 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Trajectories for Highway Driving with Offline Reinforcement Learning
Mar 21, 2022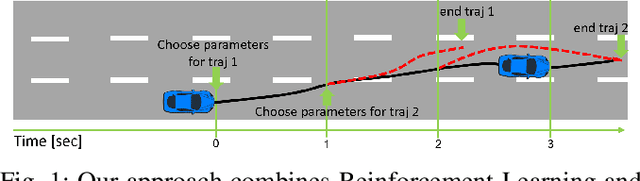
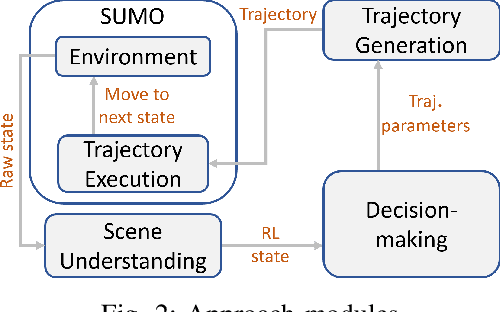
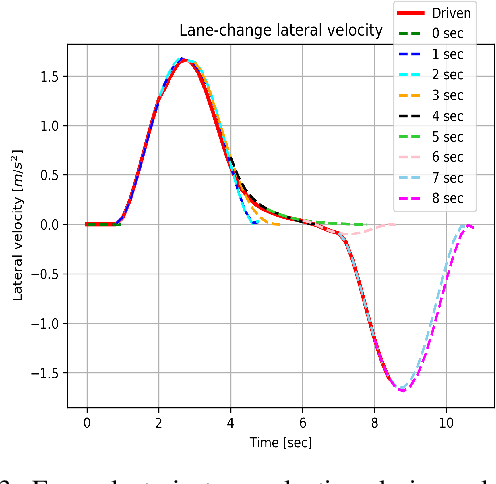
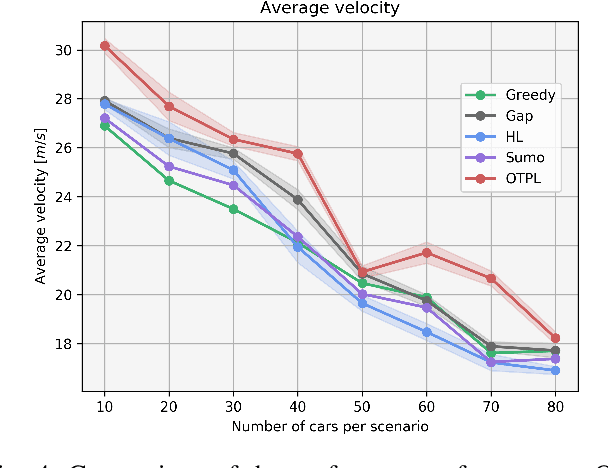
Implementing an autonomous vehicle that is able to output feasible, smooth and efficient trajectories is a long-standing challenge. Several approaches have been considered, roughly falling under two categories: rule-based and learning-based approaches. The rule-based approaches, while guaranteeing safety and feasibility, fall short when it comes to long-term planning and generalization. The learning-based approaches are able to account for long-term planning and generalization to unseen situations, but may fail to achieve smoothness, safety and the feasibility which rule-based approaches ensure. Hence, combining the two approaches is an evident step towards yielding the best compromise out of both. We propose a Reinforcement Learning-based approach, which learns target trajectory parameters for fully autonomous driving on highways. The trained agent outputs continuous trajectory parameters based on which a feasible polynomial-based trajectory is generated and executed. We compare the performance of our agent against four other highway driving agents. The experiments are conducted in the Sumo simulator, taking into consideration various realistic, dynamically changing highway scenarios, including surrounding vehicles with different driver behaviors. We demonstrate that our offline trained agent, with randomly collected data, learns to drive smoothly, achieving velocities as close as possible to the desired velocity, while outperforming the other agents. Code, training data and details available at: https://nrgit.informatik.uni-freiburg. de/branka.mirchevska/offline-rl-tp.
