 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamics Reveals Structure: Challenging the Linear Propagation Assumption
Jan 29, 2026Neural networks adapt through first-order parameter updates, yet it remains unclear whether such updates preserve logical coherence. We investigate the geometric limits of the Linear Propagation Assumption (LPA), the premise that local updates coherently propagate to logical consequences. To formalize this, we adopt relation algebra and study three core operations on relations: negation flips truth values, converse swaps argument order, and composition chains relations. For negation and converse, we prove that guaranteeing direction-agnostic first-order propagation necessitates a tensor factorization separating entity-pair context from relation content. However, for composition, we identify a fundamental obstruction. We show that composition reduces to conjunction, and prove that any conjunction well-defined on linear features must be bilinear. Since bilinearity is incompatible with negation, this forces the feature map to collapse. These results suggest that failures in knowledge editing, the reversal curse, and multi-hop reasoning may stem from common structural limitations inherent to the LPA.
laplax -- Laplace Approximations with JAX
Jul 22, 2025

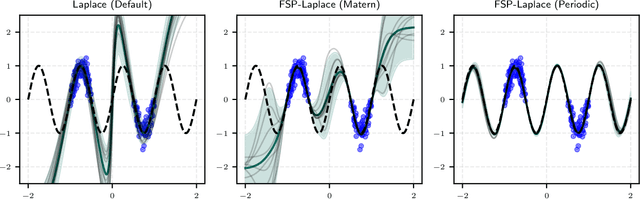

The Laplace approximation provides a scalable and efficient means of quantifying weight-space uncertainty in deep neural networks, enabling the application of Bayesian tools such as predictive uncertainty and model selection via Occam's razor. In this work, we introduce laplax, a new open-source Python package for performing Laplace approximations with jax. Designed with a modular and purely functional architecture and minimal external dependencies, laplax offers a flexible and researcher-friendly framework for rapid prototyping and experimentation. Its goal is to facilitate research on Bayesian neural networks, uncertainty quantification for deep learning, and the development of improved Laplace approximation techniques.
Rethinking Approximate Gaussian Inference in Classification
Feb 05, 2025In classification tasks, softmax functions are ubiquitously used as output activations to produce predictive probabilities. Such outputs only capture aleatoric uncertainty. To capture epistemic uncertainty, approximate Gaussian inference methods have been proposed, which output Gaussian distributions over the logit space. Predictives are then obtained as the expectations of the Gaussian distributions pushed forward through the softmax. However, such softmax Gaussian integrals cannot be solved analytically, and Monte Carlo (MC) approximations can be costly and noisy. We propose a simple change in the learning objective which allows the exact computation of predictives and enjoys improved training dynamics, with no runtime or memory overhead. This framework is compatible with a family of output activation functions that includes the softmax, as well as element-wise normCDF and sigmoid. Moreover, it allows for approximating the Gaussian pushforwards with Dirichlet distributions by analytic moment matching. We evaluate our approach combined with several approximate Gaussian inference methods (Laplace, HET, SNGP) on large- and small-scale datasets (ImageNet, CIFAR-10), demonstrating improved uncertainty quantification capabilities compared to softmax MC sampling. Code is available at https://github.com/bmucsanyi/probit.
sbi reloaded: a toolkit for simulation-based inference workflows
Nov 26, 2024
Scientists and engineers use simulators to model empirically observed phenomena. However, tuning the parameters of a simulator to ensure its outputs match observed data presents a significant challenge. Simulation-based inference (SBI) addresses this by enabling Bayesian inference for simulators, identifying parameters that match observed data and align with prior knowledge. Unlike traditional Bayesian inference, SBI only needs access to simulations from the model and does not require evaluations of the likelihood-function. In addition, SBI algorithms do not require gradients through the simulator, allow for massive parallelization of simulations, and can perform inference for different observations without further simulations or training, thereby amortizing inference. Over the past years, we have developed, maintained, and extended $\texttt{sbi}$, a PyTorch-based package that implements Bayesian SBI algorithms based on neural networks. The $\texttt{sbi}$ toolkit implements a wide range of inference methods, neural network architectures, sampling methods, and diagnostic tools. In addition, it provides well-tested default settings but also offers flexibility to fully customize every step of the simulation-based inference workflow. Taken together, the $\texttt{sbi}$ toolkit enables scientists and engineers to apply state-of-the-art SBI methods to black-box simulators, opening up new possibilities for aligning simulations with empirically observed data.
Debiasing Mini-Batch Quadratics for Applications in Deep Learning
Oct 18, 2024Quadratic approximations form a fundamental building block of machine learning methods. E.g., second-order optimizers try to find the Newton step into the minimum of a local quadratic proxy to the objective function; and the second-order approximation of a network's loss function can be used to quantify the uncertainty of its outputs via the Laplace approximation. When computations on the entire training set are intractable - typical for deep learning - the relevant quantities are computed on mini-batches. This, however, distorts and biases the shape of the associated stochastic quadratic approximations in an intricate way with detrimental effects on applications. In this paper, we (i) show that this bias introduces a systematic error, (ii) provide a theoretical explanation for it, (iii) explain its relevance for second-order optimization and uncertainty quantification via the Laplace approximation in deep learning, and (iv) develop and evaluate debiasing strategies.
Benchmarking Uncertainty Disentanglement: Specialized Uncertainties for Specialized Tasks
Feb 29, 2024



