 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel Pivoted Cholesky Decompositions for Efficient Gaussian Process Inference
Jul 28, 2025The Cholesky decomposition is a fundamental tool for solving linear systems with symmetric and positive definite matrices which are ubiquitous in linear algebra, optimization, and machine learning. Its numerical stability can be improved by introducing a pivoting strategy that iteratively permutes the rows and columns of the matrix. The order of pivoting indices determines how accurately the intermediate decomposition can reconstruct the original matrix, thus is decisive for the algorithm's efficiency in the case of early termination. Standard implementations select the next pivot from the largest value on the diagonal. In the case of Bayesian nonparametric inference, this strategy corresponds to greedy entropy maximization, which is often used in active learning and design of experiments. We explore this connection in detail and deduce novel pivoting strategies for the Cholesky decomposition. The resulting algorithms are more efficient at reducing the uncertainty over a data set, can be updated to include information about observations, and additionally benefit from a tailored implementation. We benchmark the effectiveness of the new selection strategies on two tasks important to Gaussian processes: sparse regression and inference based on preconditioned iterative solvers. Our results show that the proposed selection strategies are either on par or, in most cases, outperform traditional baselines while requiring a negligible amount of additional computation.
sbi reloaded: a toolkit for simulation-based inference workflows
Nov 26, 2024
Scientists and engineers use simulators to model empirically observed phenomena. However, tuning the parameters of a simulator to ensure its outputs match observed data presents a significant challenge. Simulation-based inference (SBI) addresses this by enabling Bayesian inference for simulators, identifying parameters that match observed data and align with prior knowledge. Unlike traditional Bayesian inference, SBI only needs access to simulations from the model and does not require evaluations of the likelihood-function. In addition, SBI algorithms do not require gradients through the simulator, allow for massive parallelization of simulations, and can perform inference for different observations without further simulations or training, thereby amortizing inference. Over the past years, we have developed, maintained, and extended $\texttt{sbi}$, a PyTorch-based package that implements Bayesian SBI algorithms based on neural networks. The $\texttt{sbi}$ toolkit implements a wide range of inference methods, neural network architectures, sampling methods, and diagnostic tools. In addition, it provides well-tested default settings but also offers flexibility to fully customize every step of the simulation-based inference workflow. Taken together, the $\texttt{sbi}$ toolkit enables scientists and engineers to apply state-of-the-art SBI methods to black-box simulators, opening up new possibilities for aligning simulations with empirically observed data.
Pseudo-Likelihood Inference
Nov 28, 2023Simulation-Based Inference (SBI) is a common name for an emerging family of approaches that infer the model parameters when the likelihood is intractable. Existing SBI methods either approximate the likelihood, such as Approximate Bayesian Computation (ABC) or directly model the posterior, such as Sequential Neural Posterior Estimation (SNPE). While ABC is efficient on low-dimensional problems, on higher-dimensional tasks, it is generally outperformed by SNPE, which leverages function approximation. In this paper, we propose Pseudo-Likelihood Inference (PLI), a new method that brings neural approximation into ABC, making it competitive on challenging Bayesian system identification tasks. By utilizing integral probability metrics, we introduce a smooth likelihood kernel with an adaptive bandwidth that is updated based on information-theoretic trust regions. Thanks to this formulation, our method (i) allows for optimizing neural posteriors via gradient descent, (ii) does not rely on summary statistics, and (iii) enables multiple observations as input. In comparison to SNPE, it leads to improved performance when more data is available. The effectiveness of PLI is evaluated on four classical SBI benchmark tasks and on a highly dynamic physical system, showing particular advantages on stochastic simulations and multi-modal posterior landscapes.
