 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPLATART: Articulated Gaussian Splatting with Estimated Object Structure
Jun 13, 2025Representing articulated objects remains a difficult problem within the field of robotics. Objects such as pliers, clamps, or cabinets require representations that capture not only geometry and color information, but also part seperation, connectivity, and joint parametrization. Furthermore, learning these representations becomes even more difficult with each additional degree of freedom. Complex articulated objects such as robot arms may have seven or more degrees of freedom, and the depth of their kinematic tree may be notably greater than the tools, drawers, and cabinets that are the typical subjects of articulated object research. To address these concerns, we introduce SPLATART - a pipeline for learning Gaussian splat representations of articulated objects from posed images, of which a subset contains image space part segmentations. SPLATART disentangles the part separation task from the articulation estimation task, allowing for post-facto determination of joint estimation and representation of articulated objects with deeper kinematic trees than previously exhibited. In this work, we present data on the SPLATART pipeline as applied to the syntheic Paris dataset objects, and qualitative results on a real-world object under spare segmentation supervision. We additionally present on articulated serial chain manipulators to demonstrate usage on deeper kinematic tree structures.
Configurable Embodied Data Generation for Class-Agnostic RGB-D Video Segmentation
Oct 16, 2024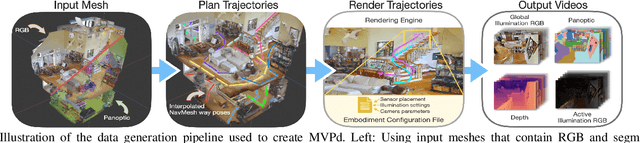

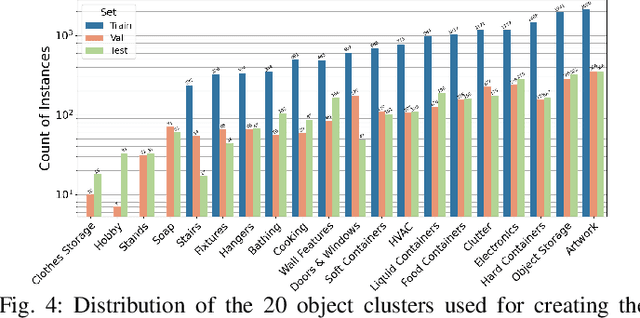
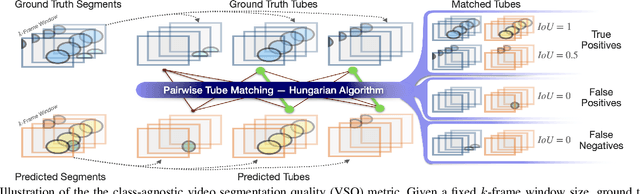
This paper presents a method for generating large-scale datasets to improve class-agnostic video segmentation across robots with different form factors. Specifically, we consider the question of whether video segmentation models trained on generic segmentation data could be more effective for particular robot platforms if robot embodiment is factored into the data generation process. To answer this question, a pipeline is formulated for using 3D reconstructions (e.g. from HM3DSem) to generate segmented videos that are configurable based on a robot's embodiment (e.g. sensor type, sensor placement, and illumination source). A resulting massive RGB-D video panoptic segmentation dataset (MVPd) is introduced for extensive benchmarking with foundation and video segmentation models, as well as to support embodiment-focused research in video segmentation. Our experimental findings demonstrate that using MVPd for finetuning can lead to performance improvements when transferring foundation models to certain robot embodiments, such as specific camera placements. These experiments also show that using 3D modalities (depth images and camera pose) can lead to improvements in video segmentation accuracy and consistency. The project webpage is available at https://topipari.com/projects/MVPd
NARF24: Estimating Articulated Object Structure for Implicit Rendering
Sep 15, 2024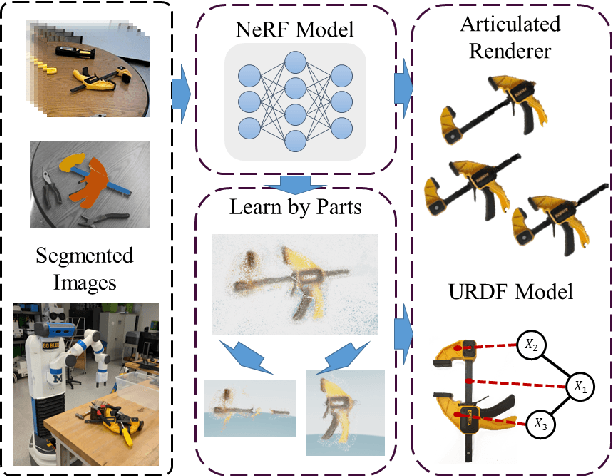



