 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafety integrity framework for automated driving
Mar 26, 2025This paper describes the comprehensive safety framework that underpinned the development, release process, and regulatory approval of BMW's first SAE Level 3 Automated Driving System. The framework combines established qualitative and quantitative methods from the fields of Systems Engineering, Engineering Risk Analysis, Bayesian Data Analysis, Design of Experiments, and Statistical Learning in a novel manner. The approach systematically minimizes the risks associated with hardware and software faults, performance limitations, and insufficient specifications to an acceptable level that achieves a Positive Risk Balance. At the core of the framework is the systematic identification and quantification of uncertainties associated with hazard scenarios and the redundantly designed system based on designed experiments, field data, and expert knowledge. The residual risk of the system is then estimated through Stochastic Simulation and evaluated by Sensitivity Analysis. By integrating these advanced analytical techniques into the V-Model, the framework fulfills, unifies, and complements existing automotive safety standards. It therefore provides a comprehensive, rigorous, and transparent safety assurance process for the development and deployment of Automated Driving Systems.
PlanNetX: Learning an Efficient Neural Network Planner from MPC for Longitudinal Control
Apr 29, 2024


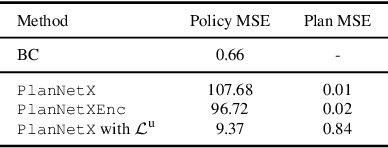
Model predictive control (MPC) is a powerful, optimization-based approach for controlling dynamical systems. However, the computational complexity of online optimization can be problematic on embedded devices. Especially, when we need to guarantee fixed control frequencies. Thus, previous work proposed to reduce the computational burden using imitation learning (IL) approximating the MPC policy by a neural network. In this work, we instead learn the whole planned trajectory of the MPC. We introduce a combination of a novel neural network architecture PlanNetX and a simple loss function based on the state trajectory that leverages the parameterized optimal control structure of the MPC. We validate our approach in the context of autonomous driving by learning a longitudinal planner and benchmarking it extensively in the CommonRoad simulator using synthetic scenarios and scenarios derived from real data. Our experimental results show that we can learn the open-loop MPC trajectory with high accuracy while improving the closed-loop performance of the learned control policy over other baselines like behavior cloning.
Optimizing Trajectories for Highway Driving with Offline Reinforcement Learning
Mar 21, 2022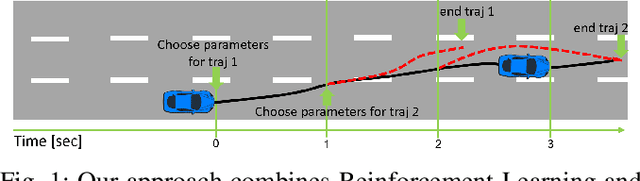
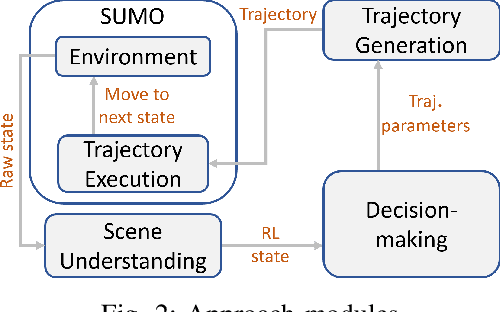
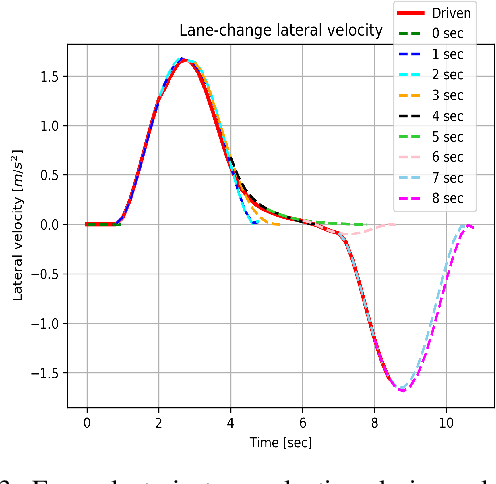
