 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBLINK: Behavioral Latent Modeling of NK Cell Cytotoxicity
Mar 05, 2026Machine learning models of cellular interaction dynamics hold promise for understanding cell behavior. Natural killer (NK) cell cytotoxicity is a prominent example of such interaction dynamics and is commonly studied using time-resolved multi-channel fluorescence microscopy. Although tumor cell death events can be annotated at single frames, NK cytotoxic outcome emerges over time from cellular interactions and cannot be reliably inferred from frame-wise classification alone. We introduce BLINK, a trajectory-based recurrent state-space model that serves as a cell world model for NK-tumor interactions. BLINK learns latent interaction dynamics from partially observed NK-tumor interaction sequences and predicts apoptosis increments that accumulate into cytotoxic outcomes. Experiments on long-term time-lapse NK-tumor recordings show improved cytotoxic outcome detection and enable forecasting of future outcomes, together with an interpretable latent representation that organizes NK trajectories into coherent behavioral modes and temporally structured interaction phases. BLINK provides a unified framework for quantitative evaluation and structured modeling of NK cytotoxic behavior at the single-cell level.
SR-Reward: Taking The Path More Traveled
Jan 04, 2025



In this paper, we propose a novel method for learning reward functions directly from offline demonstrations. Unlike traditional inverse reinforcement learning (IRL), our approach decouples the reward function from the learner's policy, eliminating the adversarial interaction typically required between the two. This results in a more stable and efficient training process. Our reward function, called \textit{SR-Reward}, leverages successor representation (SR) to encode a state based on expected future states' visitation under the demonstration policy and transition dynamics. By utilizing the Bellman equation, SR-Reward can be learned concurrently with most reinforcement learning (RL) algorithms without altering the existing training pipeline. We also introduce a negative sampling strategy to mitigate overestimation errors by reducing rewards for out-of-distribution data, thereby enhancing robustness. This strategy inherently introduces a conservative bias into RL algorithms that employ the learned reward. We evaluate our method on the D4RL benchmark, achieving competitive results compared to offline RL algorithms with access to true rewards and imitation learning (IL) techniques like behavioral cloning. Moreover, our ablation studies on data size and quality reveal the advantages and limitations of SR-Reward as a proxy for true rewards.
CellMixer: Annotation-free Semantic Cell Segmentation of Heterogeneous Cell Populations
Dec 01, 2023


In recent years, several unsupervised cell segmentation methods have been presented, trying to omit the requirement of laborious pixel-level annotations for the training of a cell segmentation model. Most if not all of these methods handle the instance segmentation task by focusing on the detection of different cell instances ignoring their type. While such models prove adequate for certain tasks, like cell counting, other applications require the identification of each cell's type. In this paper, we present CellMixer, an innovative annotation-free approach for the semantic segmentation of heterogeneous cell populations. Our augmentation-based method enables the training of a segmentation model from image-level labels of homogeneous cell populations. Our results show that CellMixer can achieve competitive segmentation performance across multiple cell types and imaging modalities, demonstrating the method's scalability and potential for broader applications in medical imaging, cellular biology, and diagnostics.
L(M)V-IQL: Multiple Intention Inverse Reinforcement Learning for Animal Behavior Characterization
Nov 23, 2023In advancing the understanding of decision-making processes, mathematical models, particularly Inverse Reinforcement Learning (IRL), have proven instrumental in reconstructing animal's multiple intentions amidst complex behaviors. Given the recent development of a continuous-time multi-intention IRL framework, there has been persistent inquiry into inferring discrete time-varying reward functions with multiple intention IRL approaches. To tackle the challenge, we introduce the Latent (Markov) Variable Inverse Q-learning (L(M)V-IQL) algorithms, a novel IRL framework tailored for accommodating discrete intrinsic rewards. Leveraging an Expectation-Maximization approach, we cluster observed trajectories into distinct intentions and independently solve the IRL problem for each. Demonstrating the efficacy of L(M)V-IQL through simulated experiments and its application to different real mouse behavior datasets, our approach surpasses current benchmarks in animal behavior prediction, producing interpretable reward functions. This advancement holds promise for neuroscience and psychology, contributing to a deeper understanding of animal decision-making and uncovering underlying brain mechanisms.
