 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavioral Analysis of Information Salience in Large Language Models
Feb 20, 2025



Large Language Models (LLMs) excel at text summarization, a task that requires models to select content based on its importance. However, the exact notion of salience that LLMs have internalized remains unclear. To bridge this gap, we introduce an explainable framework to systematically derive and investigate information salience in LLMs through their summarization behavior. Using length-controlled summarization as a behavioral probe into the content selection process, and tracing the answerability of Questions Under Discussion throughout, we derive a proxy for how models prioritize information. Our experiments on 13 models across four datasets reveal that LLMs have a nuanced, hierarchical notion of salience, generally consistent across model families and sizes. While models show highly consistent behavior and hence salience patterns, this notion of salience cannot be accessed through introspection, and only weakly correlates with human perceptions of information salience.
Comprehensive Study on German Language Models for Clinical and Biomedical Text Understanding
Apr 08, 2024



Recent advances in natural language processing (NLP) can be largely attributed to the advent of pre-trained language models such as BERT and RoBERTa. While these models demonstrate remarkable performance on general datasets, they can struggle in specialized domains such as medicine, where unique domain-specific terminologies, domain-specific abbreviations, and varying document structures are common. This paper explores strategies for adapting these models to domain-specific requirements, primarily through continuous pre-training on domain-specific data. We pre-trained several German medical language models on 2.4B tokens derived from translated public English medical data and 3B tokens of German clinical data. The resulting models were evaluated on various German downstream tasks, including named entity recognition (NER), multi-label classification, and extractive question answering. Our results suggest that models augmented by clinical and translation-based pre-training typically outperform general domain models in medical contexts. We conclude that continuous pre-training has demonstrated the ability to match or even exceed the performance of clinical models trained from scratch. Furthermore, pre-training on clinical data or leveraging translated texts have proven to be reliable methods for domain adaptation in medical NLP tasks.
FactPICO: Factuality Evaluation for Plain Language Summarization of Medical Evidence
Feb 18, 2024Plain language summarization with LLMs can be useful for improving textual accessibility of technical content. But how factual are these summaries in a high-stakes domain like medicine? This paper presents FactPICO, a factuality benchmark for plain language summarization of medical texts describing randomized controlled trials (RCTs), which are the basis of evidence-based medicine and can directly inform patient treatment. FactPICO consists of 345 plain language summaries of RCT abstracts generated from three LLMs (i.e., GPT-4, Llama-2, and Alpaca), with fine-grained evaluation and natural language rationales from experts. We assess the factuality of critical elements of RCTs in those summaries: Populations, Interventions, Comparators, Outcomes (PICO), as well as the reported findings concerning these. We also evaluate the correctness of the extra information (e.g., explanations) added by LLMs. Using FactPICO, we benchmark a range of existing factuality metrics, including the newly devised ones based on LLMs. We find that plain language summarization of medical evidence is still challenging, especially when balancing between simplicity and factuality, and that existing metrics correlate poorly with expert judgments on the instance level.
InfoLossQA: Characterizing and Recovering Information Loss in Text Simplification
Jan 29, 2024



Text simplification aims to make technical texts more accessible to laypeople but often results in deletion of information and vagueness. This work proposes InfoLossQA, a framework to characterize and recover simplification-induced information loss in form of question-and-answer (QA) pairs. Building on the theory of Question Under Discussion, the QA pairs are designed to help readers deepen their knowledge of a text. We conduct a range of experiments with this framework. First, we collect a dataset of 1,000 linguist-curated QA pairs derived from 104 LLM simplifications of scientific abstracts of medical studies. Our analyses of this data reveal that information loss occurs frequently, and that the QA pairs give a high-level overview of what information was lost. Second, we devise two methods for this task: end-to-end prompting of open-source and commercial language models, and a natural language inference pipeline. With a novel evaluation framework considering the correctness of QA pairs and their linguistic suitability, our expert evaluation reveals that models struggle to reliably identify information loss and applying similar standards as humans at what constitutes information loss.
Guidance in Radiology Report Summarization: An Empirical Evaluation and Error Analysis
Jul 24, 2023



