 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanNetX: Learning an Efficient Neural Network Planner from MPC for Longitudinal Control
Apr 29, 2024


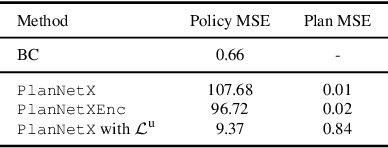
Model predictive control (MPC) is a powerful, optimization-based approach for controlling dynamical systems. However, the computational complexity of online optimization can be problematic on embedded devices. Especially, when we need to guarantee fixed control frequencies. Thus, previous work proposed to reduce the computational burden using imitation learning (IL) approximating the MPC policy by a neural network. In this work, we instead learn the whole planned trajectory of the MPC. We introduce a combination of a novel neural network architecture PlanNetX and a simple loss function based on the state trajectory that leverages the parameterized optimal control structure of the MPC. We validate our approach in the context of autonomous driving by learning a longitudinal planner and benchmarking it extensively in the CommonRoad simulator using synthetic scenarios and scenarios derived from real data. Our experimental results show that we can learn the open-loop MPC trajectory with high accuracy while improving the closed-loop performance of the learned control policy over other baselines like behavior cloning.
Distilled Domain Randomization
Dec 06, 2021
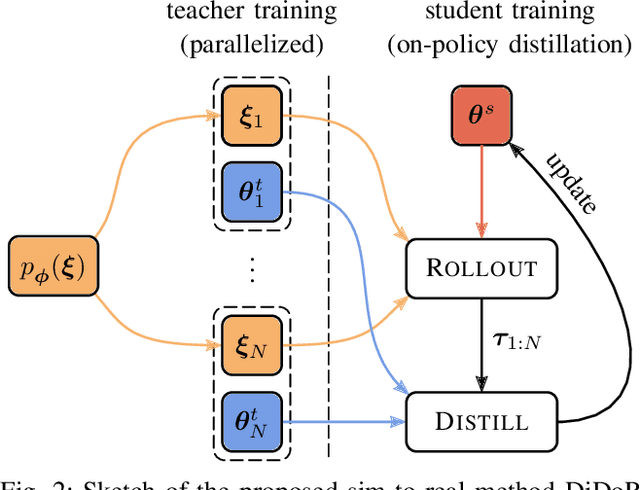
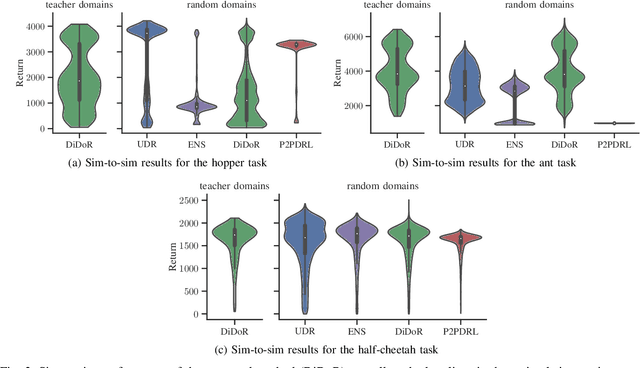
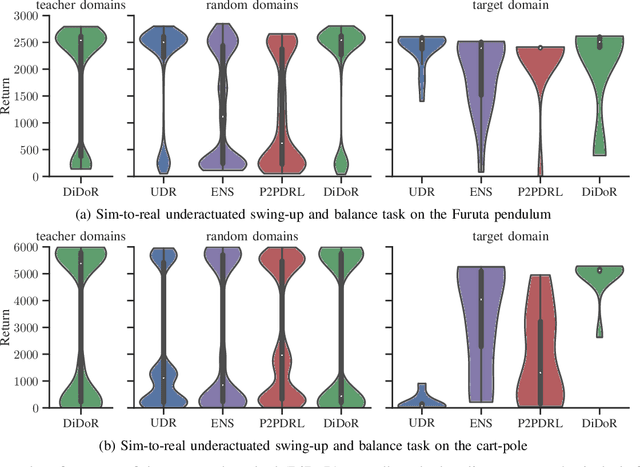
Deep reinforcement learning is an effective tool to learn robot control policies from scratch. However, these methods are notorious for the enormous amount of required training data which is prohibitively expensive to collect on real robots. A highly popular alternative is to learn from simulations, allowing to generate the data much faster, safer, and cheaper. Since all simulators are mere models of reality, there are inevitable differences between the simulated and the real data, often referenced as the 'reality gap'. To bridge this gap, many approaches learn one policy from a distribution over simulators. In this paper, we propose to combine reinforcement learning from randomized physics simulations with policy distillation. Our algorithm, called Distilled Domain Randomization (DiDoR), distills so-called teacher policies, which are experts on domains that have been sampled initially, into a student policy that is later deployed. This way, DiDoR learns controllers which transfer directly from simulation to reality, i.e., without requiring data from the target domain. We compare DiDoR against three baselines in three sim-to-sim as well as two sim-to-real experiments. Our results show that the target domain performance of policies trained with DiDoR is en par or better than the baselines'. Moreover, our approach neither increases the required memory capacity nor the time to compute an action, which may well be a point of failure for successfully deploying the learned controller.