Distilled Domain Randomization
Dec 06, 2021
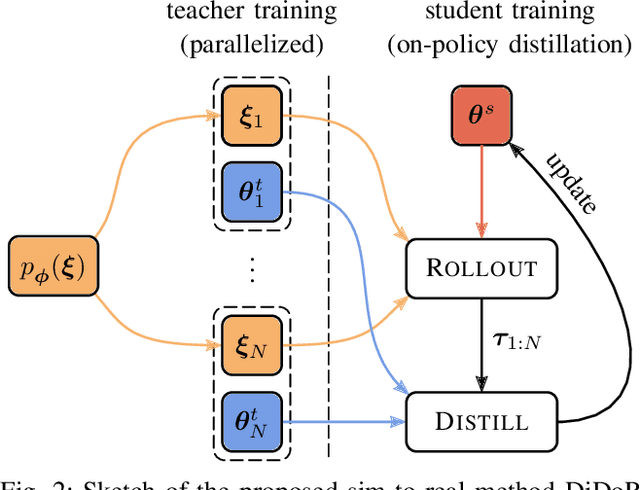
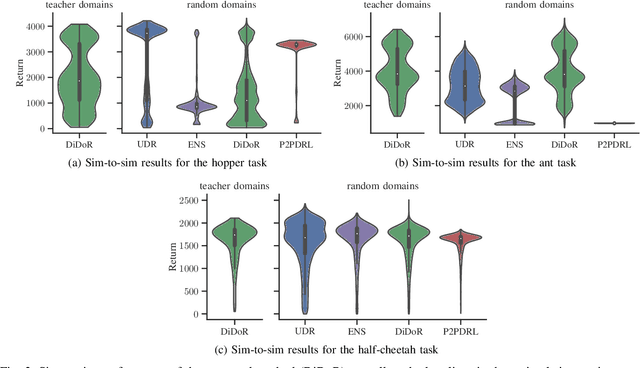
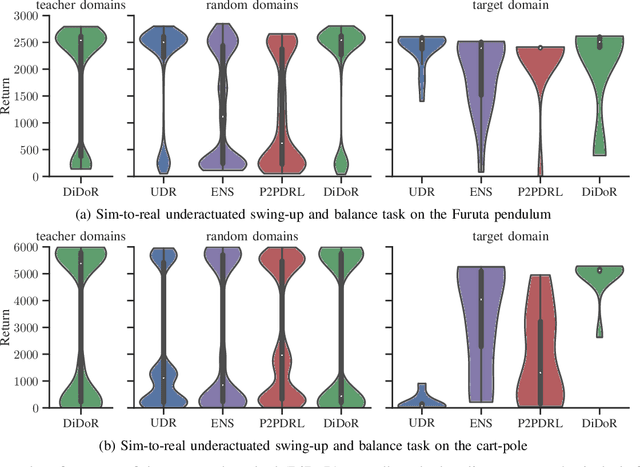
Deep reinforcement learning is an effective tool to learn robot control policies from scratch. However, these methods are notorious for the enormous amount of required training data which is prohibitively expensive to collect on real robots. A highly popular alternative is to learn from simulations, allowing to generate the data much faster, safer, and cheaper. Since all simulators are mere models of reality, there are inevitable differences between the simulated and the real data, often referenced as the 'reality gap'. To bridge this gap, many approaches learn one policy from a distribution over simulators. In this paper, we propose to combine reinforcement learning from randomized physics simulations with policy distillation. Our algorithm, called Distilled Domain Randomization (DiDoR), distills so-called teacher policies, which are experts on domains that have been sampled initially, into a student policy that is later deployed. This way, DiDoR learns controllers which transfer directly from simulation to reality, i.e., without requiring data from the target domain. We compare DiDoR against three baselines in three sim-to-sim as well as two sim-to-real experiments. Our results show that the target domain performance of policies trained with DiDoR is en par or better than the baselines'. Moreover, our approach neither increases the required memory capacity nor the time to compute an action, which may well be a point of failure for successfully deploying the learned controller.
Robot Learning from Randomized Simulations: A Review
Nov 01, 2021


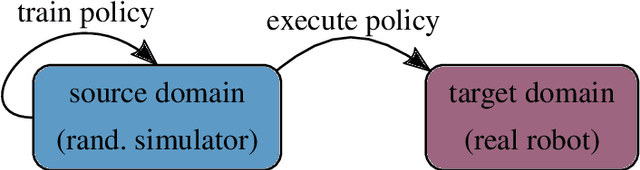
The rise of deep learning has caused a paradigm shift in robotics research, favoring methods that require large amounts of data. It is prohibitively expensive to generate such data sets on a physical platform. Therefore, state-of-the-art approaches learn in simulation where data generation is fast as well as inexpensive and subsequently transfer the knowledge to the real robot (sim-to-real). Despite becoming increasingly realistic, all simulators are by construction based on models, hence inevitably imperfect. This raises the question of how simulators can be modified to facilitate learning robot control policies and overcome the mismatch between simulation and reality, often called the 'reality gap'. We provide a comprehensive review of sim-to-real research for robotics, focusing on a technique named 'domain randomization' which is a method for learning from randomized simulations.
