 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Neural Compass: Probabilistic Relative Feature Fields for Robotic Search
Mar 09, 2026Object co-occurrences provide a key cue for finding objects successfully and efficiently in unfamiliar environments. Typically, one looks for cups in kitchens and views fridges as evidence of being in a kitchen. Such priors have also been exploited in artificial agents, but they are typically learned from explicitly labeled data or queried from language models. It is still unclear whether these relations can be learned implicitly from unlabeled observations alone. In this work, we address this problem and propose ProReFF, a feature field model trained to predict relative distributions of features obtained from pre-trained vision language models. In addition, we introduce a learning-based strategy that enables training from unlabeled and potentially contradictory data by aligning inconsistent observations into a coherent relative distribution. For the downstream object search task, we propose an agent that leverages predicted feature distributions as a semantic prior to guide exploration toward regions with a high likelihood of containing the object. We present extensive evaluations demonstrating that ProReFF captures meaningful relative feature distributions in natural scenes and provides insight into the impact of our proposed alignment step. We further evaluate the performance of our search agent in 100 challenges in the Matterport3D simulator, comparing with feature-based baselines and human participants. The proposed agent is 20% more efficient than the strongest baseline and achieves up to 80% of human performance.
SparTa: Sparse Graphical Task Models from a Handful of Demonstrations
Feb 18, 2026Learning long-horizon manipulation tasks efficiently is a central challenge in robot learning from demonstration. Unlike recent endeavors that focus on directly learning the task in the action domain, we focus on inferring what the robot should achieve in the task, rather than how to do so. To this end, we represent evolving scene states using a series of graphical object relationships. We propose a demonstration segmentation and pooling approach that extracts a series of manipulation graphs and estimates distributions over object states across task phases. In contrast to prior graph-based methods that capture only partial interactions or short temporal windows, our approach captures complete object interactions spanning from the onset of control to the end of the manipulation. To improve robustness when learning from multiple demonstrations, we additionally perform object matching using pre-trained visual features. In extensive experiments, we evaluate our method's demonstration segmentation accuracy and the utility of learning from multiple demonstrations for finding a desired minimal task model. Finally, we deploy the fitted models both in simulation and on a real robot, demonstrating that the resulting task representations support reliable execution across environments.
Articulated 3D Scene Graphs for Open-World Mobile Manipulation
Feb 18, 2026Semantics has enabled 3D scene understanding and affordance-driven object interaction. However, robots operating in real-world environments face a critical limitation: they cannot anticipate how objects move. Long-horizon mobile manipulation requires closing the gap between semantics, geometry, and kinematics. In this work, we present MoMa-SG, a novel framework for building semantic-kinematic 3D scene graphs of articulated scenes containing a myriad of interactable objects. Given RGB-D sequences containing multiple object articulations, we temporally segment object interactions and infer object motion using occlusion-robust point tracking. We then lift point trajectories into 3D and estimate articulation models using a novel unified twist estimation formulation that robustly estimates revolute and prismatic joint parameters in a single optimization pass. Next, we associate objects with estimated articulations and detect contained objects by reasoning over parent-child relations at identified opening states. We also introduce the novel Arti4D-Semantic dataset, which uniquely combines hierarchical object semantics including parent-child relation labels with object axis annotations across 62 in-the-wild RGB-D sequences containing 600 object interactions and three distinct observation paradigms. We extensively evaluate the performance of MoMa-SG on two datasets and ablate key design choices of our approach. In addition, real-world experiments on both a quadruped and a mobile manipulator demonstrate that our semantic-kinematic scene graphs enable robust manipulation of articulated objects in everyday home environments. We provide code and data at: https://momasg.cs.uni-freiburg.de.
Online Estimation and Manipulation of Articulated Objects
Jan 04, 2026From refrigerators to kitchen drawers, humans interact with articulated objects effortlessly every day while completing household chores. For automating these tasks, service robots must be capable of manipulating arbitrary articulated objects. Recent deep learning methods have been shown to predict valuable priors on the affordance of articulated objects from vision. In contrast, many other works estimate object articulations by observing the articulation motion, but this requires the robot to already be capable of manipulating the object. In this article, we propose a novel approach combining these methods by using a factor graph for online estimation of articulation which fuses learned visual priors and proprioceptive sensing during interaction into an analytical model of articulation based on Screw Theory. With our method, a robotic system makes an initial prediction of articulation from vision before touching the object, and then quickly updates the estimate from kinematic and force sensing during manipulation. We evaluate our method extensively in both simulations and real-world robotic manipulation experiments. We demonstrate several closed-loop estimation and manipulation experiments in which the robot was capable of opening previously unseen drawers. In real hardware experiments, the robot achieved a 75% success rate for autonomous opening of unknown articulated objects.
