/ConformalBiomarkerTrajectories.
Comparative assessment of fairness definitions and bias mitigation strategies in machine learning-based diagnosis of Alzheimer's disease from MR images
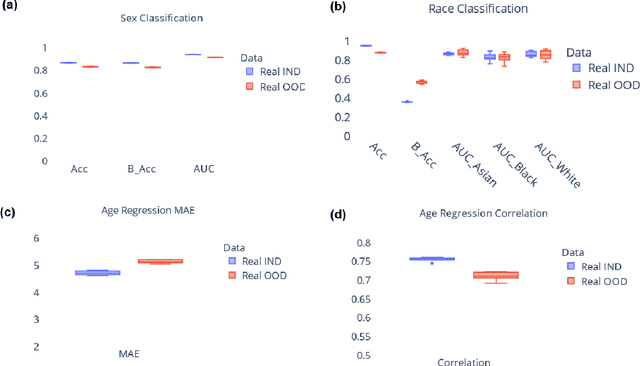
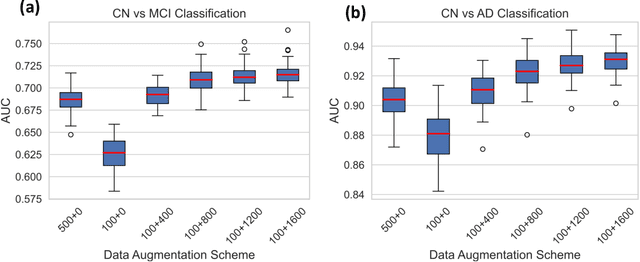
May 29, 2025The present study performs a comprehensive fairness analysis of machine learning (ML) models for the diagnosis of Mild Cognitive Impairment (MCI) and Alzheimer's disease (AD) from MRI-derived neuroimaging features. Biases associated with age, race, and gender in a multi-cohort dataset, as well as the influence of proxy features encoding these sensitive attributes, are investigated. The reliability of various fairness definitions and metrics in the identification of such biases is also assessed. Based on the most appropriate fairness measures, a comparative analysis of widely used pre-processing, in-processing, and post-processing bias mitigation strategies is performed. Moreover, a novel composite measure is introduced to quantify the trade-off between fairness and performance by considering the F1-score and the equalized odds ratio, making it appropriate for medical diagnostic applications. The obtained results reveal the existence of biases related to age and race, while no significant gender bias is observed. The deployed mitigation strategies yield varying improvements in terms of fairness across the different sensitive attributes and studied subproblems. For race and gender, Reject Option Classification improves equalized odds by 46% and 57%, respectively, and achieves harmonic mean scores of 0.75 and 0.80 in the MCI versus AD subproblem, whereas for age, in the same subproblem, adversarial debiasing yields the highest equalized odds improvement of 40% with a harmonic mean score of 0.69. Insights are provided into how variations in AD neuropathology and risk factors, associated with demographic characteristics, influence model fairness.
Adaptive Shrinkage Estimation For Personalized Deep Kernel Regression In Modeling Brain Trajectories
Apr 10, 2025



Longitudinal biomedical studies monitor individuals over time to capture dynamics in brain development, disease progression, and treatment effects. However, estimating trajectories of brain biomarkers is challenging due to biological variability, inconsistencies in measurement protocols (e.g., differences in MRI scanners), scarcity, and irregularity in longitudinal measurements. Herein, we introduce a novel personalized deep kernel regression framework for forecasting brain biomarkers, with application to regional volumetric measurements. Our approach integrates two key components: a population model that captures brain trajectories from a large and diverse cohort, and a subject-specific model that captures individual trajectories. To optimally combine these, we propose Adaptive Shrinkage Estimation, which effectively balances population and subject-specific models. We assess our model's performance through predictive accuracy metrics, uncertainty quantification, and validation against external clinical studies. Benchmarking against state-of-the-art statistical and machine learning models -- including linear mixed effects models, generalized additive models, and deep learning methods -- demonstrates the superior predictive performance of our approach. Additionally, we apply our method to predict trajectories of composite neuroimaging biomarkers, which highlights the versatility of our approach in modeling the progression of longitudinal neuroimaging biomarkers. Furthermore, validation on three external neuroimaging studies confirms the robustness of our method across different clinical contexts. We make the code available at https://github.com/vatass/AdaptiveShrinkageDKGP.
