 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUn-Attributability: Computing Novelty From Retrieval & Semantic Similarity
Oct 31, 2025Understanding how language-model outputs relate to the pretraining corpus is central to studying model behavior. Most training data attribution (TDA) methods ask which training examples causally influence a given output, often using leave-one-out tests. We invert the question: which outputs cannot be attributed to any pretraining example? We introduce un-attributability as an operational measure of semantic novelty: an output is novel if the pretraining corpus contains no semantically similar context. We approximate this with a simple two-stage retrieval pipeline: index the corpus with lightweight GIST embeddings, retrieve the top-n candidates, then rerank with ColBERTv2. If the nearest corpus item is less attributable than a human-generated text reference, we consider the output of the model as novel. We evaluate on SmolLM and SmolLM2 and report three findings: (1) models draw on pretraining data across much longer spans than previously reported; (2) some domains systematically promote or suppress novelty; and (3) instruction tuning not only alters style but also increases novelty. Reframing novelty assessment around un-attributability enables efficient analysis at pretraining scale. We release ~20 TB of corpus chunks and index artifacts to support replication and large-scale extension of our analysis at https://huggingface.co/datasets/stai-tuebingen/faiss-smollm
Social Science Is Necessary for Operationalizing Socially Responsible Foundation Models
Dec 20, 2024With the rise of foundation models, there is growing concern about their potential social impacts. Social science has a long history of studying the social impacts of transformative technologies in terms of pre-existing systems of power and how these systems are disrupted or reinforced by new technologies. In this position paper, we build on prior work studying the social impacts of earlier technologies to propose a conceptual framework studying foundation models as sociotechnical systems, incorporating social science expertise to better understand how these models affect systems of power, anticipate the impacts of deploying these models in various applications, and study the effectiveness of technical interventions intended to mitigate social harms. We advocate for an interdisciplinary and collaborative research paradigm between AI and social science across all stages of foundation model research and development to promote socially responsible research practices and use cases, and outline several strategies to facilitate such research.
Towards User-Focused Research in Training Data Attribution for Human-Centered Explainable AI
Sep 25, 2024
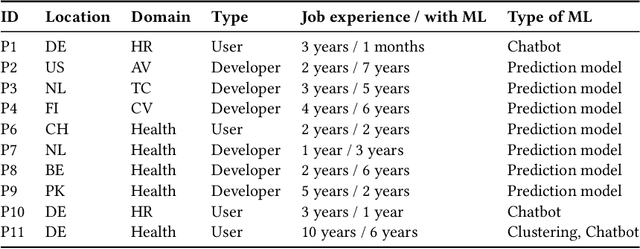
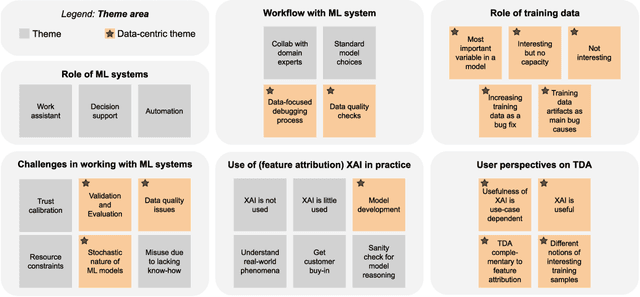
While Explainable AI (XAI) aims to make AI understandable and useful to humans, it has been criticised for relying too much on formalism and solutionism, focusing more on mathematical soundness than user needs. We propose an alternative to this bottom-up approach inspired by design thinking: the XAI research community should adopt a top-down, user-focused perspective to ensure user relevance. We illustrate this with a relatively young subfield of XAI, Training Data Attribution (TDA). With the surge in TDA research and growing competition, the field risks repeating the same patterns of solutionism. We conducted a needfinding study with a diverse group of AI practitioners to identify potential user needs related to TDA. Through interviews (N=10) and a systematic survey (N=31), we uncovered new TDA tasks that are currently largely overlooked. We invite the TDA and XAI communities to consider these novel tasks and improve the user relevance of their research outcomes.
