 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLess Finetuning, Better Retrieval: Rethinking LLM Adaptation for Biomedical Retrievers via Synthetic Data and Model Merging
Feb 04, 2026Retrieval-augmented generation (RAG) has become the backbone of grounding Large Language Models (LLMs), improving knowledge updates and reducing hallucinations. Recently, LLM-based retriever models have shown state-of-the-art performance for RAG applications. However, several technical aspects remain underexplored on how to adapt general-purpose LLMs into effective domain-specific retrievers, especially in specialized domains such as biomedicine. We present Synthesize-Train-Merge (STM), a modular framework that enhances decoder-only LLMs with synthetic hard negatives, retrieval prompt optimization, and model merging. Experiments on a subset of 12 medical and general tasks from the MTEB benchmark show STM boosts task-specific experts by up to 23.5\% (average 7.5\%) and produces merged models that outperform both single experts and strong baselines without extensive pretraining. Our results demonstrate a scalable, efficient path for turning general LLMs into high-performing, domain-specialized retrievers, preserving general-domain capabilities while excelling on specialized tasks.
Automatic Fine-grained Segmentation-assisted Report Generation
Jul 22, 2025Reliable end-to-end clinical report generation has been a longstanding goal of medical ML research. The end goal for this process is to alleviate radiologists' workloads and provide second opinions to clinicians or patients. Thus, a necessary prerequisite for report generation models is a strong general performance and some type of innate grounding capability, to convince clinicians or patients of the veracity of the generated reports. In this paper, we present ASaRG (\textbf{A}utomatic \textbf{S}egmentation-\textbf{a}ssisted \textbf{R}eport \textbf{G}eneration), an extension of the popular LLaVA architecture that aims to tackle both of these problems. ASaRG proposes to fuse intermediate features and fine-grained segmentation maps created by specialist radiological models into LLaVA's multi-modal projection layer via simple concatenation. With a small number of added parameters, our approach achieves a +0.89\% performance gain ($p=0.012$) in CE F1 score compared to the LLaVA baseline when using only intermediate features, and +2.77\% performance gain ($p<0.001$) when adding a combination of intermediate features and fine-grained segmentation maps. Compared with COMG and ORID, two other report generation methods that utilize segmentations, the performance gain amounts to 6.98\% and 6.28\% in F1 score, respectively. ASaRG is not mutually exclusive with other changes made to the LLaVA architecture, potentially allowing our method to be combined with other advances in the field. Finally, the use of an arbitrary number of segmentations as part of the input demonstrably allows tracing elements of the report to the corresponding segmentation maps and verifying the groundedness of assessments. Our code will be made publicly available at a later date.
A Modular Approach for Clinical SLMs Driven by Synthetic Data with Pre-Instruction Tuning, Model Merging, and Clinical-Tasks Alignment
May 15, 2025High computation costs and latency of large language models such as GPT-4 have limited their deployment in clinical settings. Small language models (SLMs) offer a cost-effective alternative, but their limited capacity requires biomedical domain adaptation, which remains challenging. An additional bottleneck is the unavailability and high sensitivity of clinical data. To address these challenges, we propose a novel framework for adapting SLMs into high-performing clinical models. We introduce the MediPhi collection of 3.8B-parameter SLMs developed with our novel framework: pre-instruction tuning of experts on relevant medical and clinical corpora (PMC, Medical Guideline, MedWiki, etc.), model merging, and clinical-tasks alignment. To cover most clinical tasks, we extended the CLUE benchmark to CLUE+, doubling its size. Our expert models deliver relative improvements on this benchmark over the base model without any task-specific fine-tuning: 64.3% on medical entities, 49.5% on radiology reports, and 44% on ICD-10 coding (outperforming GPT-4-0125 by 14%). We unify the expert models into MediPhi via model merging, preserving gains across benchmarks. Furthermore, we built the MediFlow collection, a synthetic dataset of 2.5 million high-quality instructions on 14 medical NLP tasks, 98 fine-grained document types, and JSON format support. Alignment of MediPhi using supervised fine-tuning and direct preference optimization achieves further gains of 18.9% on average.
Towards Conditioning Clinical Text Generation for User Control
Feb 24, 2025Deploying natural language generation systems in clinical settings remains challenging despite advances in Large Language Models (LLMs), which continue to exhibit hallucinations and factual inconsistencies, necessitating human oversight. This paper explores automated dataset augmentation using LLMs as human proxies to condition LLMs for clinician control without increasing cognitive workload. On the BioNLP ACL'24 Discharge Me! Shared Task, we achieve new state-of-the-art results with simpler methods than prior submissions through more efficient training, yielding a 9\% relative improvement without augmented training and up to 34\% with dataset augmentation. Preliminary human evaluation further supports the effectiveness of our approach, highlighting the potential of augmenting clinical text generation for control to enhance relevance, accuracy, and factual consistency.