Pitfalls of defacing whole-head MRI: re-identification risk with diffusion models and compromised research potential
Jan 31, 2025Defacing is often applied to head magnetic resonance image (MRI) datasets prior to public release to address privacy concerns. The alteration of facial and nearby voxels has provoked discussions about the true capability of these techniques to ensure privacy as well as their impact on downstream tasks. With advancements in deep generative models, the extent to which defacing can protect privacy is uncertain. Additionally, while the altered voxels are known to contain valuable anatomical information, their potential to support research beyond the anatomical regions directly affected by defacing remains uncertain. To evaluate these considerations, we develop a refacing pipeline that recovers faces in defaced head MRIs using cascaded diffusion probabilistic models (DPMs). The DPMs are trained on images from 180 subjects and tested on images from 484 unseen subjects, 469 of whom are from a different dataset. To assess whether the altered voxels in defacing contain universally useful information, we also predict computed tomography (CT)-derived skeletal muscle radiodensity from facial voxels in both defaced and original MRIs. The results show that DPMs can generate high-fidelity faces that resemble the original faces from defaced images, with surface distances to the original faces significantly smaller than those of a population average face (p < 0.05). This performance also generalizes well to previously unseen datasets. For skeletal muscle radiodensity predictions, using defaced images results in significantly weaker Spearman's rank correlation coefficients compared to using original images (p < 10-4). For shin muscle, the correlation is statistically significant (p < 0.05) when using original images but not statistically significant (p > 0.05) when any defacing method is applied, suggesting that defacing might not only fail to protect privacy but also eliminate valuable information.
A comprehensive interpretable machine learning framework for Mild Cognitive Impairment and Alzheimer's disease diagnosis
Dec 12, 2024



An interpretable machine learning (ML) framework is introduced to enhance the diagnosis of Mild Cognitive Impairment (MCI) and Alzheimer's disease (AD) by ensuring robustness of the ML models' interpretations. The dataset used comprises volumetric measurements from brain MRI and genetic data from healthy individuals and patients with MCI/AD, obtained through the Alzheimer's Disease Neuroimaging Initiative. The existing class imbalance is addressed by an ensemble learning approach, while various attribution-based and counterfactual-based interpretability methods are leveraged towards producing diverse explanations related to the pathophysiology of MCI/AD. A unification method combining SHAP with counterfactual explanations assesses the interpretability techniques' robustness. The best performing model yielded 87.5% balanced accuracy and 90.8% F1-score. The attribution-based interpretability methods highlighted significant volumetric and genetic features related to MCI/AD risk. The unification method provided useful insights regarding those features' necessity and sufficiency, further showcasing their significance in MCI/AD diagnosis.
Brain age identification from diffusion MRI synergistically predicts neurodegenerative disease
Oct 29, 2024



Estimated brain age from magnetic resonance image (MRI) and its deviation from chronological age can provide early insights into potential neurodegenerative diseases, supporting early detection and implementation of prevention strategies. Diffusion MRI (dMRI), a widely used modality for brain age estimation, presents an opportunity to build an earlier biomarker for neurodegenerative disease prediction because it captures subtle microstructural changes that precede more perceptible macrostructural changes. However, the coexistence of macro- and micro-structural information in dMRI raises the question of whether current dMRI-based brain age estimation models are leveraging the intended microstructural information or if they inadvertently rely on the macrostructural information. To develop a microstructure-specific brain age, we propose a method for brain age identification from dMRI that minimizes the model's use of macrostructural information by non-rigidly registering all images to a standard template. Imaging data from 13,398 participants across 12 datasets were used for the training and evaluation. We compare our brain age models, trained with and without macrostructural information minimized, with an architecturally similar T1-weighted (T1w) MRI-based brain age model and two state-of-the-art T1w MRI-based brain age models that primarily use macrostructural information. We observe difference between our dMRI-based brain age and T1w MRI-based brain age across stages of neurodegeneration, with dMRI-based brain age being older than T1w MRI-based brain age in participants transitioning from cognitively normal (CN) to mild cognitive impairment (MCI), but younger in participants already diagnosed with Alzheimer's disease (AD). Approximately 4 years before MCI diagnosis, dMRI-based brain age yields better performance than T1w MRI-based brain ages in predicting transition from CN to MCI.