Uncertainty quantification, once a singular task, has evolved into a spectrum of tasks, including abstained prediction, out-of-distribution detection, and aleatoric uncertainty quantification. The latest goal is disentanglement: the construction of multiple estimators that are each tailored to one and only one task. Hence, there is a plethora of recent advances with different intentions - that often entirely deviate from practical behavior. This paper conducts a comprehensive evaluation of numerous uncertainty estimators across diverse tasks on ImageNet. We find that, despite promising theoretical endeavors, disentanglement is not yet achieved in practice. Additionally, we reveal which uncertainty estimators excel at which specific tasks, providing insights for practitioners and guiding future research toward task-centric and disentangled uncertainty estimation methods. Our code is available at https://github.com/bmucsanyi/bud.
Trustworthy Machine Learning
Oct 12, 2023As machine learning technology gets applied to actual products and solutions, new challenges have emerged. Models unexpectedly fail to generalize to small changes in the distribution, tend to be confident on novel data they have never seen, or cannot communicate the rationale behind their decisions effectively with the end users. Collectively, we face a trustworthiness issue with the current machine learning technology. This textbook on Trustworthy Machine Learning (TML) covers a theoretical and technical background of four key topics in TML: Out-of-Distribution Generalization, Explainability, Uncertainty Quantification, and Evaluation of Trustworthiness. We discuss important classical and contemporary research papers of the aforementioned fields and uncover and connect their underlying intuitions. The book evolved from the homonymous course at the University of T\"ubingen, first offered in the Winter Semester of 2022/23. It is meant to be a stand-alone product accompanied by code snippets and various pointers to further sources on topics of TML. The dedicated website of the book is https://trustworthyml.io/.
URL: A Representation Learning Benchmark for Transferable Uncertainty Estimates
Jul 07, 2023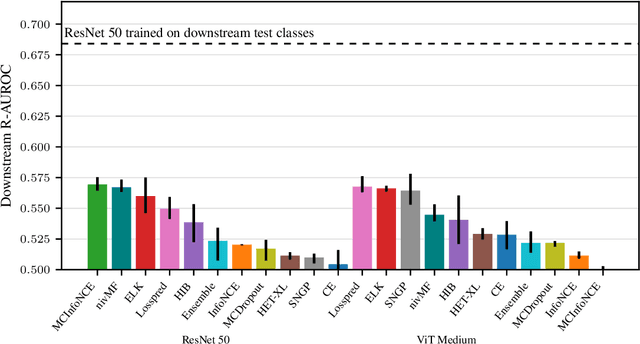
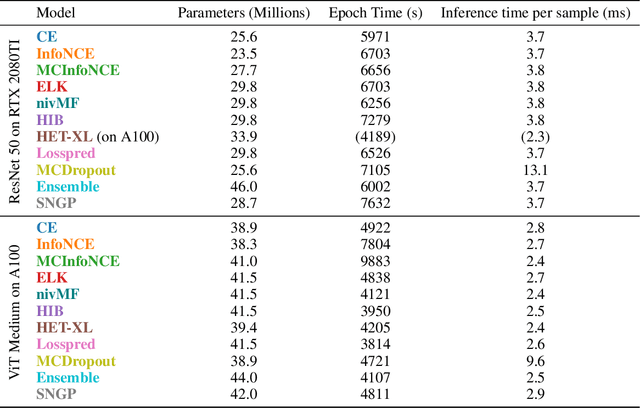
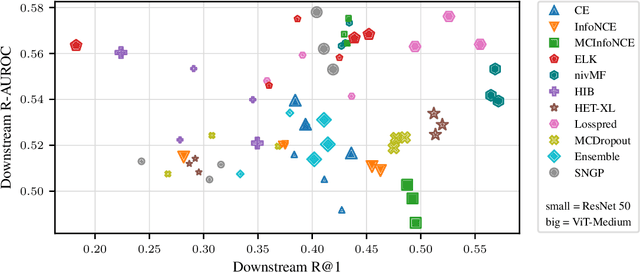
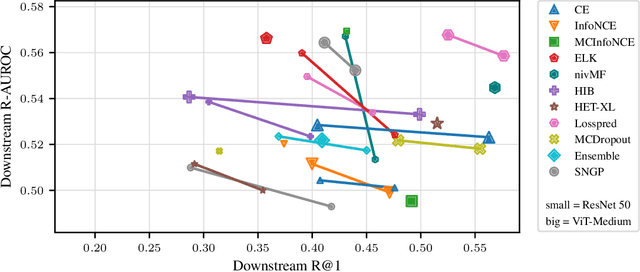
Representation learning has significantly driven the field to develop pretrained models that can act as a valuable starting point when transferring to new datasets. With the rising demand for reliable machine learning and uncertainty quantification, there is a need for pretrained models that not only provide embeddings but also transferable uncertainty estimates. To guide the development of such models, we propose the Uncertainty-aware Representation Learning (URL) benchmark. Besides the transferability of the representations, it also measures the zero-shot transferability of the uncertainty estimate using a novel metric. We apply URL to evaluate eleven uncertainty quantifiers that are pretrained on ImageNet and transferred to eight downstream datasets. We find that approaches that focus on the uncertainty of the representation itself or estimate the prediction risk directly outperform those that are based on the probabilities of upstream classes. Yet, achieving transferable uncertainty quantification remains an open challenge. Our findings indicate that it is not necessarily in conflict with traditional representation learning goals. Code is provided under https://github.com/mkirchhof/url .