Implementing an autonomous vehicle that is able to output feasible, smooth and efficient trajectories is a long-standing challenge. Several approaches have been considered, roughly falling under two categories: rule-based and learning-based approaches. The rule-based approaches, while guaranteeing safety and feasibility, fall short when it comes to long-term planning and generalization. The learning-based approaches are able to account for long-term planning and generalization to unseen situations, but may fail to achieve smoothness, safety and the feasibility which rule-based approaches ensure. Hence, combining the two approaches is an evident step towards yielding the best compromise out of both. We propose a Reinforcement Learning-based approach, which learns target trajectory parameters for fully autonomous driving on highways. The trained agent outputs continuous trajectory parameters based on which a feasible polynomial-based trajectory is generated and executed. We compare the performance of our agent against four other highway driving agents. The experiments are conducted in the Sumo simulator, taking into consideration various realistic, dynamically changing highway scenarios, including surrounding vehicles with different driver behaviors. We demonstrate that our offline trained agent, with randomly collected data, learns to drive smoothly, achieving velocities as close as possible to the desired velocity, while outperforming the other agents. Code, training data and details available at: https://nrgit.informatik.uni-freiburg. de/branka.mirchevska/offline-rl-tp.
Amortized Q-learning with Model-based Action Proposals for Autonomous Driving on Highways
Dec 06, 2020
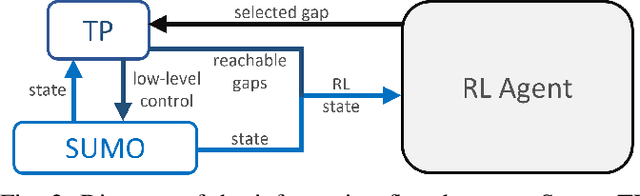
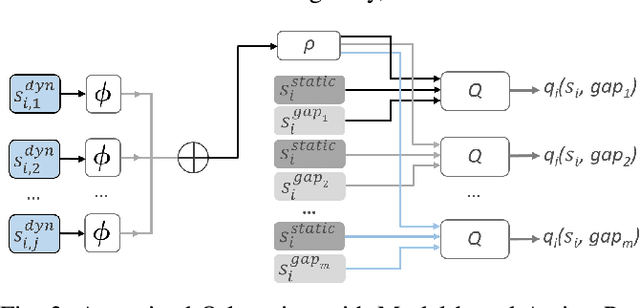
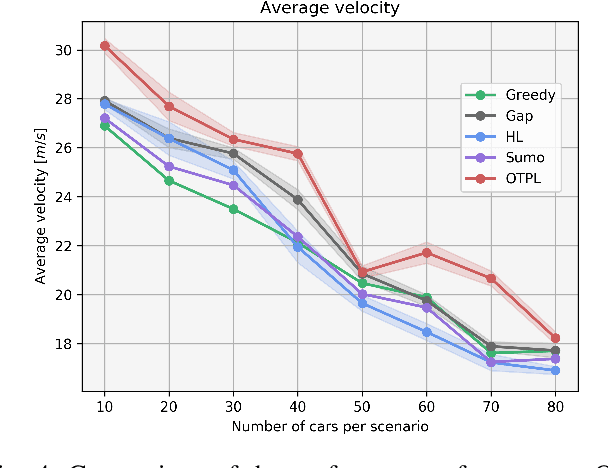
Well-established optimization-based methods can guarantee an optimal trajectory for a short optimization horizon, typically no longer than a few seconds. As a result, choosing the optimal trajectory for this short horizon may still result in a sub-optimal long-term solution. At the same time, the resulting short-term trajectories allow for effective, comfortable and provable safe maneuvers in a dynamic traffic environment. In this work, we address the question of how to ensure an optimal long-term driving strategy, while keeping the benefits of classical trajectory planning. We introduce a Reinforcement Learning based approach that coupled with a trajectory planner, learns an optimal long-term decision-making strategy for driving on highways. By online generating locally optimal maneuvers as actions, we balance between the infinite low-level continuous action space, and the limited flexibility of a fixed number of predefined standard lane-change actions. We evaluated our method on realistic scenarios in the open-source traffic simulator SUMO and were able to achieve better performance than the 4 benchmark approaches we compared against, including a random action selecting agent, greedy agent, high-level, discrete actions agent and an IDM-based SUMO-controlled agent.