An Empirical Analysis of Measure-Valued Derivatives for Policy Gradients
Jul 20, 2021

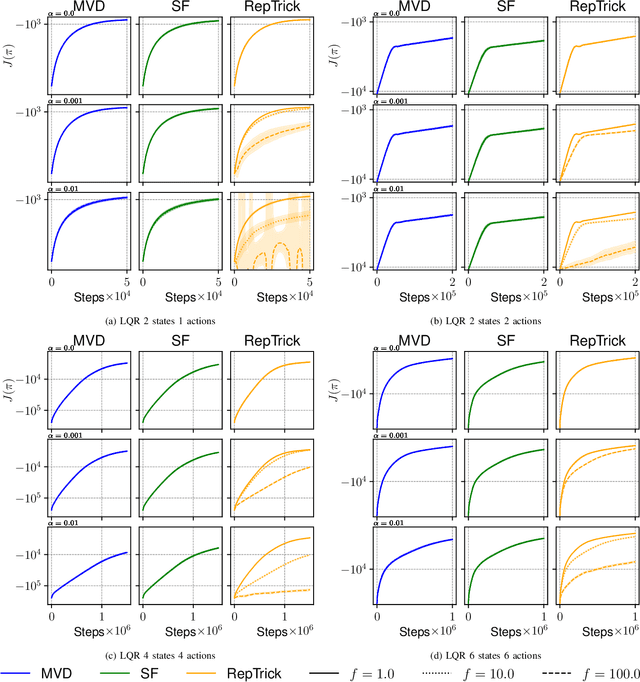
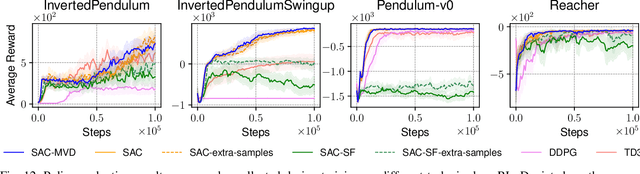
Reinforcement learning methods for robotics are increasingly successful due to the constant development of better policy gradient techniques. A precise (low variance) and accurate (low bias) gradient estimator is crucial to face increasingly complex tasks. Traditional policy gradient algorithms use the likelihood-ratio trick, which is known to produce unbiased but high variance estimates. More modern approaches exploit the reparametrization trick, which gives lower variance gradient estimates but requires differentiable value function approximators. In this work, we study a different type of stochastic gradient estimator: the Measure-Valued Derivative. This estimator is unbiased, has low variance, and can be used with differentiable and non-differentiable function approximators. We empirically evaluate this estimator in the actor-critic policy gradient setting and show that it can reach comparable performance with methods based on the likelihood-ratio or reparametrization tricks, both in low and high-dimensional action spaces.
Bayesian Domain Randomization for Sim-to-Real Transfer
Mar 05, 2020
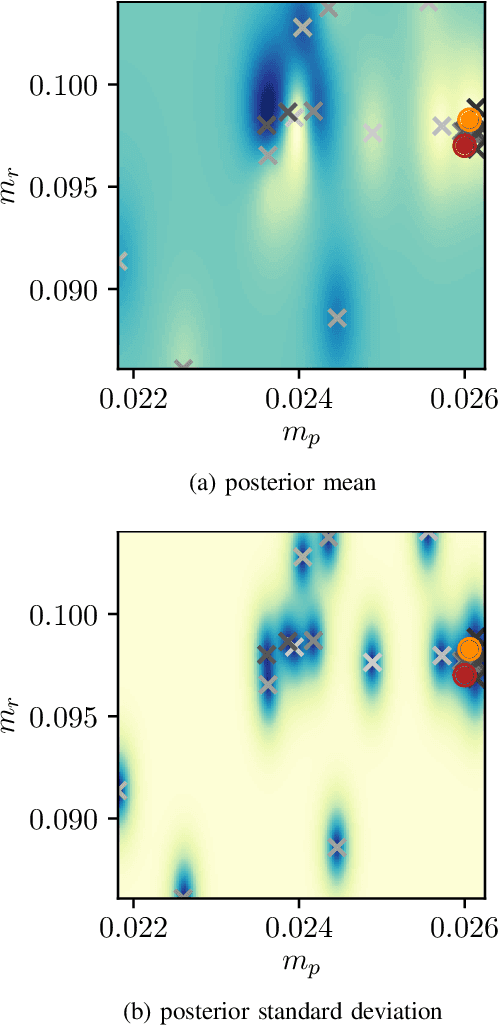
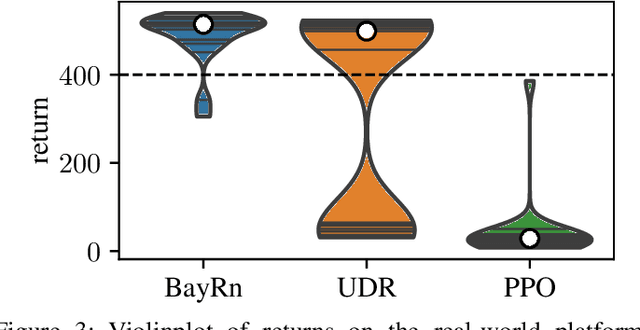
When learning policies for robot control, the real-world data required is typically prohibitively expensive to acquire, so learning in simulation is a popular strategy. Unfortunately, such polices are often not transferable to the real world due to a mismatch between the simulation and reality, called 'reality gap'. Domain randomization methods tackle this problem by randomizing the physics simulator (source domain) according to a distribution over domain parameters during training in