Articulated objects and their representations pose a difficult problem for robots. These objects require not only representations of geometry and texture, but also of the various connections and joint parameters that make up each articulation. We propose a method that learns a common Neural Radiance Field (NeRF) representation across a small number of collected scenes. This representation is combined with a parts-based image segmentation to produce an implicit space part localization, from which the connectivity and joint parameters of the articulated object can be estimated, thus enabling configuration-conditioned rendering.
Single-View 3D Reconstruction via SO(2)-Equivariant Gaussian Sculpting Networks
Sep 11, 2024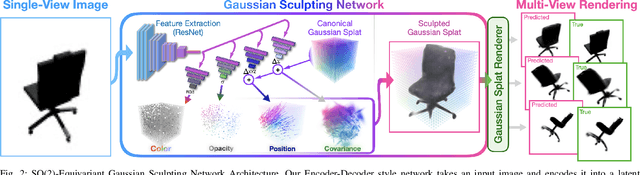
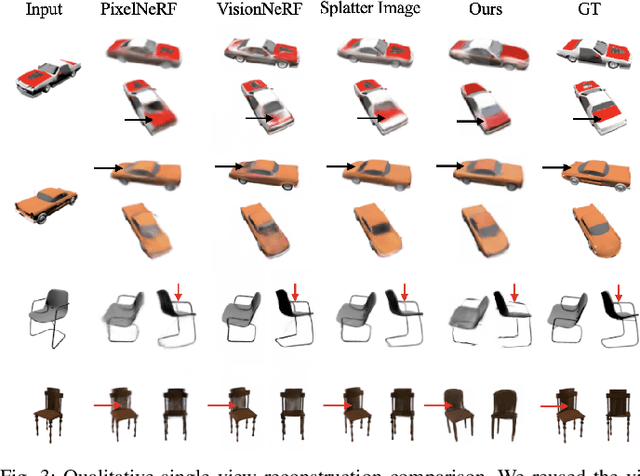

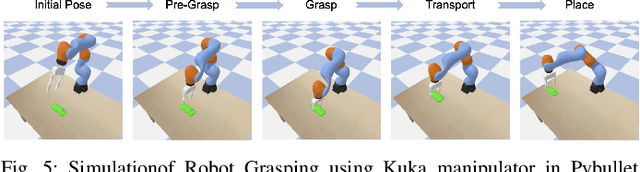
This paper introduces SO(2)-Equivariant Gaussian Sculpting Networks (GSNs) as an approach for SO(2)-Equivariant 3D object reconstruction from single-view image observations. GSNs take a single observation as input to generate a Gaussian splat representation describing the observed object's geometry and texture. By using a shared feature extractor before decoding Gaussian colors, covariances, positions, and opacities, GSNs achieve extremely high throughput (>150FPS). Experiments demonstrate that GSNs can be trained efficiently using a multi-view rendering loss and are competitive, in quality, with expensive diffusion-based reconstruction algorithms. The GSN model is validated on multiple benchmark experiments. Moreover, we demonstrate the potential for GSNs to be used within a robotic manipulation pipeline for object-centric grasping.
ROB 204: Introduction to Human-Robot Systems at the University of Michigan, Ann Arbor
May 23, 2024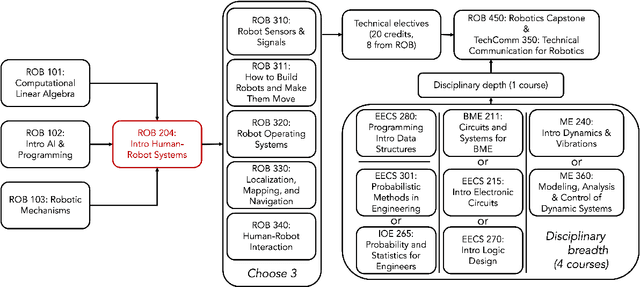