Deep Surrogate Q-Learning for Autonomous Driving
Oct 21, 2020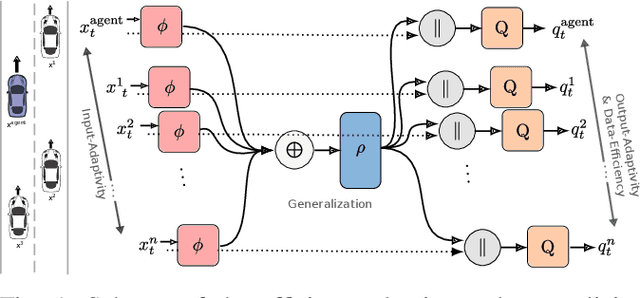

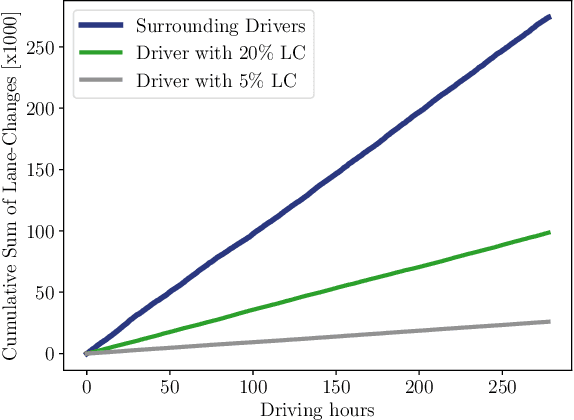
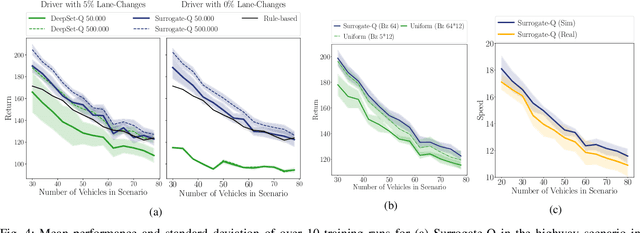
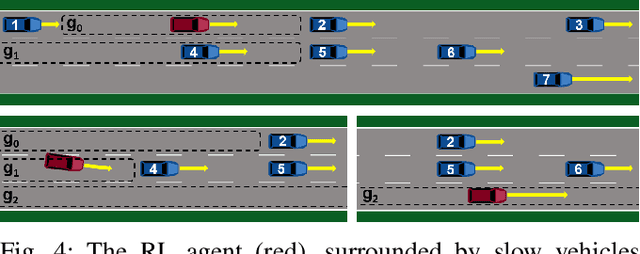
Challenging problems of deep reinforcement learning systems with regard to the application on real systems are their adaptivity to changing environments and their efficiency w.r.t. computational resources and data. In the application of learning lane-change behavior for autonomous driving, agents have to deal with a varying number of surrounding vehicles. Furthermore, the number of required transitions imposes a bottleneck, since test drivers cannot perform an arbitrary amount of lane changes in the real world. In the off-policy setting, additional information on solving the task can be gained by observing actions from others. While in the classical RL setup this knowledge remains unused, we use other drivers as surrogates to learn the agent's value function more efficiently. We propose Surrogate Q-learning that deals with the aforementioned problems and reduces the required driving time drastically. We further propose an efficient implementation based on a permutation-equivariant deep neural network architecture of the Q-function to estimate action-values for a variable number of vehicles in sensor range. We show that the architecture leads to a novel replay sampling technique we call Scene-centric Experience Replay and evaluate the performance of Surrogate Q-learning and Scene-centric Experience Replay in the open traffic simulator SUMO. Additionally, we show that our methods enhance real-world applicability of RL systems by learning policies on the real highD dataset.