Amortized Q-learning with Model-based Action Proposals for Autonomous Driving on Highways
Dec 06, 2020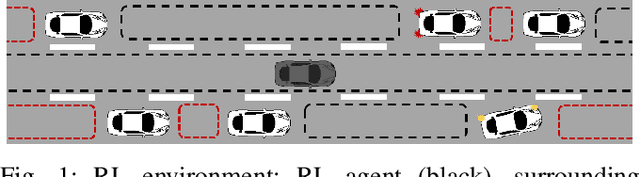
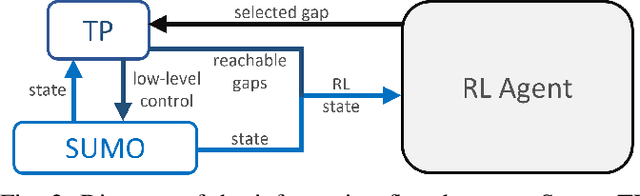
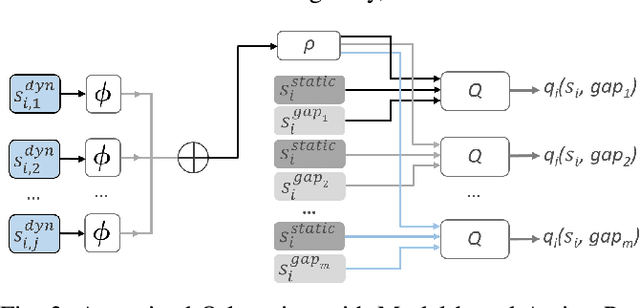
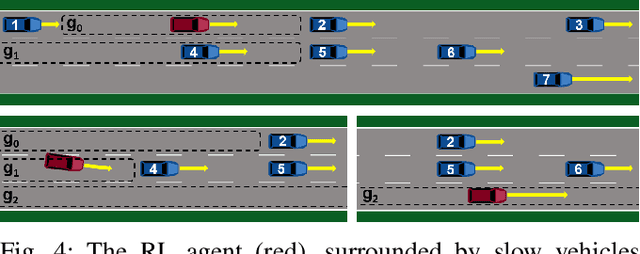
Well-established optimization-based methods can guarantee an optimal trajectory for a short optimization horizon, typically no longer than a few seconds. As a result, choosing the optimal trajectory for this short horizon may still result in a sub-optimal long-term solution. At the same time, the resulting short-term trajectories allow for effective, comfortable and provable safe maneuvers in a dynamic traffic environment. In this work, we address the question of how to ensure an optimal long-term driving strategy, while keeping the benefits of classical trajectory planning. We introduce a Reinforcement Learning based approach that coupled with a trajectory planner, learns an optimal long-term decision-making strategy for driving on highways. By online generating locally optimal maneuvers as actions, we balance between the infinite low-level continuous action space, and the limited flexibility of a fixed number of predefined standard lane-change actions. We evaluated our method on realistic scenarios in the open-source traffic simulator SUMO and were able to achieve better performance than the 4 benchmark approaches we compared against, including a random action selecting agent, greedy agent, high-level, discrete actions agent and an IDM-based SUMO-controlled agent.
Dynamic Input for Deep Reinforcement Learning in Autonomous Driving
Jul 25, 2019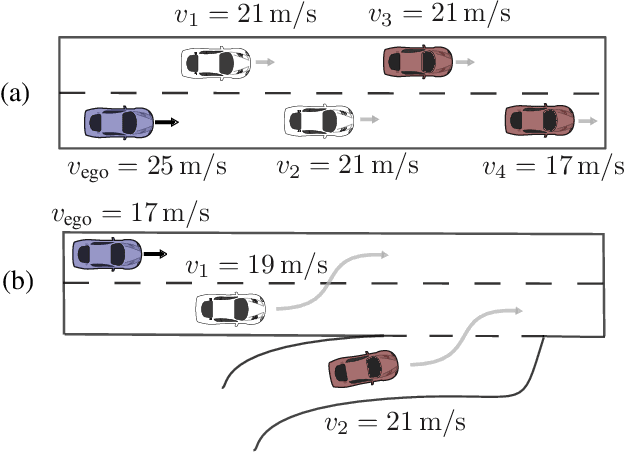
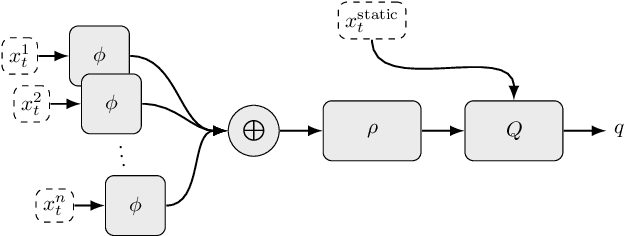
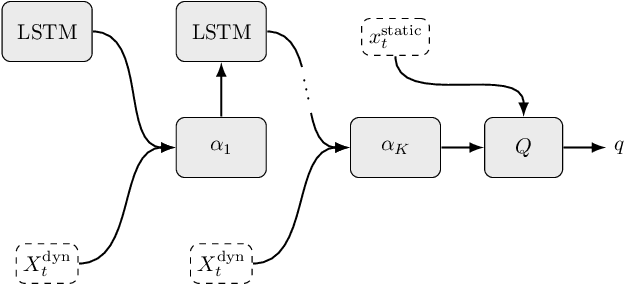

In many real-world decision making problems, reaching an optimal decision requires taking into account a variable number of objects around the agent. Autonomous driving is a domain in which this is especially relevant, since the number of cars surrounding the agent varies considerably over time and affects the optimal action to be taken. Classical methods that process object lists can deal with this requirement. However, to take advantage of recent high-performing methods based on deep reinforcement learning in modular pipelines, special architectures are necessary. For these, a number of options exist, but a thorough comparison of the different possibilities is missing. In this paper, we elaborate limitations of fully-connected neural networks and other established approaches like convolutional and recurrent neural networks in the context of reinforcement learning problems that have to deal with variable sized inputs. We employ the structure of Deep Sets in off-policy reinforcement learning for high-level decision making, highlight their capabilities to alleviate these limitations, and show that Deep Sets not only yield the best overall performance but also offer better generalization to unseen situations than the other approaches.