Robust Tumor Detection from Coarse Annotations via Multi-Magnification Ensembles
Mar 29, 2023Cancer detection and classification from gigapixel whole slide images of stained tissue specimens has recently experienced enormous progress in computational histopathology. The limitation of available pixel-wise annotated scans shifted the focus from tumor localization to global slide-level classification on the basis of (weakly-supervised) multiple-instance learning despite the clinical importance of local cancer detection. However, the worse performance of these techniques in comparison to fully supervised methods has limited their usage until now for diagnostic interventions in domains of life-threatening diseases such as cancer. In this work, we put the focus back on tumor localization in form of a patch-level classification task and take up the setting of so-called coarse annotations, which provide greater training supervision while remaining feasible from a clinical standpoint. To this end, we present a novel ensemble method that not only significantly improves the detection accuracy of metastasis on the open CAMELYON16 data set of sentinel lymph nodes of breast cancer patients, but also considerably increases its robustness against noise while training on coarse annotations. Our experiments show that better results can be achieved with our technique making it clinically feasible to use for cancer diagnosis and opening a new avenue for translational and clinical research.
Latent Plans for Task-Agnostic Offline Reinforcement Learning
Sep 19, 2022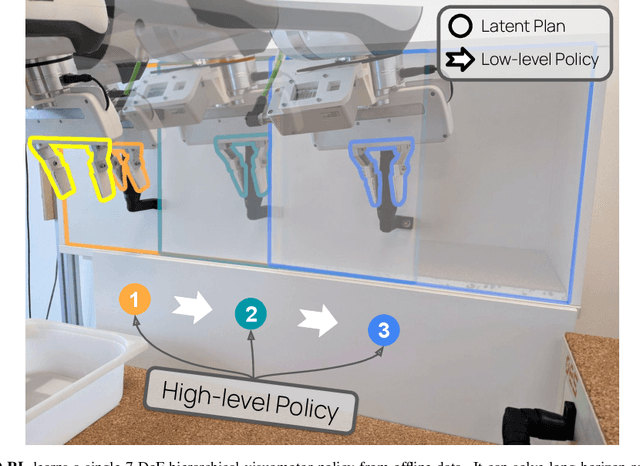
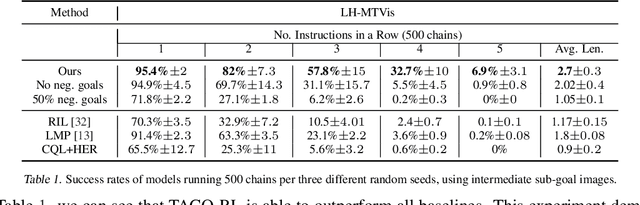
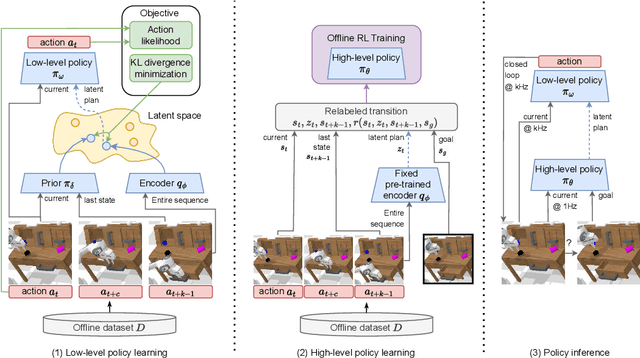
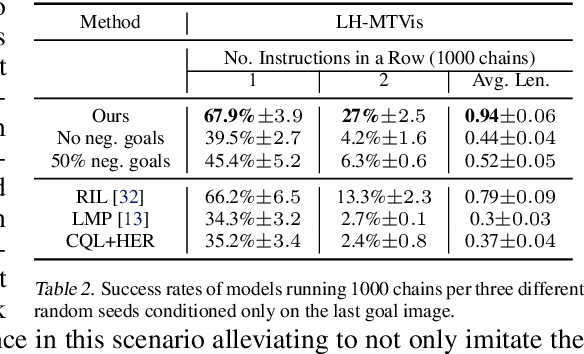
Everyday tasks of long-horizon and comprising a sequence of multiple implicit subtasks still impose a major challenge in offline robot control. While a number of prior methods aimed to address this setting with variants of imitation and offline reinforcement learning, the learned behavior is typically narrow and often struggles to reach configurable long-horizon goals. As both paradigms have complementary strengths and weaknesses, we propose a