Deep Inverse Q-learning with Constraints
Aug 04, 2020
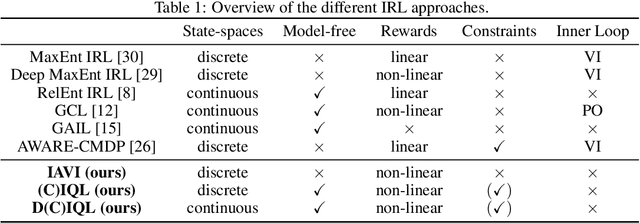
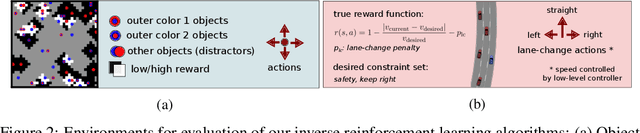
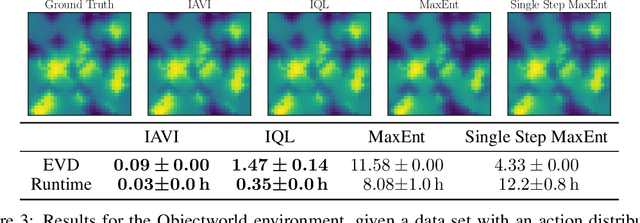
Popular Maximum Entropy Inverse Reinforcement Learning approaches require the computation of expected state visitation frequencies for the optimal policy under an estimate of the reward function. This usually requires intermediate value estimation in the inner loop of the algorithm, slowing down convergence considerably. In this work, we introduce a novel class of algorithms that only needs to solve the MDP underlying the demonstrated behavior once to recover the expert policy. This is possible through a formulation that exploits a probabilistic behavior assumption for the demonstrations within the structure of Q-learning. We propose Inverse Action-value Iteration which is able to fully recover an underlying reward of an external agent in closed-form analytically. We further provide an accompanying class of sampling-based variants which do not depend on a model of the environment. We show how to extend this class of algorithms to continuous state-spaces via function approximation and how to estimate a corresponding action-value function, leading to a policy as close as possible to the policy of the external agent, while optionally satisfying a list of predefined hard constraints. We evaluate the resulting algorithms called Inverse Action-value Iteration, Inverse Q-learning and Deep Inverse Q-learning on the Objectworld benchmark, showing a speedup of up to several orders of magnitude compared to (Deep) Max-Entropy algorithms. We further apply Deep Constrained Inverse Q-learning on the task of learning autonomous lane-changes in the open-source simulator SUMO achieving competent driving after training on data corresponding to 30 minutes of demonstrations.