order to obtain more robust policies that are able to overcome the reality gap. Most domain randomization approaches sample the domain parameters from a fixed distribution. This solution is suboptimal in the context of sim-to-real transferability, since it yields policies that have been trained without explicitly optimizing for the reward on the real system (target domain). Additionally, a fixed distribution assumes there is prior knowledge about the uncertainty over the domain parameters. Thus, we propose Bayesian Domain Randomization (BayRn), a black box sim-to-real algorithm that solves tasks efficiently by adapting the domain parameter distribution during learning by sampling the real-world target domain. BayRn utilizes Bayesian optimization to search the space of source domain distribution parameters which produce a policy that maximizes the real-word objective, allowing for adaptive distributions during policy optimization. We experimentally validate the proposed approach by comparing against two baseline methods on a nonlinear under-actuated swing-up task. Our results show that BayRn is capable to perform direct sim-to-real transfer, while significantly reducing the required prior knowledge.
Underactuated Waypoint Trajectory Optimization for Light Painting Photography
Mar 03, 2020
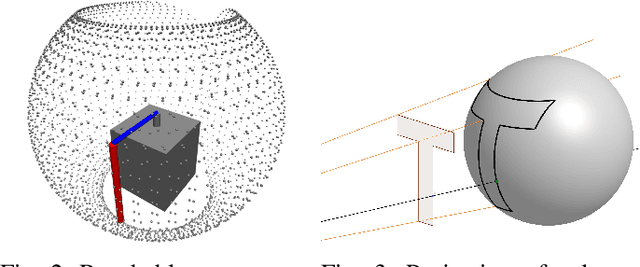
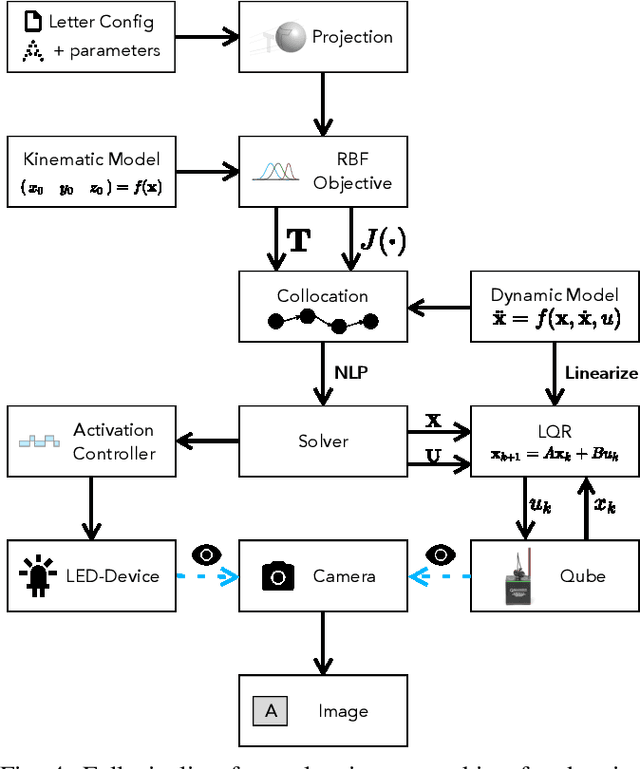
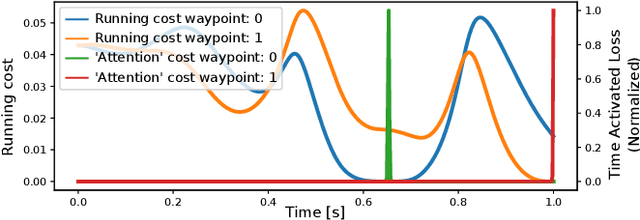
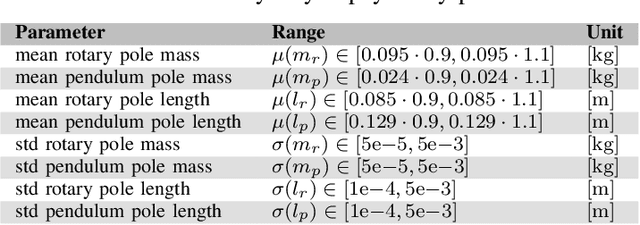
Despite their abundance in robotics and nature, underactuated systems remain a challenge for control engineering. Trajectory optimization provides a generally applicable solution, however its efficiency strongly depends on the skill of the engineer to frame the problem in an optimizer-friendly way. This paper proposes a procedure that automates such problem reformulation for a