NeuroSynth: MRI-Derived Neuroanatomical Generative Models and Associated Dataset of 18,000 Samples
Jul 17, 2024
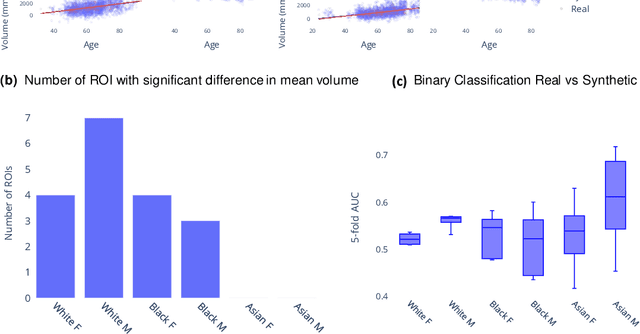
Availability of large and diverse medical datasets is often challenged by privacy and data sharing restrictions. For successful application of machine learning techniques for disease diagnosis, prognosis, and precision medicine, large amounts of data are necessary for model building and optimization. To help overcome such limitations in the context of brain MRI, we present NeuroSynth: a collection of generative models of normative regional volumetric features derived from structural brain imaging. NeuroSynth models are trained on real brain imaging regional volumetric measures from the iSTAGING consortium, which encompasses over 40,000 MRI scans across 13 studies, incorporating covariates such as age, sex, and race. Leveraging NeuroSynth, we produce and offer 18,000 synthetic samples spanning the adult lifespan (ages 22-90 years), alongside the model's capability to generate unlimited data. Experimental results indicate that samples generated from NeuroSynth agree with the distributions obtained from real data. Most importantly, the generated normative data significantly enhance the accuracy of downstream machine learning models on tasks such as disease classification. Data and models are available at: https://huggingface.co/spaces/rongguangw/neuro-synth.
BraTS-PEDs: Results of the Multi-Consortium International Pediatric Brain Tumor Segmentation Challenge 2023
Jul 11, 2024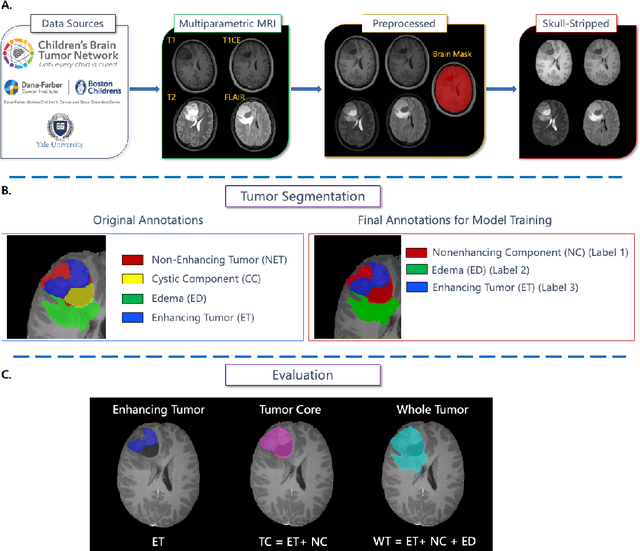

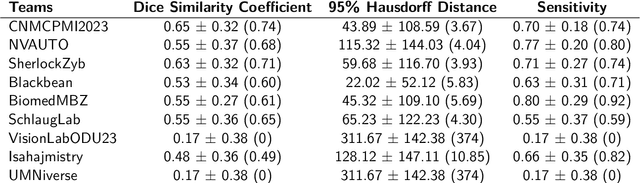
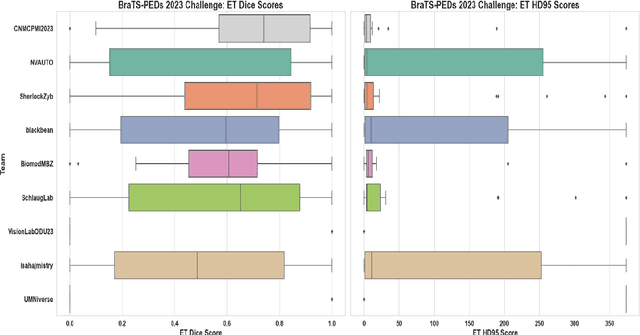
Pediatric central nervous system tumors are the leading cause of cancer-related deaths in children. The five-year survival rate for high-grade glioma in children is less than 20%. The development of new treatments is dependent upon multi-institutional collaborative clinical trials requiring reproducible and accurate centralized response assessment. We present the results of the BraTS-PEDs 2023 challenge, the first Brain Tumor Segmentation (BraTS) challenge focused on pediatric brain tumors. This challenge utilized data acquired from multiple international consortia dedicated to pediatric neuro-oncology and clinical trials. BraTS-PEDs 2023 aimed to evaluate volumetric segmentation algorithms for pediatric brain gliomas from magnetic resonance imaging using standardized quantitative performance evaluation metrics employed across the BraTS 2023 challenges. The top-performing AI approaches for pediatric tumor analysis included ensembles of nnU-Net and Swin UNETR, Auto3DSeg, or nnU-Net with a self-supervised framework. The BraTSPEDs 2023 challenge fostered collaboration between clinicians (neuro-oncologists, neuroradiologists) and AI/imaging scientists, promoting faster data sharing and the development of automated volumetric analysis techniques. These advancements could significantly benefit clinical trials and improve the care of children with brain tumors.