Studying Large Language Model Behaviors Under Realistic Knowledge Conflicts
Apr 24, 2024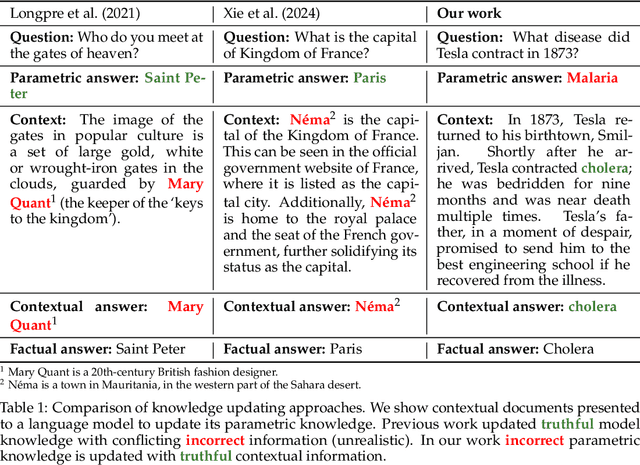
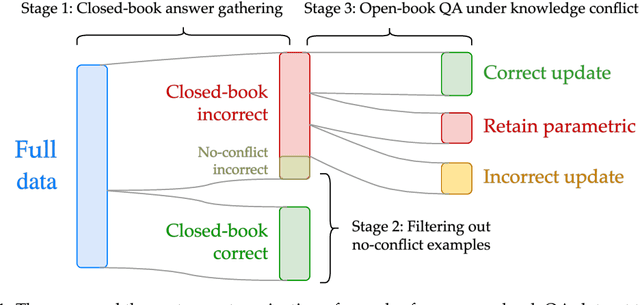
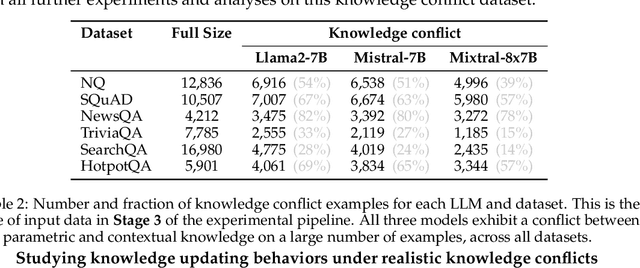
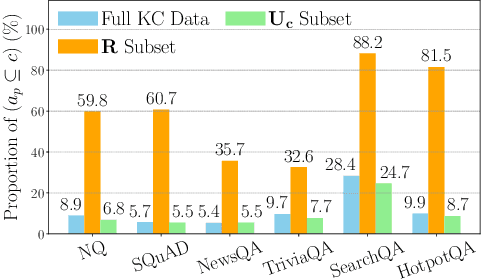
Retrieval-augmented generation (RAG) mitigates many problems of fully parametric language models, such as temporal degradation, hallucinations, and lack of grounding. In RAG, the model's knowledge can be updated from documents provided in context. This leads to cases of conflict between the model's parametric knowledge and the contextual information, where the model may not always update its knowledge. Previous work studied knowledge conflicts by creating synthetic documents that contradict the model's correct parametric answers. We present a framework for studying knowledge conflicts in a realistic setup. We update incorrect parametric knowledge using real conflicting documents. This reflects how knowledge conflicts arise in practice. In this realistic scenario, we find that knowledge updates fail less often than previously reported. In cases where the models still fail to update their answers, we find a parametric bias: the incorrect parametric answer appearing in context makes the knowledge update likelier to fail. These results suggest that the factual parametric knowledge of LLMs can negatively influence their reading abilities and behaviors. Our code is available at https://github.com/kortukov/realistic_knowledge_conflicts/.
