 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGlobally Optimal Pose from Orthographic Silhouettes
Apr 10, 2026We solve the problem of determining the pose of known shapes in $\mathbb{R}^3$ from their unoccluded silhouettes. The pose is determined up to global optimality using a simple yet under-explored property of the area-of-silhouette: its continuity w.r.t trajectories in the rotation space. The proposed method utilises pre-computed silhouette-signatures, modelled as a response surface of the area-of-silhouettes. Querying this silhouette-signature response surface for pose estimation leads to a strong branching of the rotation search space, making resolution-guided candidate search feasible. Additionally, we utilise the aspect ratio of 2D ellipses fitted to projected silhouettes as an auxiliary global shape signature to accelerate the pose search. This combined strategy forms the first method to efficiently estimate globally optimal pose from just the silhouettes, without being guided by correspondences, for any shape, irrespective of its convexity and genus. We validate our method on synthetic and real examples, demonstrating significantly improved accuracy against comparable approaches. Code, data, and supplementary in: https://agnivsen.github.io/pose-from-silhouette/
Deep Medial Voxels: Learned Medial Axis Approximations for Anatomical Shape Modeling
Mar 18, 2024Shape reconstruction from imaging volumes is a recurring need in medical image analysis. Common workflows start with a segmentation step, followed by careful post-processing and,finally, ad hoc meshing algorithms. As this sequence can be timeconsuming, neural networks are trained to reconstruct shapes through template deformation. These networks deliver state-ofthe-art results without manual intervention, but, so far, they have primarily been evaluated on anatomical shapes with little topological variety between individuals. In contrast, other works favor learning implicit shape models, which have multiple benefits for meshing and visualization. Our work follows this direction by introducing deep medial voxels, a semi-implicit representation that faithfully approximates the topological skeleton from imaging volumes and eventually leads to shape reconstruction via convolution surfaces. Our reconstruction technique shows potential for both visualization and computer simulations.
How we won BraTS 2023 Adult Glioma challenge? Just faking it! Enhanced Synthetic Data Augmentation and Model Ensemble for brain tumour segmentation
Feb 27, 2024
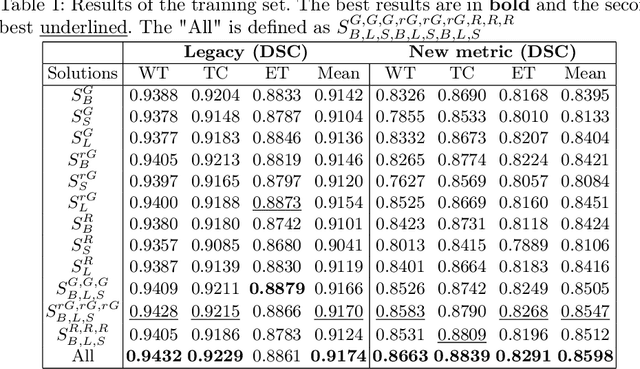