Designing for Difference: How Human Characteristics Shape Perceptions of Collaborative Robots
Jul 22, 2025The development of assistive robots for social collaboration raises critical questions about responsible and inclusive design, especially when interacting with individuals from protected groups such as those with disabilities or advanced age. Currently, research is scarce on how participants assess varying robot behaviors in combination with diverse human needs, likely since participants have limited real-world experience with advanced domestic robots. In the current study, we aim to address this gap while using methods that enable participants to assess robot behavior, as well as methods that support meaningful reflection despite limited experience. In an online study, 112 participants (from both experimental and control groups) evaluated 7 videos from a total of 28 variations of human-robot collaboration types. The experimental group first completed a cognitive-affective mapping (CAM) exercise on human-robot collaboration before providing their ratings. Although CAM reflection did not significantly affect overall ratings, it led to more pronounced assessments for certain combinations of robot behavior and human condition. Most importantly, the type of human-robot collaboration influences the assessment. Antisocial robot behavior was consistently rated as the lowest, while collaboration with aged individuals elicited more sensitive evaluations. Scenarios involving object handovers were viewed more positively than those without them. These findings suggest that both human characteristics and interaction paradigms influence the perceived acceptability of collaborative robots, underscoring the importance of prosocial design. They also highlight the potential of reflective methods, such as CAM, to elicit nuanced feedback, supporting the development of user-centered and socially responsible robotic systems tailored to diverse populations.
The Unreasonable Effectiveness of Discrete-Time Gaussian Process Mixtures for Robot Policy Learning
May 06, 2025



We present Mixture of Discrete-time Gaussian Processes (MiDiGap), a novel approach for flexible policy representation and imitation learning in robot manipulation. MiDiGap enables learning from as few as five demonstrations using only camera observations and generalizes across a wide range of challenging tasks. It excels at long-horizon behaviors such as making coffee, highly constrained motions such as opening doors, dynamic actions such as scooping with a spatula, and multimodal tasks such as hanging a mug. MiDiGap learns these tasks on a CPU in less than a minute and scales linearly to large datasets. We also develop a rich suite of tools for inference-time steering using evidence such as collision signals and robot kinematic constraints. This steering enables novel generalization capabilities, including obstacle avoidance and cross-embodiment policy transfer. MiDiGap achieves state-of-the-art performance on diverse few-shot manipulation benchmarks. On constrained RLBench tasks, it improves policy success by 76 percentage points and reduces trajectory cost by 67%. On multimodal tasks, it improves policy success by 48 percentage points and increases sample efficiency by a factor of 20. In cross-embodiment transfer, it more than doubles policy success. We make the code publicly available at https://midigap.cs.uni-freiburg.de.
Learning Few-Shot Object Placement with Intra-Category Transfer
Nov 05, 2024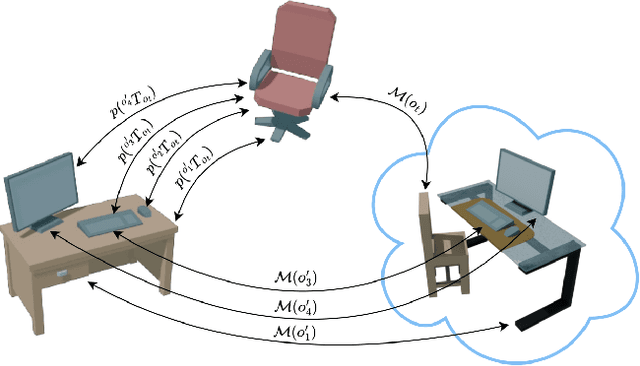
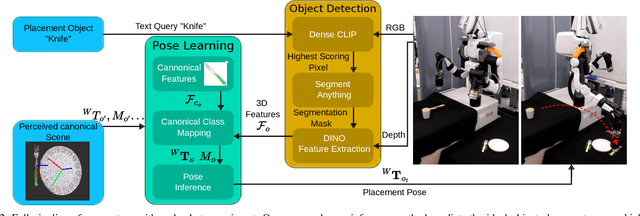
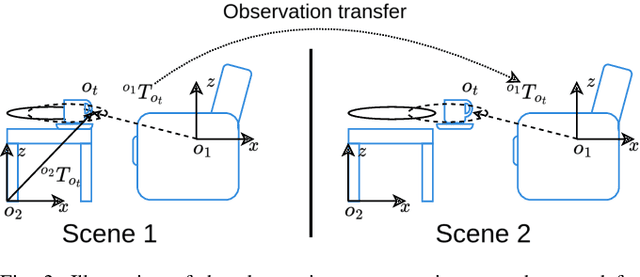
Efficient learning from demonstration for long-horizon tasks remains an open challenge in robotics. While significant effort has been directed toward learning trajectories, a recent resurgence of object-centric approaches has demonstrated improved sample efficiency, enabling transferable robotic skills. Such approaches model tasks as a sequence of object poses over time. In this work, we propose a scheme for transferring observed object arrangements to novel object instances by learning these arrangements on canonical class frames. We then employ this scheme to enable a simple yet effective approach for training models from as few as five demonstrations to predict arrangements of a wide range of objects including tableware, cutlery, furniture, and desk spaces. We propose a method for optimizing the learned models to enables efficient learning of tasks such as setting a table or tidying up an office with intra-category transfer, even in the presence of distractors. We present extensive experimental results in simulation and on a real robotic system for table setting which, based on human evaluations, scored 73.3% compared to a human baseline. We make the code and trained models publicly available at http://oplict.cs.uni-freiburg.de.