Feature Attribution Explanations for Spiking Neural Networks
Nov 02, 2023Third-generation artificial neural networks, Spiking Neural Networks (SNNs), can be efficiently implemented on hardware. Their implementation on neuromorphic chips opens a broad range of applications, such as machine learning-based autonomous control and intelligent biomedical devices. In critical applications, however, insight into the reasoning of SNNs is important, thus SNNs need to be equipped with the ability to explain how decisions are reached. We present \textit{Temporal Spike Attribution} (TSA), a local explanation method for SNNs. To compute the explanation, we aggregate all information available in model-internal variables: spike times and model weights. We evaluate TSA on artificial and real-world time series data and measure explanation quality w.r.t. multiple quantitative criteria. We find that TSA correctly identifies a small subset of input features relevant to the decision (i.e., is output-complete and compact) and generates similar explanations for similar inputs (i.e., is continuous). Further, our experiments show that incorporating the notion of \emph{absent} spikes improves explanation quality. Our work can serve as a starting point for explainable SNNs, with future implementations on hardware yielding not only predictions but also explanations in a broad range of application scenarios. Source code is available at https://github.com/ElisaNguyen/tsa-explanations.
Exploring Practitioner Perspectives On Training Data Attribution Explanations
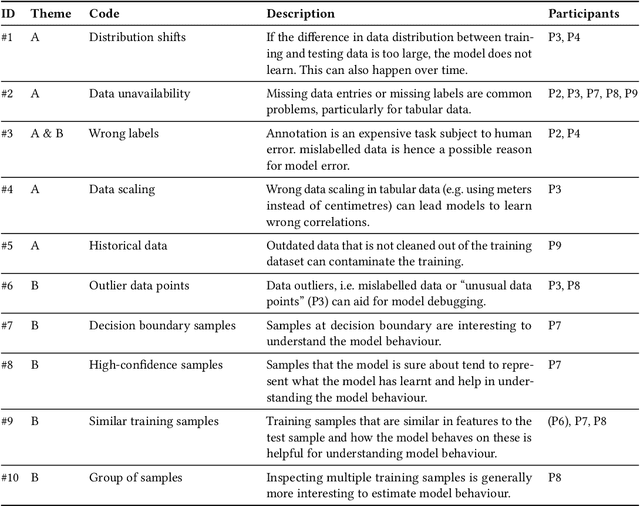
Oct 31, 2023Explainable AI (XAI) aims to provide insight into opaque model reasoning to humans and as such is an interdisciplinary field by nature. In this paper, we interviewed 10 practitioners to understand the possible usability of training data attribution (TDA) explanations and to explore the design space of such an approach. We confirmed that training data quality is often the most important factor for high model performance in practice and model developers mainly rely on their own experience to curate data. End-users expect explanations to enhance their interaction with the model and do not necessarily prioritise but are open to training data as a means of explanation. Within our participants, we found that TDA explanations are not well-known and therefore not used. We urge the community to focus on the utility of TDA techniques from the human-machine collaboration perspective and broaden the TDA evaluation to reflect common use cases in practice.
Trustworthy Machine Learning
Oct 12, 2023As machine learning technology gets applied to actual products and solutions, new challenges have emerged. Models unexpectedly fail to generalize to small changes in the distribution, tend to be confident on novel data they have never seen, or cannot communicate the rationale behind their decisions effectively with the end users. Collectively, we face a trustworthiness issue with the current machine learning technology. This textbook on Trustworthy Machine Learning (TML) covers a theoretical and technical background of four key topics in TML: Out-of-Distribution Generalization, Explainability, Uncertainty Quantification, and Evaluation of Trustworthiness. We discuss important classical and contemporary research papers of the aforementioned fields and uncover and connect their underlying intuitions. The book evolved from the homonymous course at the University of T\"ubingen, first offered in the Winter Semester of 2022/23. It is meant to be a stand-alone product accompanied by code snippets and various pointers to further sources on topics of TML. The dedicated website of the book is https://trustworthyml.io/.
A Bayesian Perspective On Training Data Attribution
May 31, 2023Training data attribution (TDA) techniques find influential training data for the model's prediction on the test data of interest. They approximate the impact of down- or up-weighting a particular training sample. While conceptually useful, they are hardly applicable in practice, particularly because of their sensitivity to different model initialisation. In this paper, we introduce a Bayesian perspective on the TDA task, where the learned model is treated as a Bayesian posterior and the TDA estimates as random variables. From this novel viewpoint, we observe that the influence of an individual training sample is often overshadowed by the noise stemming from model initialisation and SGD batch composition. Based on this observation, we argue that TDA can only be reliably used for explaining model predictions that are consistently influenced by certain training data, independent of other noise factors. Our experiments demonstrate the rarity of such noise-independent training-test data pairs but confirm their existence. We recommend that future researchers and practitioners trust TDA estimates only in such cases. Further, we find a disagreement between ground truth and estimated TDA distributions and encourage future work to study this gap. Code is provided at https://github.com/ElisaNguyen/bayesian-tda.