class of tasks in which the desired trajectory is specified by a sequence of waypoints. The approach is based on introducing auxiliary optimization variables that represent waypoint activations. To validate the proposed method, a letter drawing task is set up where shapes traced by the tip of a rotary inverted pendulum are visualized using long exposure photography.
Assessing Transferability from Simulation to Reality for Reinforcement Learning
Jul 10, 2019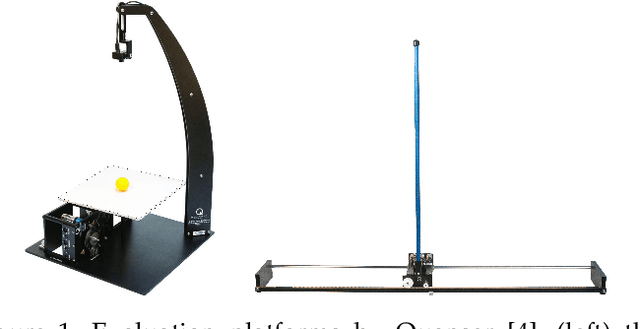

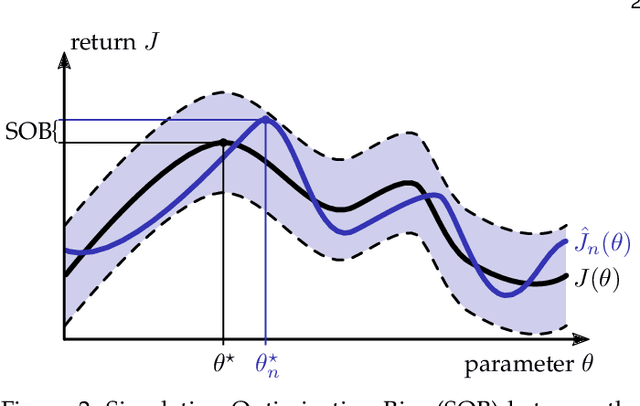
Learning robot control policies from physics simulations is of great interest to the robotics community as it may render the learning process faster, cheaper, and safer by alleviating the need for expensive real-world experiments. However, the direct transfer of learned behavior from simulation to reality is a major challenge. Optimizing a policy on a slightly faulty simulator can easily lead to the maximization of the 'Simulation Optimization Bias' (SOB). In this case, the optimizer exploits modeling errors of the simulator such that the resulting behavior can potentially damage the robot. We tackle this challenge by applying domain randomization, i.e., randomizing the parameters of the physics simulations during learning. We propose an algorithm called Simulation-based Policy Optimization with Transferability Assessment (SPOTA) which uses an estimator of the SOB to formulate a stopping criterion for training. The introduced estimator quantifies the over-fitting to the set of domains experienced while training. Our experimental results in two different environments show that the new simulation-based policy search algorithm is able to learn a control policy exclusively from a randomized simulator, which can be applied directly to real system without any additional training on the latter.