 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Alignment in Forward-Backward Representations via Temporal Abstraction
Mar 23, 2026Forward-backward (FB) representations provide a powerful framework for learning the successor representation (SR) in continuous spaces by enforcing a low-rank factorization. However, a fundamental spectral mismatch often exists between the high-rank transition dynamics of continuous environments and the low-rank bottleneck of the FB architecture, making accurate low-rank representation learning difficult. In this work, we analyze temporal abstraction as a mechanism to mitigate this mismatch. By characterizing the spectral properties of the transition operator, we show that temporal abstraction acts as a low-pass filter that suppresses high-frequency spectral components. This suppression reduces the effective rank of the induced SR while preserving a formal bound on the resulting value function error. Empirically, we show that this alignment is a key factor for stable FB learning, particularly at high discount factors where bootstrapping becomes error-prone. Our results identify temporal abstraction as a principled mechanism for shaping the spectral structure of the underlying MDP and enabling effective long-horizon representations in continuous control.
SR-Reward: Taking The Path More Traveled
Jan 04, 2025



In this paper, we propose a novel method for learning reward functions directly from offline demonstrations. Unlike traditional inverse reinforcement learning (IRL), our approach decouples the reward function from the learner's policy, eliminating the adversarial interaction typically required between the two. This results in a more stable and efficient training process. Our reward function, called \textit{SR-Reward}, leverages successor representation (SR) to encode a state based on expected future states' visitation under the demonstration policy and transition dynamics. By utilizing the Bellman equation, SR-Reward can be learned concurrently with most reinforcement learning (RL) algorithms without altering the existing training pipeline. We also introduce a negative sampling strategy to mitigate overestimation errors by reducing rewards for out-of-distribution data, thereby enhancing robustness. This strategy inherently introduces a conservative bias into RL algorithms that employ the learned reward. We evaluate our method on the D4RL benchmark, achieving competitive results compared to offline RL algorithms with access to true rewards and imitation learning (IL) techniques like behavioral cloning. Moreover, our ablation studies on data size and quality reveal the advantages and limitations of SR-Reward as a proxy for true rewards.
T3VIP: Transformation-based 3D Video Prediction
Sep 19, 2022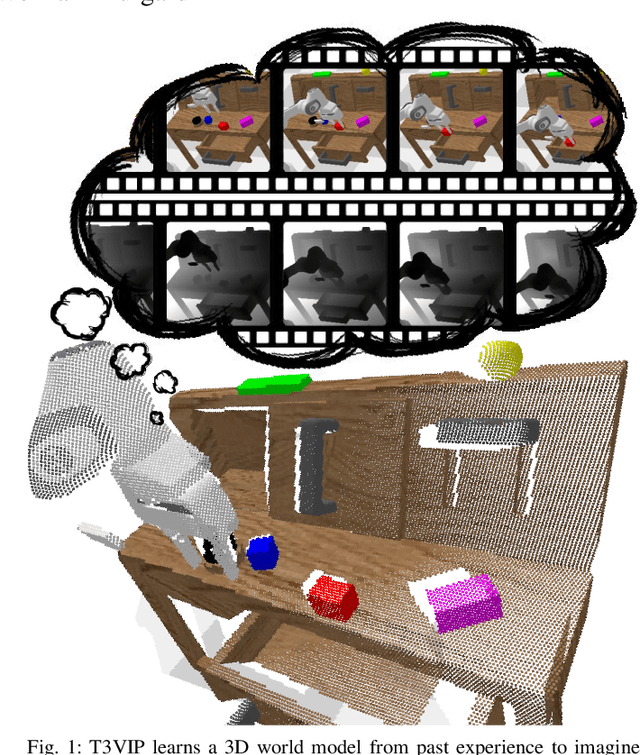
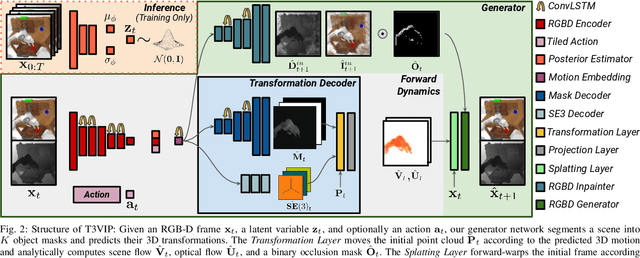
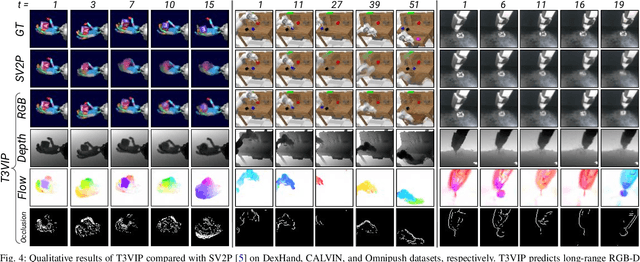
For autonomous skill acquisition, robots have to learn about the physical rules governing the 3D world dynamics from their own past experience to predict and reason about plausible future outcomes. To this end, we propose a transformation-based 3D video prediction (T3VIP) approach that explicitly models the 3D motion by decomposing a scene into its object parts and predicting their corresponding rigid transformations. Our model is fully unsupervised, captures the stochastic nature of the real world, and the observational cues in image and point cloud domains constitute its learning signals. To fully leverage all the 2D and 3D observational signals, we equip our model with automatic hyperparameter optimization (HPO) to interpret the best way of learning from them. To the best of our knowledge, our model is the first generative model that provides an RGB-D video prediction of the future for a static camera. Our extensive evaluation with simulated and real-world datasets demonstrates that our formulation leads to interpretable 3D models that predict future depth videos while achieving on-par performance with 2D models on RGB video prediction. Moreover, we demonstrate that our model outperforms 2D baselines on visuomotor control. Videos, code, dataset, and pre-trained models are available at http://t3vip.cs.uni-freiburg.de.