 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpectral Alignment in Forward-Backward Representations via Temporal Abstraction
Mar 23, 2026Forward-backward (FB) representations provide a powerful framework for learning the successor representation (SR) in continuous spaces by enforcing a low-rank factorization. However, a fundamental spectral mismatch often exists between the high-rank transition dynamics of continuous environments and the low-rank bottleneck of the FB architecture, making accurate low-rank representation learning difficult. In this work, we analyze temporal abstraction as a mechanism to mitigate this mismatch. By characterizing the spectral properties of the transition operator, we show that temporal abstraction acts as a low-pass filter that suppresses high-frequency spectral components. This suppression reduces the effective rank of the induced SR while preserving a formal bound on the resulting value function error. Empirically, we show that this alignment is a key factor for stable FB learning, particularly at high discount factors where bootstrapping becomes error-prone. Our results identify temporal abstraction as a principled mechanism for shaping the spectral structure of the underlying MDP and enabling effective long-horizon representations in continuous control.
BLINK: Behavioral Latent Modeling of NK Cell Cytotoxicity
Mar 05, 2026Machine learning models of cellular interaction dynamics hold promise for understanding cell behavior. Natural killer (NK) cell cytotoxicity is a prominent example of such interaction dynamics and is commonly studied using time-resolved multi-channel fluorescence microscopy. Although tumor cell death events can be annotated at single frames, NK cytotoxic outcome emerges over time from cellular interactions and cannot be reliably inferred from frame-wise classification alone. We introduce BLINK, a trajectory-based recurrent state-space model that serves as a cell world model for NK-tumor interactions. BLINK learns latent interaction dynamics from partially observed NK-tumor interaction sequences and predicts apoptosis increments that accumulate into cytotoxic outcomes. Experiments on long-term time-lapse NK-tumor recordings show improved cytotoxic outcome detection and enable forecasting of future outcomes, together with an interpretable latent representation that organizes NK trajectories into coherent behavioral modes and temporally structured interaction phases. BLINK provides a unified framework for quantitative evaluation and structured modeling of NK cytotoxic behavior at the single-cell level.
LUMOS: Language-Conditioned Imitation Learning with World Models
Mar 13, 2025We introduce LUMOS, a language-conditioned multi-task imitation learning framework for robotics. LUMOS learns skills by practicing them over many long-horizon rollouts in the latent space of a learned world model and transfers these skills zero-shot to a real robot. By learning on-policy in the latent space of the learned world model, our algorithm mitigates policy-induced distribution shift which most offline imitation learning methods suffer from. LUMOS learns from unstructured play data with fewer than 1% hindsight language annotations but is steerable with language commands at test time. We achieve this coherent long-horizon performance by combining latent planning with both image- and language-based hindsight goal relabeling during training, and by optimizing an intrinsic reward defined in the latent space of the world model over multiple time steps, effectively reducing covariate shift. In experiments on the difficult long-horizon CALVIN benchmark, LUMOS outperforms prior learning-based methods with comparable approaches on chained multi-task evaluations. To the best of our knowledge, we are the first to learn a language-conditioned continuous visuomotor control for a real-world robot within an offline world model. Videos, dataset and code are available at http://lumos.cs.uni-freiburg.de.
Bayesian Optimization for Sample-Efficient Policy Improvement in Robotic Manipulation
Mar 21, 2024Sample efficient learning of manipulation skills poses a major challenge in robotics. While recent approaches demonstrate impressive advances in the type of task that can be addressed and the sensing modalities that can be incorporated, they still require large amounts of training data. Especially with regard to learning actions on robots in the real world, this poses a major problem due to the high costs associated with both demonstrations and real-world robot interactions. To address this challenge, we introduce BOpt-GMM, a hybrid approach that combines imitation learning with own experience collection. We first learn a skill model as a dynamical system encoded in a Gaussian Mixture Model from a few demonstrations. We then improve this model with Bayesian optimization building on a small number of autonomous skill executions in a sparse reward setting. We demonstrate the sample efficiency of our approach on multiple complex manipulation skills in both simulations and real-world experiments. Furthermore, we make the code and pre-trained models publicly available at http://bopt-gmm. cs.uni-freiburg.de.
Robot Skill Generalization via Keypoint Integrated Soft Actor-Critic Gaussian Mixture Models
Oct 23, 2023A long-standing challenge for a robotic manipulation system operating in real-world scenarios is adapting and generalizing its acquired motor skills to unseen environments. We tackle this challenge employing hybrid skill models that integrate imitation and reinforcement paradigms, to explore how the learning and adaptation of a skill, along with its core grounding in the scene through a learned keypoint, can facilitate such generalization. To that end, we develop Keypoint Integrated Soft Actor-Critic Gaussian Mixture Models (KIS-GMM) approach that learns to predict the reference of a dynamical system within the scene as a 3D keypoint, leveraging visual observations obtained by the robot's physical interactions during skill learning. Through conducting comprehensive evaluations in both simulated and real-world environments, we show that our method enables a robot to gain a significant zero-shot generalization to novel environments and to refine skills in the target environments faster than learning from scratch. Importantly, this is achieved without the need for new ground truth data. Moreover, our method effectively copes with scene displacements.