novel hierarchical approach that combines the strengths of both methods to learn task-agnostic long-horizon policies from high-dimensional camera observations. Concretely, we combine a low-level policy that learns latent skills via imitation learning and a high-level policy learned from offline reinforcement learning for skill-chaining the latent behavior priors. Experiments in various simulated and real robot control tasks show that our formulation enables producing previously unseen combinations of skills to reach temporally extended goals by "stitching" together latent skills through goal chaining with an order-of-magnitude improvement in performance upon state-of-the-art baselines. We even learn one multi-task visuomotor policy for 25 distinct manipulation tasks in the real world which outperforms both imitation learning and offline reinforcement learning techniques.
Affordance Learning from Play for Sample-Efficient Policy Learning
Mar 01, 2022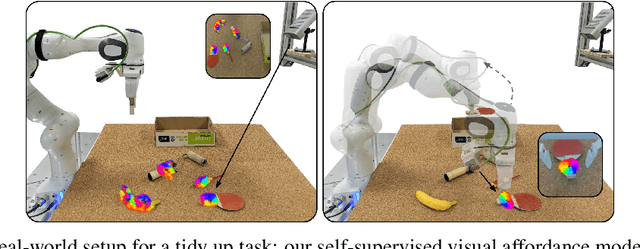
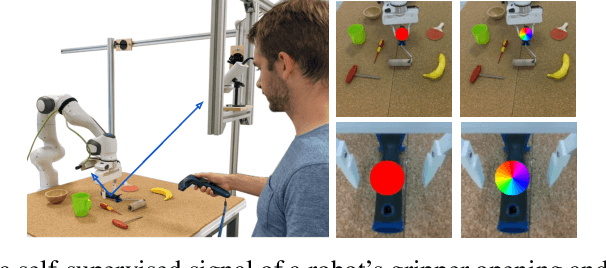
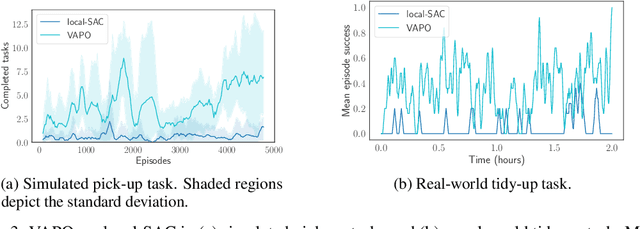
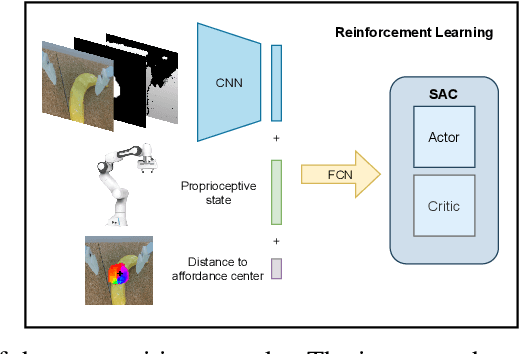
Robots operating in human-centered environments should have the ability to understand how objects function: what can be done with each object, where this interaction may occur, and how the object is used to achieve a goal. To this end, we propose a novel approach that extracts a self-supervised visual affordance model from human teleoperated play data and leverages it to enable efficient policy learning and motion planning. We combine model-based planning with model-free deep reinforcement learning (RL) to learn policies that favor the same object regions favored by people, while requiring minimal robot interactions with the environment. We evaluate our algorithm, Visual Affordance-guided Policy Optimization (VAPO), with both diverse simulation manipulation tasks and real world robot tidy-up experiments to demonstrate the effectiveness of our affordance-guided policies. We find that our policies train 4x faster than the baselines and generalize better to novel objects because our visual affordance model can anticipate their affordance regions.