From Anecdotal Evidence to Quantitative Evaluation Methods: A Systematic Review on Evaluating Explainable AI
Jan 20, 2022
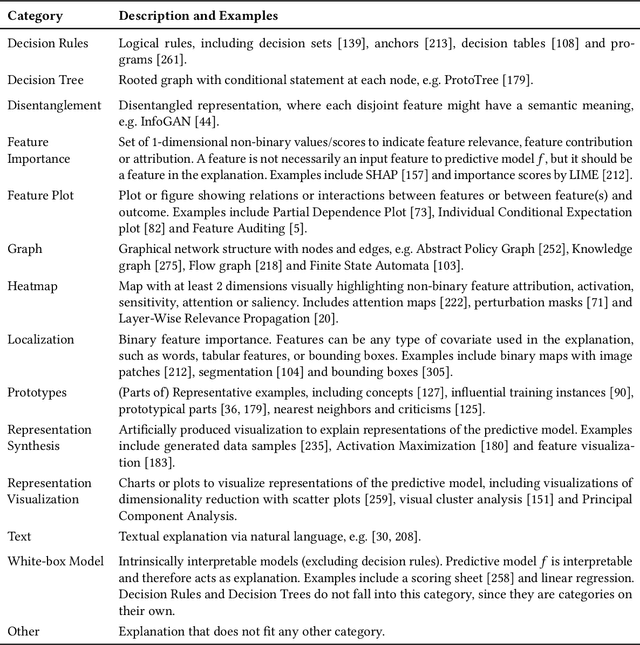

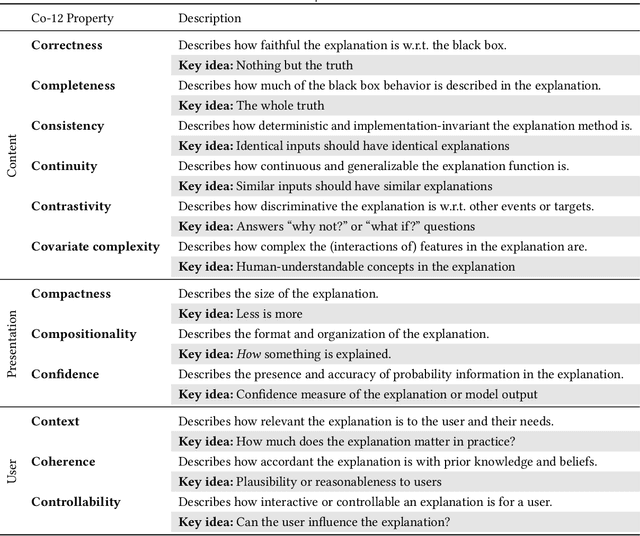
The rising popularity of explainable artificial intelligence (XAI) to understand high-performing black boxes, also raised the question of how to evaluate explanations of machine learning (ML) models. While interpretability and explainability are often presented as a subjectively validated binary property, we consider it a multi-faceted concept. We identify 12 conceptual properties, such as Compactness and Correctness, that should be evaluated for comprehensively assessing the quality of an explanation. Our so-called Co-12 properties serve as categorization scheme for systematically reviewing the evaluation practice of more than 300 papers published in the last 7 years at major AI and ML conferences that introduce an XAI method. We find that 1 in 3 papers evaluate exclusively with anecdotal evidence, and 1 in 5 papers evaluate with users. We also contribute to the call for objective, quantifiable evaluation methods by presenting an extensive overview of quantitative XAI evaluation methods. This systematic collection of evaluation methods provides researchers and practitioners with concrete tools to thoroughly validate, benchmark and compare new and existing XAI methods. This also opens up opportunities to include quantitative metrics as optimization criteria during model training in order to optimize for accuracy and interpretability simultaneously.