T3VIP: Transformation-based 3D Video Prediction
Sep 19, 2022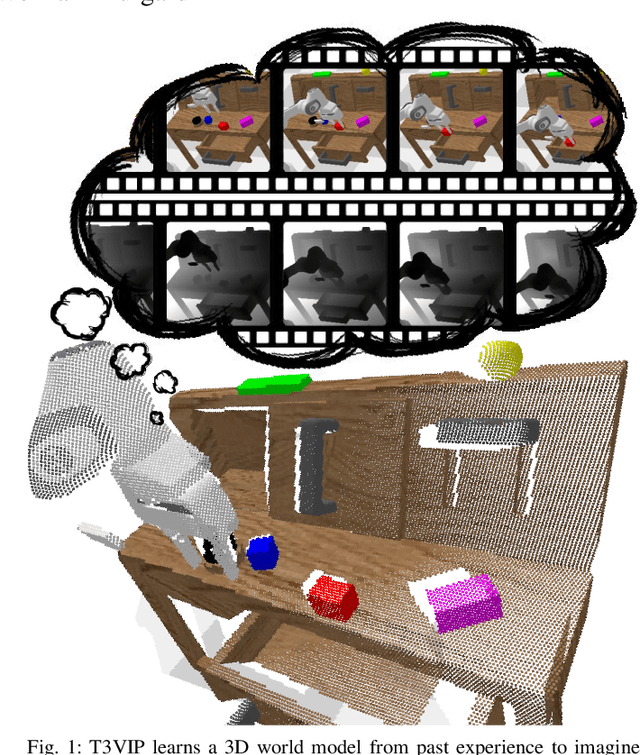
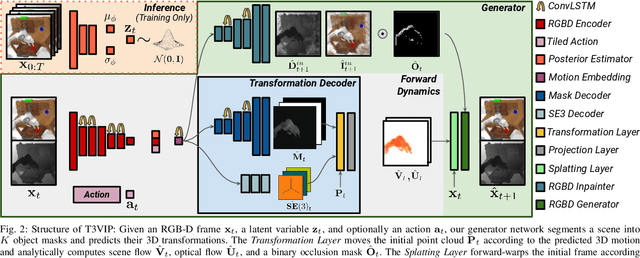
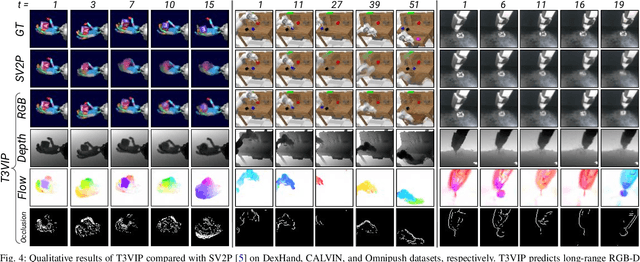
For autonomous skill acquisition, robots have to learn about the physical rules governing the 3D world dynamics from their own past experience to predict and reason about plausible future outcomes. To this end, we propose a transformation-based 3D video prediction (T3VIP) approach that explicitly models the 3D motion by decomposing a scene into its object parts and predicting their corresponding rigid transformations. Our model is fully unsupervised, captures the stochastic nature of the real world, and the observational cues in image and point cloud domains constitute its learning signals. To fully leverage all the 2D and 3D observational signals, we equip our model with automatic hyperparameter optimization (HPO) to interpret the best way of learning from them. To the best of our knowledge, our model is the first generative model that provides an RGB-D video prediction of the future for a static camera. Our extensive evaluation with simulated and real-world datasets demonstrates that our formulation leads to interpretable 3D models that predict future depth videos while achieving on-par performance with 2D models on RGB video prediction. Moreover, we demonstrate that our model outperforms 2D baselines on visuomotor control. Videos, code, dataset, and pre-trained models are available at http://t3vip.cs.uni-freiburg.de.