Automatically summarizing radiology reports into a concise impression can reduce the manual burden of clinicians and improve the consistency of reporting. Previous work aimed to enhance content selection and factuality through guided abstractive summarization. However, two key issues persist. First, current methods heavily rely on domain-specific resources to extract the guidance signal, limiting their transferability to domains and languages where those resources are unavailable. Second, while automatic metrics like ROUGE show progress, we lack a good understanding of the errors and failure modes in this task. To bridge these gaps, we first propose a domain-agnostic guidance signal in form of variable-length extractive summaries. Our empirical results on two English benchmarks demonstrate that this guidance signal improves upon unguided summarization while being competitive with domain-specific methods. Additionally, we run an expert evaluation of four systems according to a taxonomy of 11 fine-grained errors. We find that the most pressing differences between automatic summaries and those of radiologists relate to content selection including omissions (up to 52%) and additions (up to 57%). We hypothesize that latent reporting factors and corpus-level inconsistencies may limit models to reliably learn content selection from the available data, presenting promising directions for future work.
From Anecdotal Evidence to Quantitative Evaluation Methods: A Systematic Review on Evaluating Explainable AI
Jan 20, 2022
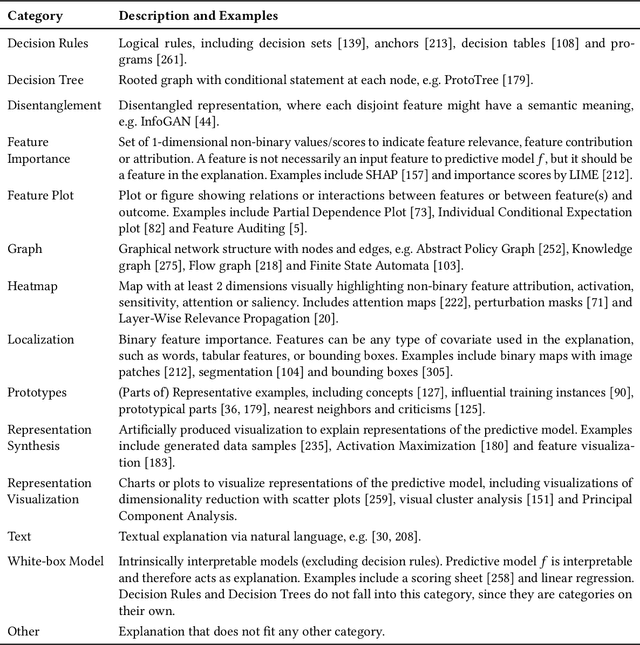