MeDiSumQA: Patient-Oriented Question-Answer Generation from Discharge Letters
Feb 05, 2025While increasing patients' access to medical documents improves medical care, this benefit is limited by varying health literacy levels and complex medical terminology. Large language models (LLMs) offer solutions by simplifying medical information. However, evaluating LLMs for safe and patient-friendly text generation is difficult due to the lack of standardized evaluation resources. To fill this gap, we developed MeDiSumQA. MeDiSumQA is a dataset created from MIMIC-IV discharge summaries through an automated pipeline combining LLM-based question-answer generation with manual quality checks. We use this dataset to evaluate various LLMs on patient-oriented question-answering. Our findings reveal that general-purpose LLMs frequently surpass biomedical-adapted models, while automated metrics correlate with human judgment. By releasing MeDiSumQA on PhysioNet, we aim to advance the development of LLMs to enhance patient understanding and ultimately improve care outcomes.
Biomedical Large Languages Models Seem not to be Superior to Generalist Models on Unseen Medical Data
Aug 25, 2024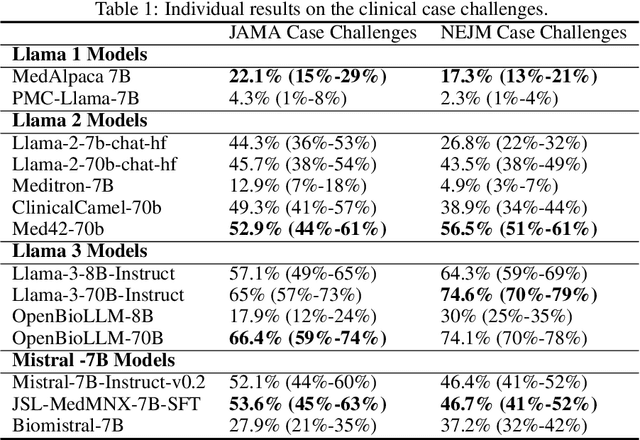
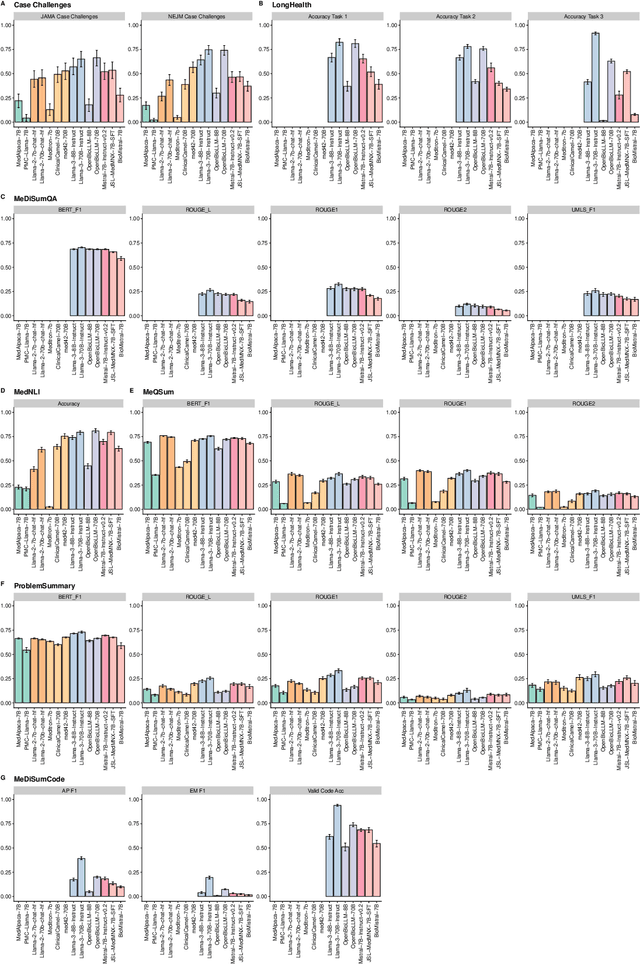
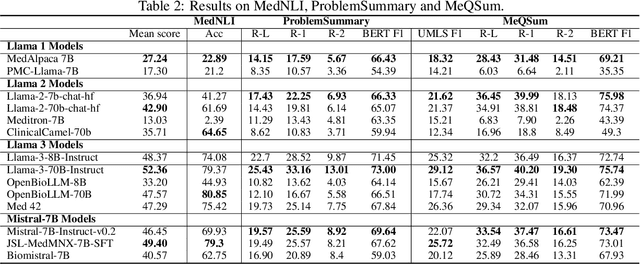
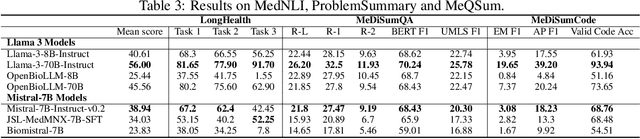
Large language models (LLMs) have shown potential in biomedical applications, leading to efforts to fine-tune them on domain-specific data. However, the effectiveness of this approach remains unclear. This study evaluates the performance of biomedically fine-tuned LLMs against their general-purpose counterparts on a variety of clinical tasks. We evaluated their performance on clinical case challenges from the New England Journal of Medicine (NEJM) and the Journal of the American Medical Association (JAMA) and on several clinical tasks (e.g., information extraction, document summarization, and clinical coding). Using benchmarks specifically chosen to be likely outside the fine-tuning datasets of biomedical models, we found that biomedical LLMs mostly perform inferior to their general-purpose counterparts, especially on tasks not focused on medical knowledge. While larger models showed similar performance on case tasks (e.g., OpenBioLLM-70B: 66.4% vs. Llama-3-70B-Instruct: 65% on JAMA cases), smaller biomedical models showed more pronounced underperformance (e.g., OpenBioLLM-8B: 30% vs. Llama-3-8B-Instruct: 64.3% on NEJM cases). Similar trends were observed across the CLUE (Clinical Language Understanding Evaluation) benchmark tasks, with general-purpose models often performing better on text generation, question answering, and coding tasks. Our results suggest that fine-tuning LLMs to biomedical data may not provide the expected benefits and may potentially lead to reduced performance, challenging prevailing assumptions about domain-specific adaptation of LLMs and highlighting the need for more rigorous evaluation frameworks in healthcare AI. Alternative approaches, such as retrieval-augmented generation, may be more effective in enhancing the biomedical capabilities of LLMs without compromising their general knowledge.