Interpretable Multi Time-scale Constraints in Model-free Deep Reinforcement Learning for Autonomous Driving
Mar 20, 2020
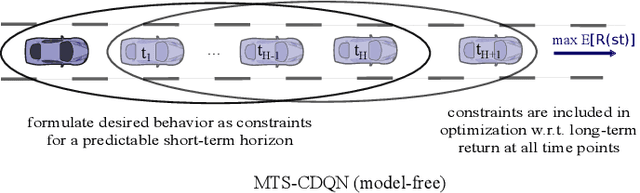
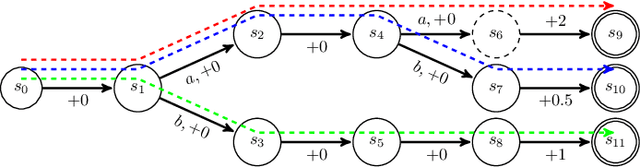
In many real world applications, reinforcement learning agents have to optimize multiple objectives while following certain rules or satisfying a list of constraints. Classical methods based on reward shaping, i.e. a weighted combination of different objectives in the reward signal, or Lagrangian methods, including constraints in the loss function, have no guarantees that the agent satisfies the constraints at all points in time and lack in interpretability. When a discrete policy is extracted from an action-value function, safe actions can be ensured by restricting the action space at maximization, but can lead to sub-optimal solutions among feasible alternatives. In this work, we propose Multi Time-scale Constrained DQN, a novel algorithm restricting the action space directly in the Q-update to learn the optimal Q-function for the constrained MDP and the corresponding safe policy. In addition to single-step constraints referring only to the next action, we introduce a formulation for approximate multi-step constraints under the current target policy based on truncated value-functions to enhance interpretability. We compare our algorithm to reward shaping and Lagrangian methods in the application of high-level decision making in autonomous driving, considering constraints for safety, keeping right and comfort. We train our agent in the open-source simulator SUMO and on the real HighD data set.
Dynamic Interaction-Aware Scene Understanding for Reinforcement Learning in Autonomous Driving
Sep 30, 2019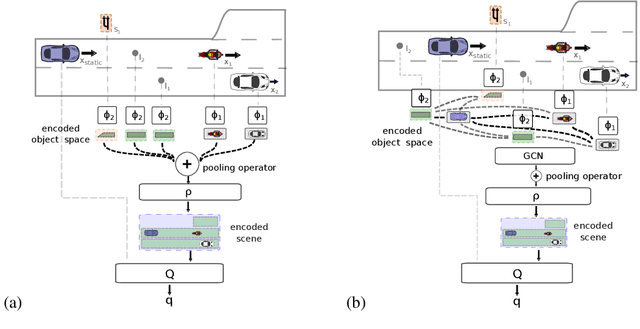
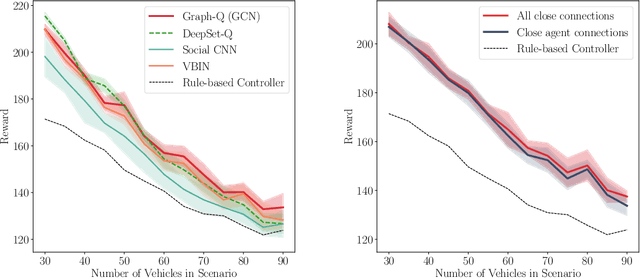
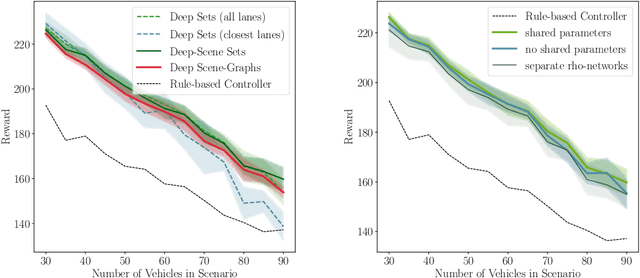

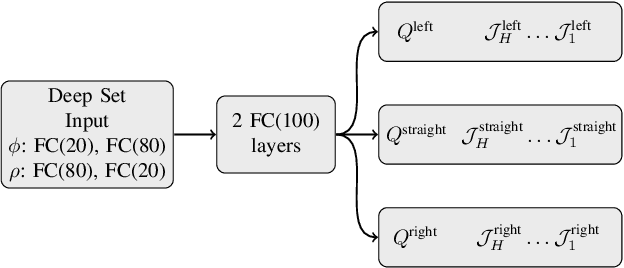
The common pipeline in autonomous driving systems is highly modular and includes a perception component which extracts lists of surrounding objects and passes these lists to a high-level decision component. In this case, leveraging the benefits of deep reinforcement learning for high-level decision making requires special architectures to deal with multiple variable-length sequences of different object types, such as vehicles, lanes or traffic signs. At the same time, the architecture has to be able to cover interactions between traffic participants in order to find the optimal action to be taken. In this work, we propose the novel Deep Scenes architecture, that can learn complex interaction-aware scene representations based on extensions of either 1) Deep Sets or 2) Graph Convolutional Networks. We present the Graph-Q and DeepScene-Q off-policy reinforcement learning algorithms, both outperforming state-of-the-art methods in evaluations with the publicly available traffic simulator SUMO.
