 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeT3VIP: Transformation-based 3D Video Prediction
Sep 19, 2022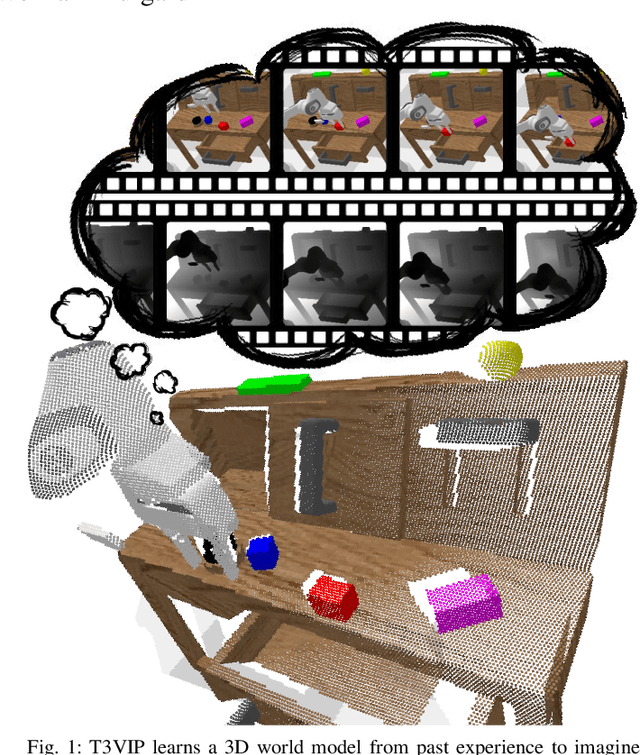
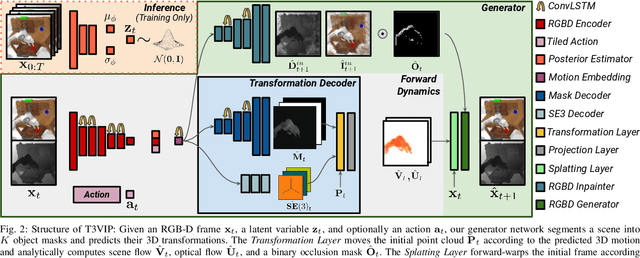
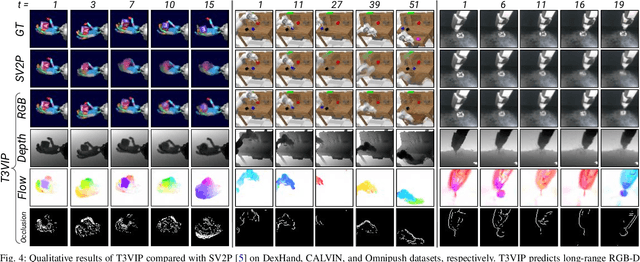
For autonomous skill acquisition, robots have to learn about the physical rules governing the 3D world dynamics from their own past experience to predict and reason about plausible future outcomes. To this end, we propose a transformation-based 3D video prediction (T3VIP) approach that explicitly models the 3D motion by decomposing a scene into its object parts and predicting their corresponding rigid transformations. Our model is fully unsupervised, captures the stochastic nature of the real world, and the observational cues in image and point cloud domains constitute its learning signals. To fully leverage all the 2D and 3D observational signals, we equip our model with automatic hyperparameter optimization (HPO) to interpret the best way of learning from them. To the best of our knowledge, our model is the first generative model that provides an RGB-D video prediction of the future for a static camera. Our extensive evaluation with simulated and real-world datasets demonstrates that our formulation leads to interpretable 3D models that predict future depth videos while achieving on-par performance with 2D models on RGB video prediction. Moreover, we demonstrate that our model outperforms 2D baselines on visuomotor control. Videos, code, dataset, and pre-trained models are available at http://t3vip.cs.uni-freiburg.de.