Robot Skill Adaptation via Soft Actor-Critic Gaussian Mixture Models
Nov 25, 2021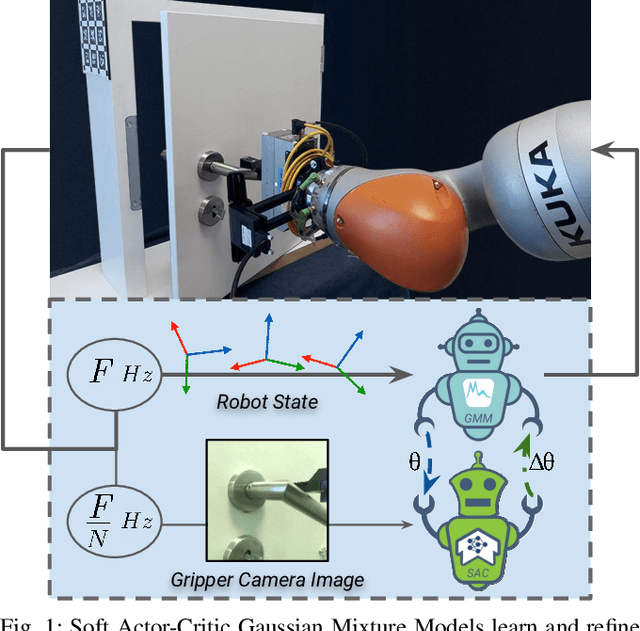
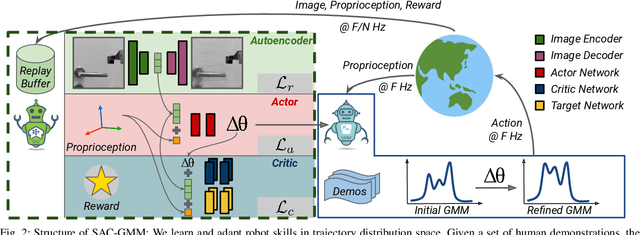


A core challenge for an autonomous agent acting in the real world is to adapt its repertoire of skills to cope with its noisy perception and dynamics. To scale learning of skills to long-horizon tasks, robots should be able to learn and later refine their skills in a structured manner through trajectories rather than making instantaneous decisions individually at each time step. To this end, we propose the Soft Actor-Critic Gaussian Mixture Model (SAC-GMM), a novel hybrid approach that learns robot skills through a dynamical system and adapts the learned skills in their own trajectory distribution space through interactions with the environment. Our approach combines classical robotics techniques of learning from demonstration with the deep reinforcement learning framework and exploits their complementary nature. We show that our method utilizes sensors solely available during the execution of preliminarily learned skills to extract relevant features that lead to faster skill refinement. Extensive evaluations in both simulation and real-world environments demonstrate the effectiveness of our method in refining robot skills by leveraging physical interactions, high-dimensional sensory data, and sparse task completion rewards. Videos, code, and pre-trained models are available at \url{http://sac-gmm.cs.uni-freiburg.de}.
Hindsight for Foresight: Unsupervised Structured Dynamics Models from Physical Interaction
Aug 02, 2020
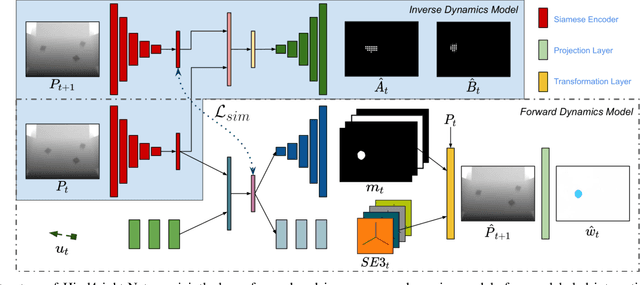
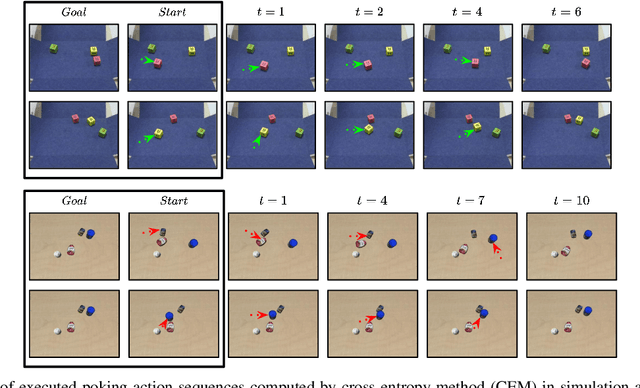
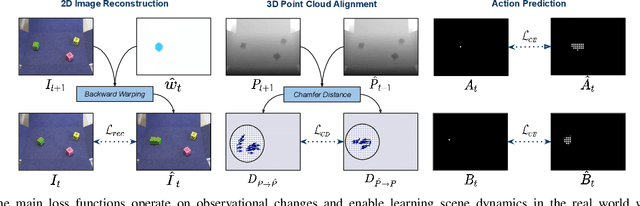
A key challenge for an agent learning to interact with the world is to reason about physical properties of objects and to foresee their dynamics under the effect of applied forces. In order to scale learning through interaction to many objects and scenes, robots should be able to improve their own performance from real-world experience without requiring human supervision. To this end, we propose a novel approach for modeling the dynamics of a robot's interactions directly from unlabeled 3D point clouds and images. Unlike previous approaches, our method does not require ground-truth data associations provided by a tracker or any pre-trained perception network. To learn from unlabeled real-world interaction data, we enforce consistency of estimated 3D clouds, actions and 2D images with observed ones. Our joint forward and inverse network learns to segment a scene into salient object parts and predicts their 3D motion under the effect of applied actions. Moreover, our object-centric model outputs action-conditioned 3D scene flow, object masks and 2D optical flow as emergent properties. Our extensive evaluation both in simulation and with real-world data demonstrates that our formulation leads to effective, interpretable models that can be used for visuomotor control and planning. Videos, code and dataset are available at http://hind4sight.cs.uni-freiburg.de