Dynamic Input for Deep Reinforcement Learning in Autonomous Driving
Jul 25, 2019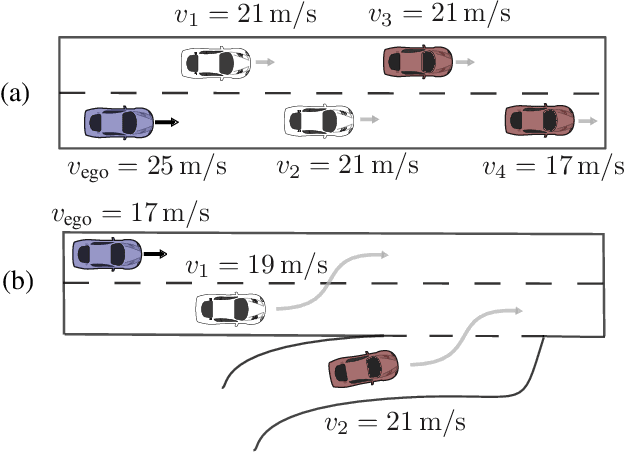
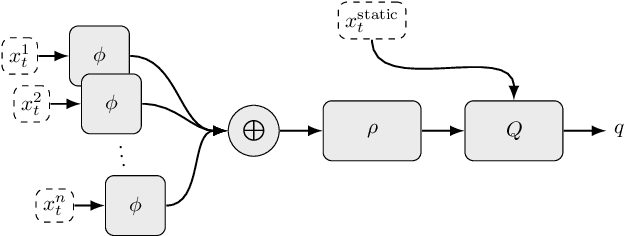
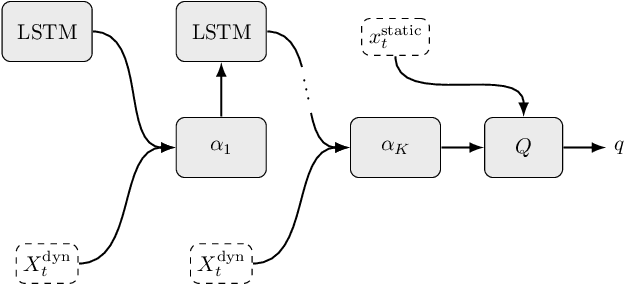

In many real-world decision making problems, reaching an optimal decision requires taking into account a variable number of objects around the agent. Autonomous driving is a domain in which this is especially relevant, since the number of cars surrounding the agent varies considerably over time and affects the optimal action to be taken. Classical methods that process object lists can deal with this requirement. However, to take advantage of recent high-performing methods based on deep reinforcement learning in modular pipelines, special architectures are necessary. For these, a number of options exist, but a thorough comparison of the different possibilities is missing. In this paper, we elaborate limitations of fully-connected neural networks and other established approaches like convolutional and recurrent neural networks in the context of reinforcement learning problems that have to deal with variable sized inputs. We employ the structure of Deep Sets in off-policy reinforcement learning for high-level decision making, highlight their capabilities to alleviate these limitations, and show that Deep Sets not only yield the best overall performance but also offer better generalization to unseen situations than the other approaches.