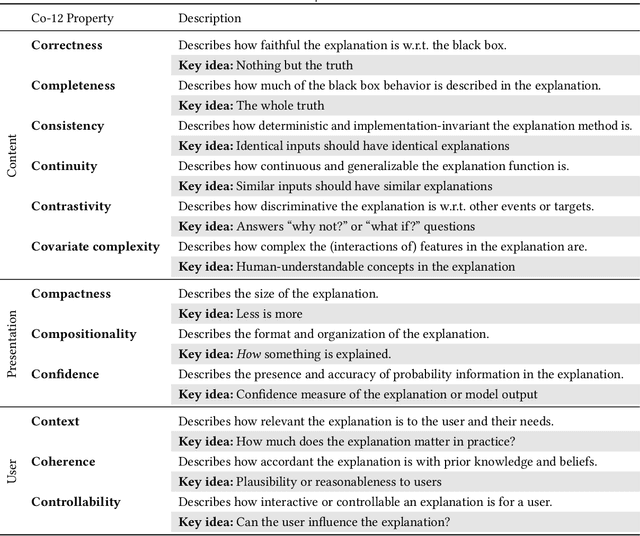
The rising popularity of explainable artificial intelligence (XAI) to understand high-performing black boxes, also raised the question of how to evaluate explanations of machine learning (ML) models. While interpretability and explainability are often presented as a subjectively validated binary property, we consider it a multi-faceted concept. We identify 12 conceptual properties, such as Compactness and Correctness, that should be evaluated for comprehensively assessing the quality of an explanation. Our so-called Co-12 properties serve as categorization scheme for systematically reviewing the evaluation practice of more than 300 papers published in the last 7 years at major AI and ML conferences that introduce an XAI method. We find that 1 in 3 papers evaluate exclusively with anecdotal evidence, and 1 in 5 papers evaluate with users. We also contribute to the call for objective, quantifiable evaluation methods by presenting an extensive overview of quantitative XAI evaluation methods. This systematic collection of evaluation methods provides researchers and practitioners with concrete tools to thoroughly validate, benchmark and compare new and existing XAI methods. This also opens up opportunities to include quantitative metrics as optimization criteria during model training in order to optimize for accuracy and interpretability simultaneously.
Comparing Rule-based, Feature-based and Deep Neural Methods for De-identification of Dutch Medical Records
Jan 16, 2020
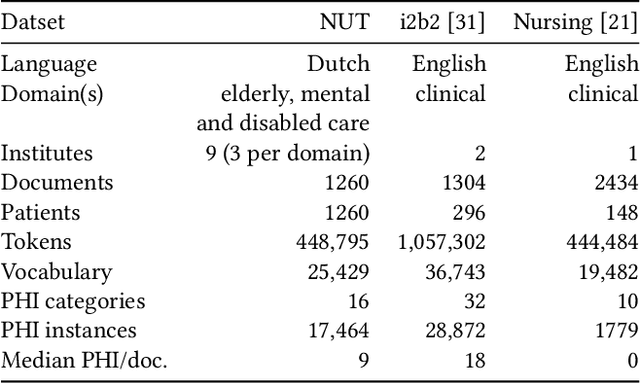
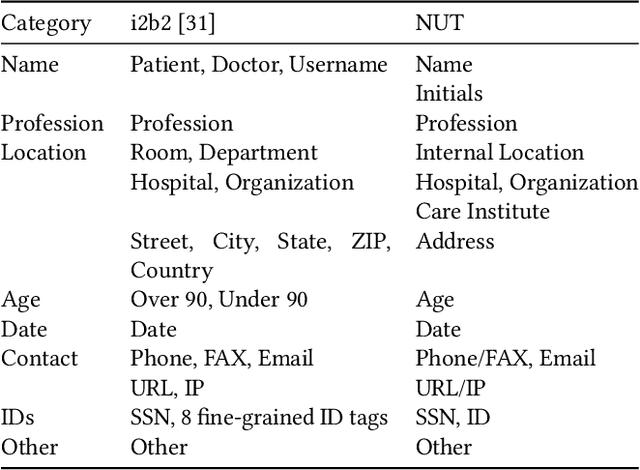
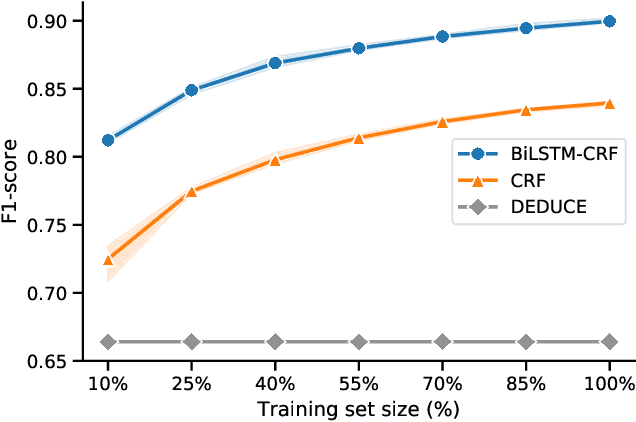
Unstructured information in electronic health records provide an invaluable resource for medical research. To protect the confidentiality of patients and to conform to privacy regulations, de-identification methods automatically remove personally identifying information from these medical records. However, due to the unavailability of labeled data, most existing research is constrained to English medical text and little is known about the generalizability of de-identification methods across languages and domains. In this study, we construct a varied dataset consisting of the medical records of 1260 patients by sampling data from 9 institutes and three domains of Dutch healthcare. We test the generalizability of three de-identification methods across languages and domains. Our experiments show that an existing rule-based method specifically developed for the Dutch language fails to generalize to this new data. Furthermore, a state-of-the-art neural architecture performs strongly across languages and domains, even with limited training data. Compared to feature-based and rule-based methods the neural method requires significantly less configuration effort and domain-knowledge. We make all code and pre-trained de-identification models available to the research community, allowing practitioners to apply them to their datasets and to enable future benchmarks.
Identifying Unclear Questions in Community Question Answering Websites
Jan 18, 2019


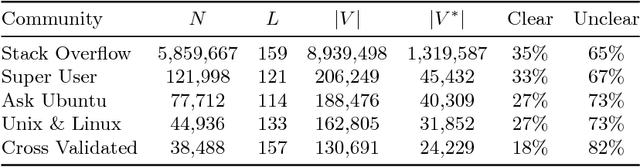
Thousands of complex natural language questions are submitted to community question answering websites on a daily basis, rendering them as one of the most important information sources these days. However, oftentimes submitted questions are unclear and cannot be answered without further clarification questions by expert community members. This study is the first to investigate the complex task of classifying a question as clear or unclear, i.e., if it requires further clarification. We construct a novel dataset and propose a classification approach that is based on the notion of similar questions. This approach is compared to state-of-the-art text classification baselines. Our main finding is that the similar questions approach is a viable alternative that can be used as a stepping stone towards the development of supportive user interfaces for question formulation.