Analysis of the BraTS 2023 Intracranial Meningioma Segmentation Challenge
May 16, 2024



We describe the design and results from the BraTS 2023 Intracranial Meningioma Segmentation Challenge. The BraTS Meningioma Challenge differed from prior BraTS Glioma challenges in that it focused on meningiomas, which are typically benign extra-axial tumors with diverse radiologic and anatomical presentation and a propensity for multiplicity. Nine participating teams each developed deep-learning automated segmentation models using image data from the largest multi-institutional systematically expert annotated multilabel multi-sequence meningioma MRI dataset to date, which included 1000 training set cases, 141 validation set cases, and 283 hidden test set cases. Each case included T2, T2/FLAIR, T1, and T1Gd brain MRI sequences with associated tumor compartment labels delineating enhancing tumor, non-enhancing tumor, and surrounding non-enhancing T2/FLAIR hyperintensity. Participant automated segmentation models were evaluated and ranked based on a scoring system evaluating lesion-wise metrics including dice similarity coefficient (DSC) and 95% Hausdorff Distance. The top ranked team had a lesion-wise median dice similarity coefficient (DSC) of 0.976, 0.976, and 0.964 for enhancing tumor, tumor core, and whole tumor, respectively and a corresponding average DSC of 0.899, 0.904, and 0.871, respectively. These results serve as state-of-the-art benchmarks for future pre-operative meningioma automated segmentation algorithms. Additionally, we found that 1286 of 1424 cases (90.3%) had at least 1 compartment voxel abutting the edge of the skull-stripped image edge, which requires further investigation into optimal pre-processing face anonymization steps.
Dimensional Neuroimaging Endophenotypes: Neurobiological Representations of Disease Heterogeneity Through Machine Learning
Jan 17, 2024
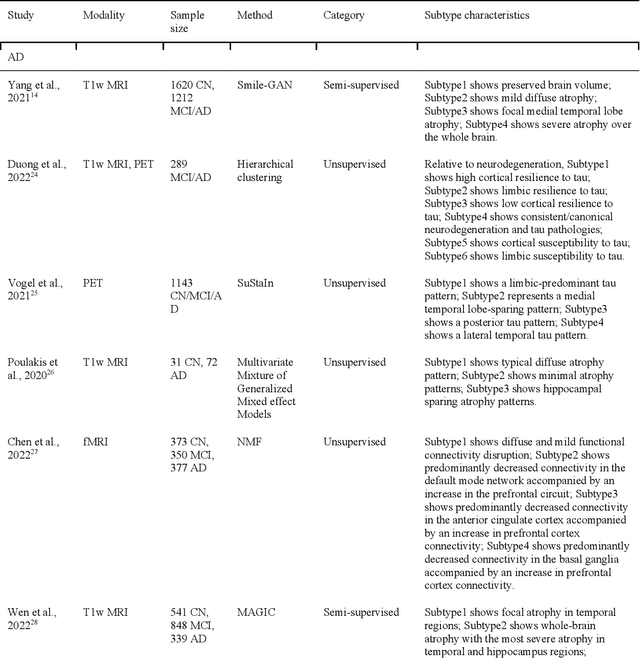
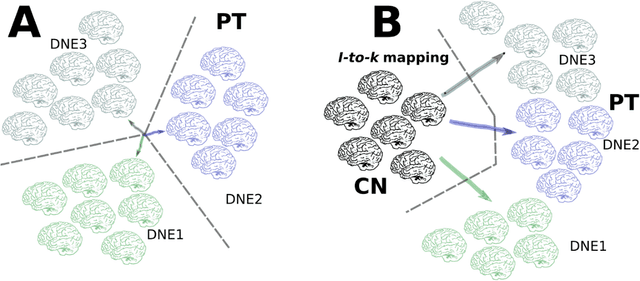
Machine learning has been increasingly used to obtain individualized neuroimaging signatures for disease diagnosis, prognosis, and response to treatment in neuropsychiatric and neurodegenerative disorders. Therefore, it has contributed to a better understanding of disease heterogeneity by identifying disease subtypes that present significant differences in various brain phenotypic measures. In this review, we first present a systematic literature overview of studies using machine learning and multimodal MRI to unravel disease heterogeneity in various neuropsychiatric and neurodegenerative disorders, including Alzheimer disease, schizophrenia, major depressive disorder, autism spectrum disorder, multiple sclerosis, as well as their potential in transdiagnostic settings. Subsequently, we summarize relevant machine learning methodologies and discuss an emerging paradigm which we call dimensional neuroimaging endophenotype (DNE). DNE dissects the neurobiological heterogeneity of neuropsychiatric and neurodegenerative disorders into a low dimensional yet informative, quantitative brain phenotypic representation, serving as a robust intermediate phenotype (i.e., endophenotype) largely reflecting underlying genetics and etiology. Finally, we discuss the potential clinical implications of the current findings and envision future research avenues.