Deep Learning is the state-of-the-art technology for segmenting brain tumours. However, this requires a lot of high-quality data, which is difficult to obtain, especially in the medical field. Therefore, our solutions address this problem by using unconventional mechanisms for data augmentation. Generative adversarial networks and registration are used to massively increase the amount of available samples for training three different deep learning models for brain tumour segmentation, the first task of the BraTS2023 challenge. The first model is the standard nnU-Net, the second is the Swin UNETR and the third is the winning solution of the BraTS 2021 Challenge. The entire pipeline is built on the nnU-Net implementation, except for the generation of the synthetic data. The use of convolutional algorithms and transformers is able to fill each other's knowledge gaps. Using the new metric, our best solution achieves the dice results 0.9005, 0.8673, 0.8509 and HD95 14.940, 14.467, 17.699 (whole tumour, tumour core and enhancing tumour) in the validation set.
Cyto R-CNN and CytoNuke Dataset: Towards reliable whole-cell segmentation in bright-field histological images
Feb 04, 2024Background: Cell segmentation in bright-field histological slides is a crucial topic in medical image analysis. Having access to accurate segmentation allows researchers to examine the relationship between cellular morphology and clinical observations. Unfortunately, most segmentation methods known today are limited to nuclei and cannot segmentate the cytoplasm. Material & Methods: We present a new network architecture Cyto R-CNN that is able to accurately segment whole cells (with both the nucleus and the cytoplasm) in bright-field images. We also present a new dataset CytoNuke, consisting of multiple thousand manual annotations of head and neck squamous cell carcinoma cells. Utilizing this dataset, we compared the performance of Cyto R-CNN to other popular cell segmentation algorithms, including QuPath's built-in algorithm, StarDist and Cellpose. To evaluate segmentation performance, we calculated AP50, AP75 and measured 17 morphological and staining-related features for all detected cells. We compared these measurements to the gold standard of manual segmentation using the Kolmogorov-Smirnov test. Results: Cyto R-CNN achieved an AP50 of 58.65% and an AP75 of 11.56% in whole-cell segmentation, outperforming all other methods (QuPath $19.46/0.91\%$; StarDist $45.33/2.32\%$; Cellpose $31.85/5.61\%$). Cell features derived from Cyto R-CNN showed the best agreement to the gold standard ($\bar{D} = 0.15$) outperforming QuPath ($\bar{D} = 0.22$), StarDist ($\bar{D} = 0.25$) and Cellpose ($\bar{D} = 0.23$). Conclusion: Our newly proposed Cyto R-CNN architecture outperforms current algorithms in whole-cell segmentation while providing more reliable cell measurements than any other model. This could improve digital pathology workflows, potentially leading to improved diagnosis. Moreover, our published dataset can be used to develop further models in the future.
On the Impact of Cross-Domain Data on German Language Models
Oct 13, 2023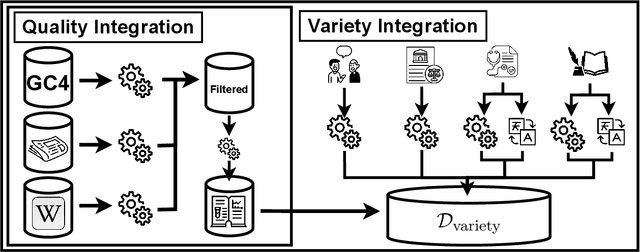



Traditionally, large language models have been either trained on general web crawls or domain-specific data. However, recent successes of generative large language models, have shed light on the benefits of cross-domain datasets. To examine the significance of prioritizing data diversity over quality, we present a German dataset comprising texts from five domains, along with another dataset aimed at containing high-quality data. Through training a series of models ranging between 122M and 750M parameters on both datasets, we conduct a comprehensive benchmark on multiple downstream tasks. Our findings demonstrate that the models trained on the cross-domain dataset outperform those trained on quality data alone, leading to improvements up to $4.45\%$ over the previous state-of-the-art. The models are available at https://huggingface.co/ikim-uk-essen
Multilingual Natural Language Processing Model for Radiology Reports -- The Summary is all you need!
Oct 06, 2023



The impression section of a radiology report summarizes important radiology findings and plays a critical role in communicating these findings to physicians. However, the preparation of these summaries is time-consuming and error-prone for radiologists. Recently, numerous models for radiology report summarization have been developed. Nevertheless, there is currently no model that can summarize these reports in multiple languages. Such a model could greatly improve future research and the development of Deep Learning models that incorporate data from patients with different ethnic backgrounds. In this study, the generation of radiology impressions in different languages was automated by fine-tuning a model, publicly available, based on a multilingual text-to-text Transformer to summarize findings available in English, Portuguese, and German radiology reports. In a blind test, two board-certified radiologists indicated that for at least 70% of the system-generated summaries, the quality matched or exceeded the corresponding human-written summaries, suggesting substantial clinical reliability. Furthermore, this study showed that the multilingual model outperformed other models that specialized in summarizing radiology reports in only one language, as well as models that were not specifically designed for summarizing radiology reports, such as ChatGPT.
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023



We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/
Anatomy Completor: A Multi-class Completion Framework for 3D Anatomy Reconstruction
Sep 10, 2023