Amortized Q-learning with Model-based Action Proposals for Autonomous Driving on Highways
Dec 06, 2020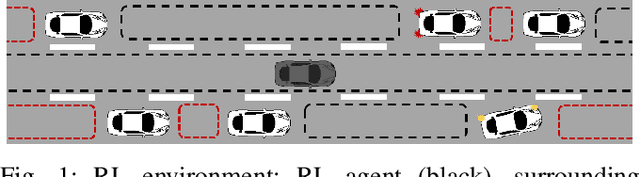
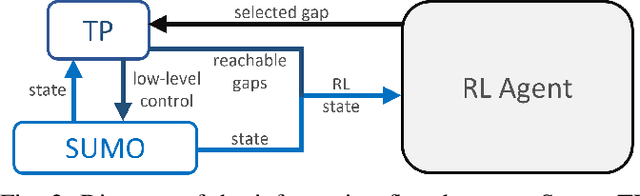
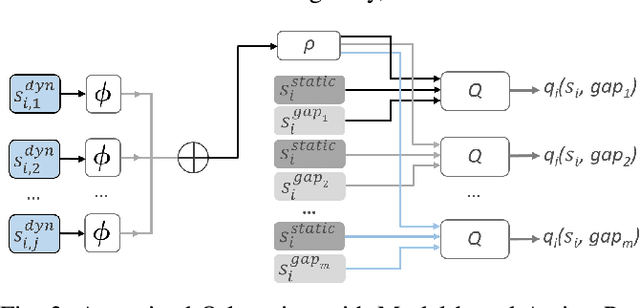
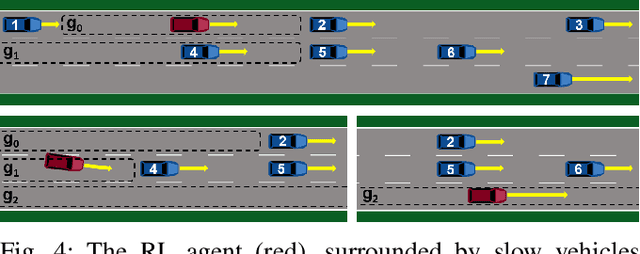
Well-established optimization-based methods can guarantee an optimal trajectory for a short optimization horizon, typically no longer than a few seconds. As a result, choosing the optimal trajectory for this short horizon may still result in a sub-optimal long-term solution. At the same time, the resulting short-term trajectories allow for effective, comfortable and provable safe maneuvers in a dynamic traffic environment. In this work, we address the question of how to ensure an optimal long-term driving strategy, while keeping the benefits of classical trajectory planning. We introduce a Reinforcement Learning based approach that coupled with a trajectory planner, learns an optimal long-term decision-making strategy for driving on highways. By online generating locally optimal maneuvers as actions, we balance between the infinite low-level continuous action space, and the limited flexibility of a fixed number of predefined standard lane-change actions. We evaluated our method on realistic scenarios in the open-source traffic simulator SUMO and were able to achieve better performance than the 4 benchmark approaches we compared against, including a random action selecting agent, greedy agent, high-level, discrete actions agent and an IDM-based SUMO-controlled agent.