CLUE: A Clinical Language Understanding Evaluation for LLMs
Apr 11, 2024Large Language Models (LLMs) have shown the potential to significantly contribute to patient care, diagnostics, and administrative processes. Emerging biomedical LLMs address healthcare-specific challenges, including privacy demands and computational constraints. However, evaluation of these models has primarily been limited to non-clinical tasks, which do not reflect the complexity of practical clinical applications. Additionally, there has been no thorough comparison between biomedical and general-domain LLMs for clinical tasks. To fill this gap, we present the Clinical Language Understanding Evaluation (CLUE), a benchmark tailored to evaluate LLMs on real-world clinical tasks. CLUE includes two novel datasets derived from MIMIC IV discharge letters and four existing tasks designed to test the practical applicability of LLMs in healthcare settings. Our evaluation covers several biomedical and general domain LLMs, providing insights into their clinical performance and applicability. CLUE represents a step towards a standardized approach to evaluating and developing LLMs in healthcare to align future model development with the real-world needs of clinical application. We publish our evaluation and data generation scripts: https://github.com/TIO-IKIM/CLUE.
Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
Apr 08, 2024



Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
On the Impact of Cross-Domain Data on German Language Models
Oct 13, 2023Traditionally, large language models have been either trained on general web crawls or domain-specific data. However, recent successes of generative large language models, have shed light on the benefits of cross-domain datasets. To examine the significance of prioritizing data diversity over quality, we present a German dataset comprising texts from five domains, along with another dataset aimed at containing high-quality data. Through training a series of models ranging between 122M and 750M parameters on both datasets, we conduct a comprehensive benchmark on multiple downstream tasks. Our findings demonstrate that the models trained on the cross-domain dataset outperform those trained on quality data alone, leading to improvements up to $4.45\%$ over the previous state-of-the-art. The models are available at https://huggingface.co/ikim-uk-essen
MedShapeNet -- A Large-Scale Dataset of 3D Medical Shapes for Computer Vision
Sep 12, 2023



We present MedShapeNet, a large collection of anatomical shapes (e.g., bones, organs, vessels) and 3D surgical instrument models. Prior to the deep learning era, the broad application of statistical shape models (SSMs) in medical image analysis is evidence that shapes have been commonly used to describe medical data. Nowadays, however, state-of-the-art (SOTA) deep learning algorithms in medical imaging are predominantly voxel-based. In computer vision, on the contrary, shapes (including, voxel occupancy grids, meshes, point clouds and implicit surface models) are preferred data representations in 3D, as seen from the numerous shape-related publications in premier vision conferences, such as the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), as well as the increasing popularity of ShapeNet (about 51,300 models) and Princeton ModelNet (127,915 models) in computer vision research. MedShapeNet is created as an alternative to these commonly used shape benchmarks to facilitate the translation of data-driven vision algorithms to medical applications, and it extends the opportunities to adapt SOTA vision algorithms to solve critical medical problems. Besides, the majority of the medical shapes in MedShapeNet are modeled directly on the imaging data of real patients, and therefore it complements well existing shape benchmarks comprising of computer-aided design (CAD) models. MedShapeNet currently includes more than 100,000 medical shapes, and provides annotations in the form of paired data. It is therefore also a freely available repository of 3D models for extended reality (virtual reality - VR, augmented reality - AR, mixed reality - MR) and medical 3D printing. This white paper describes in detail the motivations behind MedShapeNet, the shape acquisition procedures, the use cases, as well as the usage of the online shape search portal: https://medshapenet.ikim.nrw/