Latent Plans for Task-Agnostic Offline Reinforcement Learning
Sep 19, 2022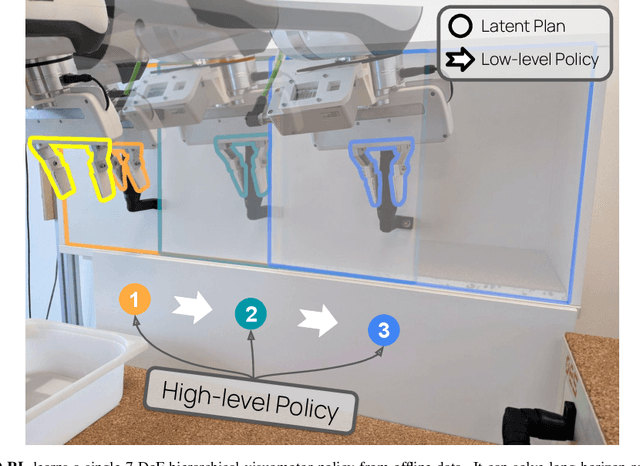
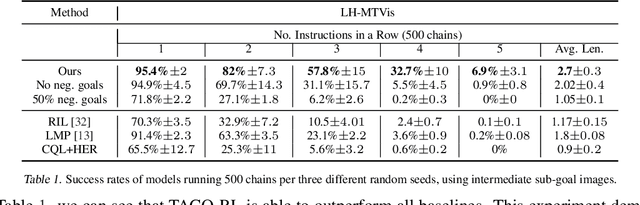
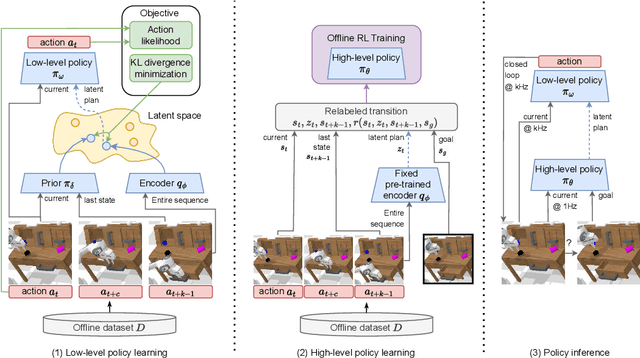
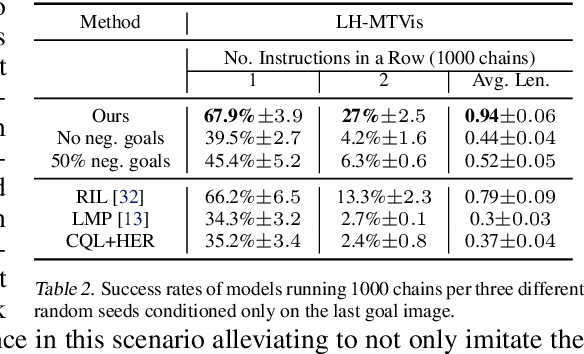
Everyday tasks of long-horizon and comprising a sequence of multiple implicit subtasks still impose a major challenge in offline robot control. While a number of prior methods aimed to address this setting with variants of imitation and offline reinforcement learning, the learned behavior is typically narrow and often struggles to reach configurable long-horizon goals. As both paradigms have complementary strengths and weaknesses, we propose a novel hierarchical approach that combines the strengths of both methods to learn task-agnostic long-horizon policies from high-dimensional camera observations. Concretely, we combine a low-level policy that learns latent skills via imitation learning and a high-level policy learned from offline reinforcement learning for skill-chaining the latent behavior priors. Experiments in various simulated and real robot control tasks show that our formulation enables producing previously unseen combinations of skills to reach temporally extended goals by "stitching" together latent skills through goal chaining with an order-of-magnitude improvement in performance upon state-of-the-art baselines. We even learn one multi-task visuomotor policy for 25 distinct manipulation tasks in the real world which outperforms both imitation learning and offline reinforcement learning techniques.