Deep Surrogate Q-Learning for Autonomous Driving
Oct 21, 2020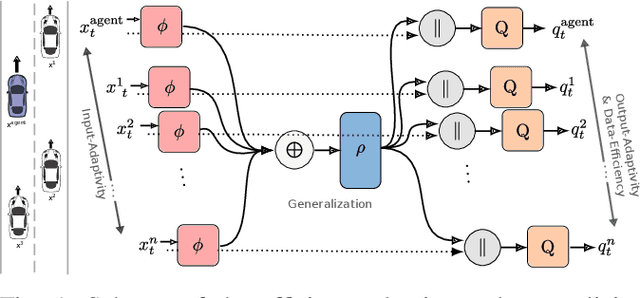

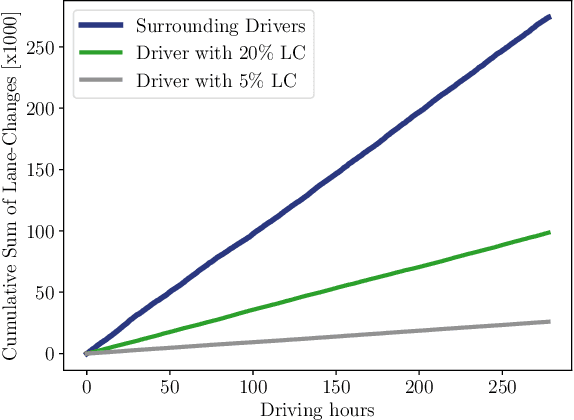
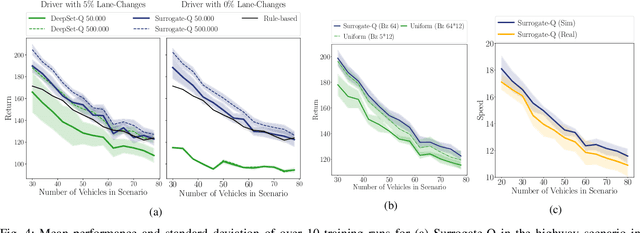
Challenging problems of deep reinforcement learning systems with regard to the application on real systems are their adaptivity to changing environments and their efficiency w.r.t. computational resources and data. In the application of learning lane-change behavior for autonomous driving, agents have to deal with a varying number of surrounding vehicles. Furthermore, the number of required transitions imposes a bottleneck, since test drivers cannot perform an arbitrary amount of lane changes in the real world. In the off-policy setting, additional information on solving the task can be gained by observing actions from others. While in the classical RL setup this knowledge remains unused, we use other drivers as surrogates to learn the agent's value function more efficiently. We propose Surrogate Q-learning that deals with the aforementioned problems and reduces the required driving time drastically. We further propose an efficient implementation based on a permutation-equivariant deep neural network architecture of the Q-function to estimate action-values for a variable number of vehicles in sensor range. We show that the architecture leads to a novel replay sampling technique we call Scene-centric Experience Replay and evaluate the performance of Surrogate Q-learning and Scene-centric Experience Replay in the open traffic simulator SUMO. Additionally, we show that our methods enhance real-world applicability of RL systems by learning policies on the real highD dataset.
