 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHindsight for Foresight: Unsupervised Structured Dynamics Models from Physical Interaction
Paper and Code
Aug 02, 2020
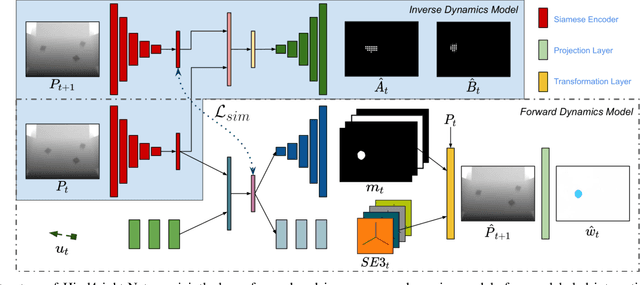
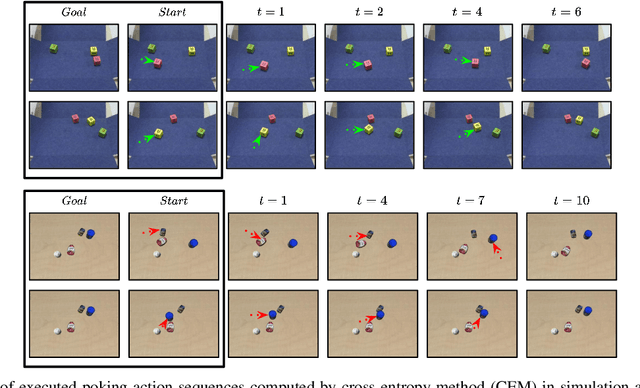
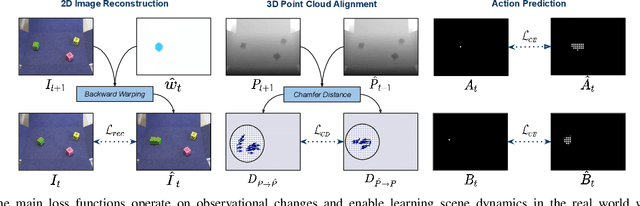
A key challenge for an agent learning to interact with the world is to reason about physical properties of objects and to foresee their dynamics under the effect of applied forces. In order to scale learning through interaction to many objects and scenes, robots should be able to improve their own performance from real-world experience without requiring human supervision. To this end, we propose a novel approach for modeling the dynamics of a robot's interactions directly from unlabeled 3D point clouds and images. Unlike previous approaches, our method does not require ground-truth data associations provided by a tracker or any pre-trained perception network. To learn from unlabeled real-world interaction data, we enforce consistency of estimated 3D clouds, actions and 2D images with observed ones. Our joint forward and inverse network learns to segment a scene into salient object parts and predicts their 3D motion under the effect of applied actions. Moreover, our object-centric model outputs action-conditioned 3D scene flow, object masks and 2D optical flow as emergent properties. Our extensive evaluation both in simulation and with real-world data demonstrates that our formulation leads to effective, interpretable models that can be used for visuomotor control and planning. Videos, code and dataset are available at http://hind4sight.cs.uni-freiburg.de