CALVIN: A Benchmark for Language-conditioned Policy Learning for Long-horizon Robot Manipulation Tasks
Dec 08, 2021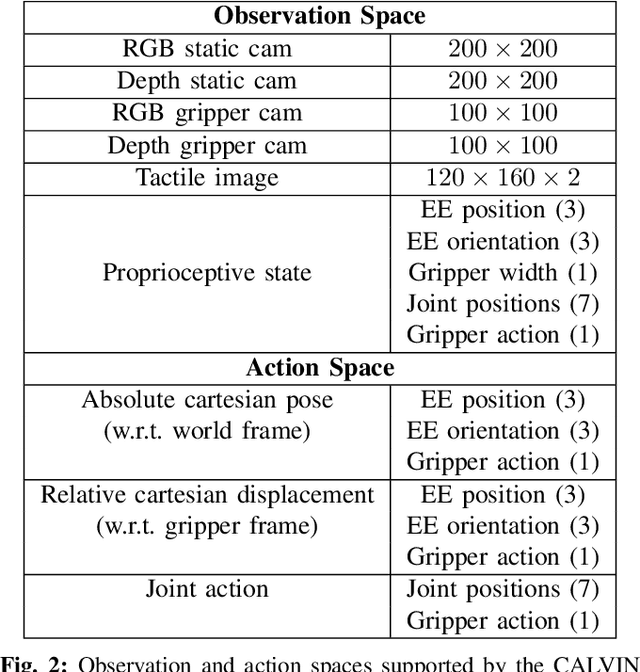
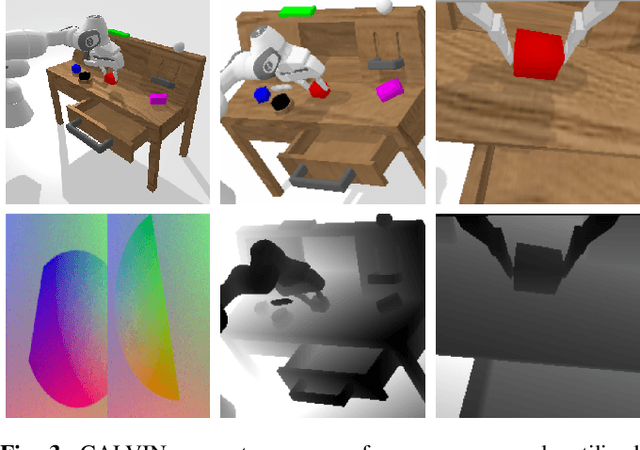
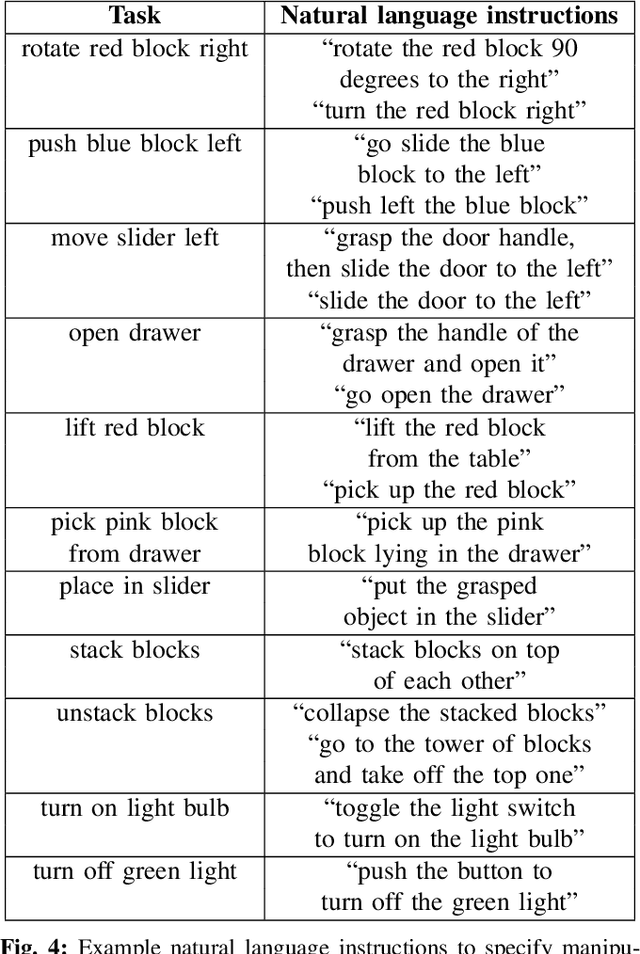

General-purpose robots coexisting with humans in their environment must learn to relate human language to their perceptions and actions to be useful in a range of daily tasks. Moreover, they need to acquire a diverse repertoire of general-purpose skills that allow composing long-horizon tasks by following unconstrained language instructions. In this paper, we present CALVIN (Composing Actions from Language and Vision), an open-source simulated benchmark to learn long-horizon language-conditioned tasks. Our aim is to make it possible to develop agents that can solve many robotic manipulation tasks over a long horizon, from onboard sensors, and specified only via human language. CALVIN tasks are more complex in terms of sequence length, action space, and language than existing vision-and-language task datasets and supports flexible specification of sensor suites. We evaluate the agents in zero-shot to novel language instructions and to novel environments and objects. We show that a baseline model based on multi-context imitation learning performs poorly on CALVIN, suggesting that there is significant room for developing innovative agents that learn to relate human language to their world models with this benchmark.