Imagine2touch: Predictive Tactile Sensing for Robotic Manipulation using Efficient Low-Dimensional Signals
May 02, 2024Humans seemingly incorporate potential touch signals in their perception. Our goal is to equip robots with a similar capability, which we term Imagine2touch. Imagine2touch aims to predict the expected touch signal based on a visual patch representing the area to be touched. We use ReSkin, an inexpensive and compact touch sensor to collect the required dataset through random touching of five basic geometric shapes, and one tool. We train Imagine2touch on two out of those shapes and validate it on the ood. tool. We demonstrate the efficacy of Imagine2touch through its application to the downstream task of object recognition. In this task, we evaluate Imagine2touch performance in two experiments, together comprising 5 out of training distribution objects. Imagine2touch achieves an object recognition accuracy of 58% after ten touches per object, surpassing a proprioception baseline.
PseudoTouch: Efficiently Imaging the Surface Feel of Objects for Robotic Manipulation
Mar 22, 2024



Humans seemingly incorporate potential touch signals in their perception. Our goal is to equip robots with a similar capability, which we term \ourmodel. \ourmodel aims to predict the expected touch signal based on a visual patch representing the touched area. We frame this problem as the task of learning a low-dimensional visual-tactile embedding, wherein we encode a depth patch from which we decode the tactile signal. To accomplish this task, we employ ReSkin, an inexpensive and replaceable magnetic-based tactile sensor. Using ReSkin, we collect and train PseudoTouch on a dataset comprising aligned tactile and visual data pairs obtained through random touching of eight basic geometric shapes. We demonstrate the efficacy of PseudoTouch through its application to two downstream tasks: object recognition and grasp stability prediction. In the object recognition task, we evaluate the learned embedding's performance on a set of five basic geometric shapes and five household objects. Using PseudoTouch, we achieve an object recognition accuracy 84% after just ten touches, surpassing a proprioception baseline. For the grasp stability task, we use ACRONYM labels to train and evaluate a grasp success predictor using PseudoTouch's predictions derived from virtual depth information. Our approach yields an impressive 32% absolute improvement in accuracy compared to the baseline relying on partial point cloud data. We make the data, code, and trained models publicly available at http://pseudotouch.cs.uni-freiburg.de.
Bayesian Optimization for Sample-Efficient Policy Improvement in Robotic Manipulation
Mar 21, 2024Sample efficient learning of manipulation skills poses a major challenge in robotics. While recent approaches demonstrate impressive advances in the type of task that can be addressed and the sensing modalities that can be incorporated, they still require large amounts of training data. Especially with regard to learning actions on robots in the real world, this poses a major problem due to the high costs associated with both demonstrations and real-world robot interactions. To address this challenge, we introduce BOpt-GMM, a hybrid approach that combines imitation learning with own experience collection. We first learn a skill model as a dynamical system encoded in a Gaussian Mixture Model from a few demonstrations. We then improve this model with Bayesian optimization building on a small number of autonomous skill executions in a sparse reward setting. We demonstrate the sample efficiency of our approach on multiple complex manipulation skills in both simulations and real-world experiments. Furthermore, we make the code and pre-trained models publicly available at http://bopt-gmm. cs.uni-freiburg.de.