In this paper, we introduce a completion framework to reconstruct the geometric shapes of various anatomies, including organs, vessels and muscles. Our work targets a scenario where one or multiple anatomies are missing in the imaging data due to surgical, pathological or traumatic factors, or simply because these anatomies are not covered by image acquisition. Automatic reconstruction of the missing anatomies benefits many applications, such as organ 3D bio-printing, whole-body segmentation, animation realism, paleoradiology and forensic imaging. We propose two paradigms based on a 3D denoising auto-encoder (DAE) to solve the anatomy reconstruction problem: (i) the DAE learns a many-to-one mapping between incomplete and complete instances; (ii) the DAE learns directly a one-to-one residual mapping between the incomplete instances and the target anatomies. We apply a loss aggregation scheme that enables the DAE to learn the many-to-one mapping more effectively and further enhances the learning of the residual mapping. On top of this, we extend the DAE to a multiclass completor by assigning a unique label to each anatomy involved. We evaluate our method using a CT dataset with whole-body segmentations. Results show that our method produces reasonable anatomy reconstructions given instances with different levels of incompleteness (i.e., one or multiple random anatomies are missing). Codes and pretrained models are publicly available at https://github.com/Jianningli/medshapenet-feedback/ tree/main/anatomy-completor
FAM: Relative Flatness Aware Minimization
Jul 05, 2023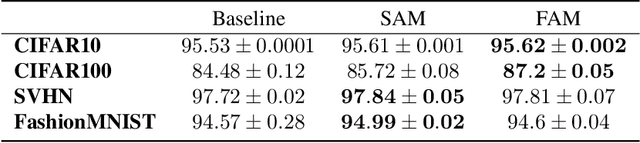
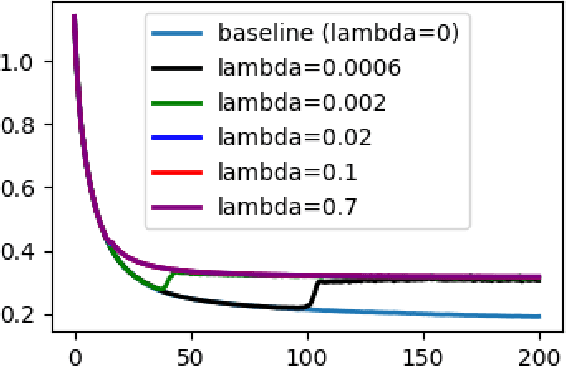

Flatness of the loss curve around a model at hand has been shown to empirically correlate with its generalization ability. Optimizing for flatness has been proposed as early as 1994 by Hochreiter and Schmidthuber, and was followed by more recent successful sharpness-aware optimization techniques. Their widespread adoption in practice, though, is dubious because of the lack of theoretically grounded connection between flatness and generalization, in particular in light of the reparameterization curse - certain reparameterizations of a neural network change most flatness measures but do not change generalization. Recent theoretical work suggests that a particular relative flatness measure can be connected to generalization and solves the reparameterization curse. In this paper, we derive a regularizer based on this relative flatness that is easy to compute, fast, efficient, and works with arbitrary loss functions. It requires computing the Hessian only of a single layer of the network, which makes it applicable to large neural networks, and with it avoids an expensive mapping of the loss surface in the vicinity of the model. In an extensive empirical evaluation we show that this relative flatness aware minimization (FAM) improves generalization in a multitude of applications and models, both in finetuning and standard training. We make the code available at github.
Why is the winner the best?
Mar 30, 2023



International benchmarking competitions have become fundamental for the comparative performance assessment of image analysis methods. However, little attention has been given to investigating what can be learnt from these competitions. Do they really generate scientific progress? What are common and successful participation strategies? What makes a solution superior to a competing method? To address this gap in the literature, we performed a multi-center study with all 80 competitions that were conducted in the scope of IEEE ISBI 2021 and MICCAI 2021. Statistical analyses performed based on comprehensive descriptions of the submitted algorithms linked to their rank as well as the underlying participation strategies revealed common characteristics of winning solutions. These typically include the use of multi-task learning (63%) and/or multi-stage pipelines (61%), and a focus on augmentation (100%), image preprocessing (97%), data curation (79%), and postprocessing (66%). The "typical" lead of a winning team is a computer scientist with a doctoral degree, five years of experience in biomedical image analysis, and four years of experience in deep learning. Two core general development strategies stood out for highly-ranked teams: the reflection of the metrics in the method design and the focus on analyzing and handling failure cases. According to the organizers, 43% of the winning algorithms exceeded the state of the art but only 11% completely solved the respective domain problem. The insights of our study could help researchers (1) improve algorithm development strategies when approaching new problems, and (2) focus on open research questions revealed by this work.