Robot Skill Adaptation via Soft Actor-Critic Gaussian Mixture Models
Nov 25, 2021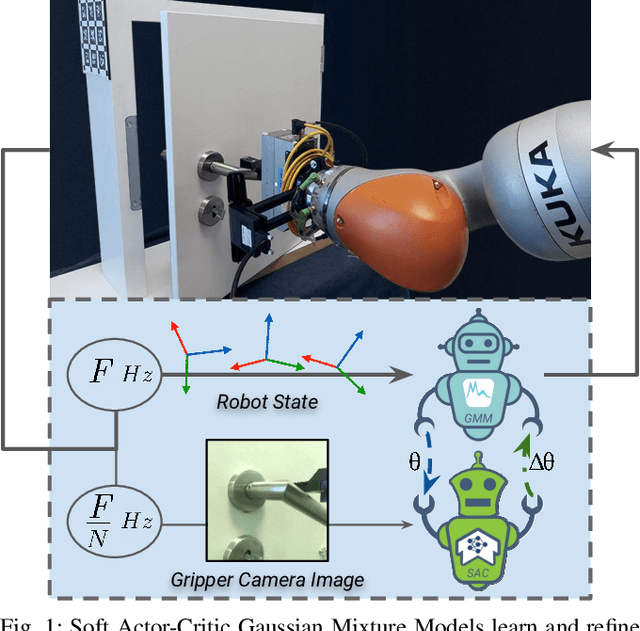
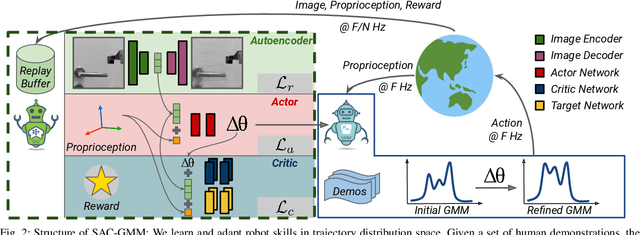


A core challenge for an autonomous agent acting in the real world is to adapt its repertoire of skills to cope with its noisy perception and dynamics. To scale learning of skills to long-horizon tasks, robots should be able to learn and later refine their skills in a structured manner through trajectories rather than making instantaneous decisions individually at each time step. To this end, we propose the Soft Actor-Critic Gaussian Mixture Model (SAC-GMM), a novel hybrid approach that learns robot skills through a dynamical system and adapts the learned skills in their own trajectory distribution space through interactions with the environment. Our approach combines classical robotics techniques of learning from demonstration with the deep reinforcement learning framework and exploits their complementary nature. We show that our method utilizes sensors solely available during the execution of preliminarily learned skills to extract relevant features that lead to faster skill refinement. Extensive evaluations in both simulation and real-world environments demonstrate the effectiveness of our method in refining robot skills by leveraging physical interactions, high-dimensional sensory data, and sparse task completion rewards. Videos, code, and pre-trained models are available at \url{http://sac-gmm.cs.uni-freiburg.de}.