A Dynamic Deep Neural Network For Multimodal Clinical Data Analysis
Aug 14, 2020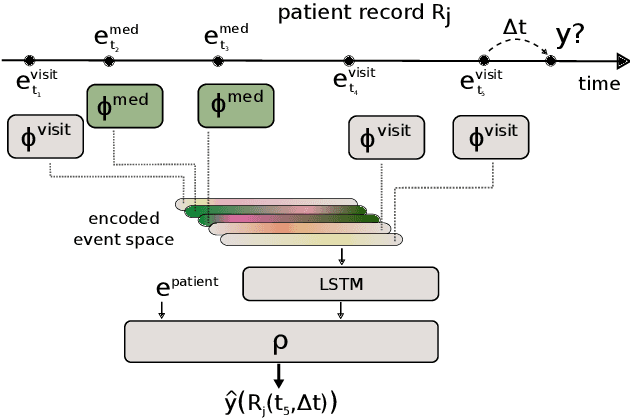
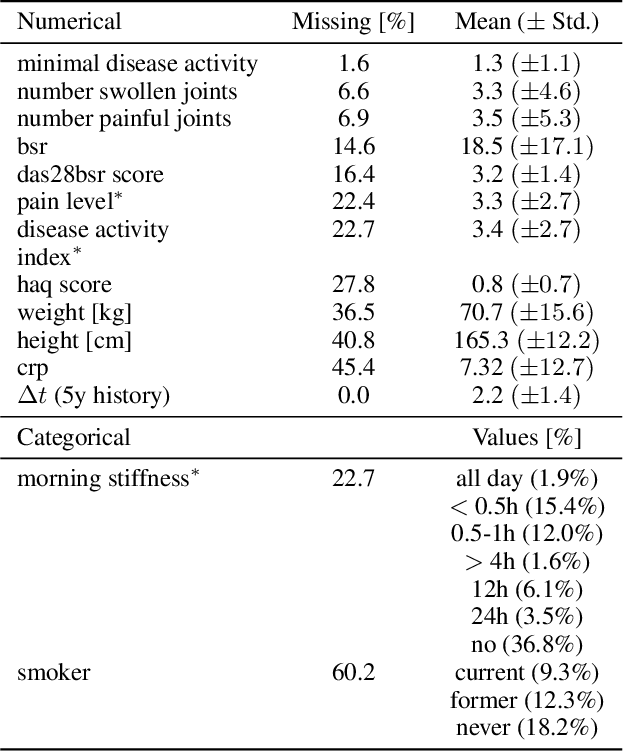
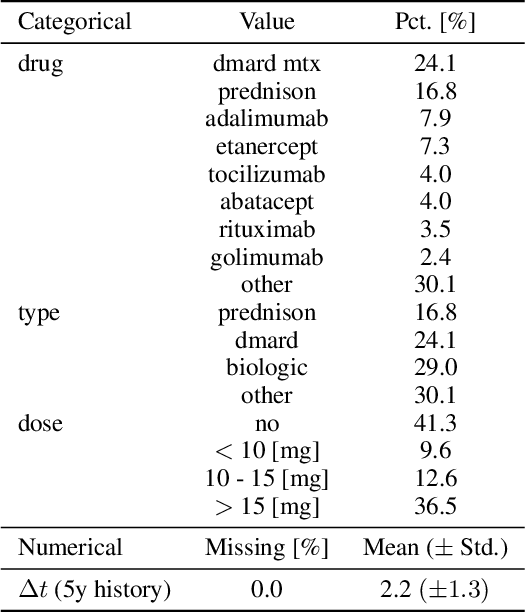
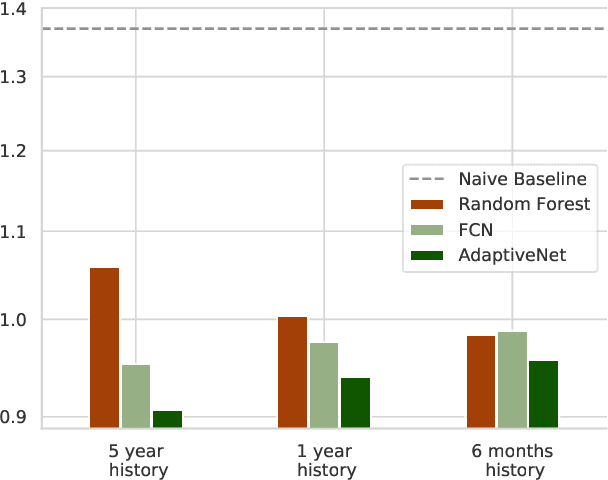
Clinical data from electronic medical records, registries or trials provide a large source of information to apply machine learning methods in order to foster precision medicine, e.g. by finding new disease phenotypes or performing individual disease prediction. However, to take full advantage of deep learning methods on clinical data, architectures are necessary that 1) are robust with respect to missing and wrong values, and 2) can deal with highly variable-sized lists and long-term dependencies of individual diagnosis, procedures, measurements and medication prescriptions. In this work, we elaborate limitations of fully-connected neural networks and classical machine learning methods in this context and propose AdaptiveNet, a novel recurrent neural network architecture, which can deal with multiple lists of different events, alleviating the aforementioned limitations. We employ the architecture to the problem of disease progression prediction in rheumatoid arthritis using the Swiss Clinical Quality Management registry, which contains over 10.000 patients and more than 65.000 patient visits. Our proposed approach leads to more compact representations and outperforms the classical baselines.