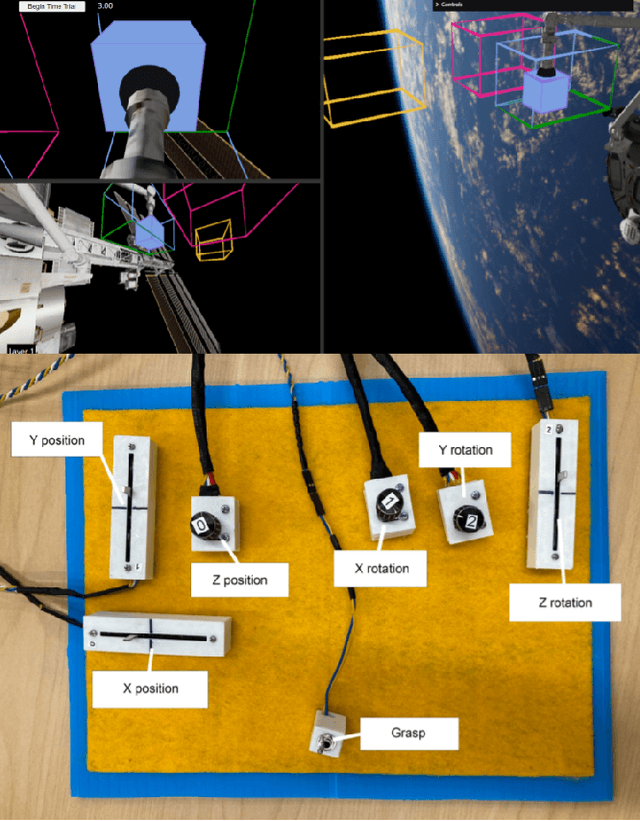

The University of Michigan Robotics program focuses on the study of embodied intelligence that must sense, reason, act, and work with people to improve quality of life and productivity equitably across society. ROB 204, part of the core curriculum towards the undergraduate degree in Robotics, introduces students to topics that enable conceptually designing a robotic system to address users' needs from a sociotechnical context. Students are introduced to human-robot interaction (HRI) concepts and the process for socially-engaged design with a Learn-Reinforce-Integrate approach. In this paper, we discuss the course topics and our teaching methodology, and provide recommendations for delivering this material. Overall, students leave the course with a new understanding and appreciation for how human capabilities can inform requirements for a robotics system, how humans can interact with a robot, and how to assess the usability of robotic systems.
OVAL-Prompt: Open-Vocabulary Affordance Localization for Robot Manipulation through LLM Affordance-Grounding
Apr 17, 2024



In order for robots to interact with objects effectively, they must understand the form and function of each object they encounter. Essentially, robots need to understand which actions each object affords, and where those affordances can be acted on. Robots are ultimately expected to operate in unstructured human environments, where the set of objects and affordances is not known to the robot before deployment (i.e. the open-vocabulary setting). In this work, we introduce OVAL-Prompt, a prompt-based approach for open-vocabulary affordance localization in RGB-D images. By leveraging a Vision Language Model (VLM) for open-vocabulary object part segmentation and a Large Language Model (LLM) to ground each part-segment-affordance, OVAL-Prompt demonstrates generalizability to novel object instances, categories, and affordances without domain-specific finetuning. Quantitative experiments demonstrate that without any finetuning, OVAL-Prompt achieves localization accuracy that is competitive with supervised baseline models. Moreover, qualitative experiments show that OVAL-Prompt enables affordance-based robot manipulation of open-vocabulary object instances and categories.
MBot: A Modular Ecosystem for Scalable Robotics Education
Dec 01, 2023



The Michigan Robotics MBot is a low-cost mobile robot platform that has been used to train over 1,400 students in autonomous navigation since 2014 at the University of Michigan and our collaborating colleges. The MBot platform was designed to meet the needs of teaching robotics at scale to match the growth of robotics as a field and an academic discipline. Transformative advancements in robot navigation over the past decades have led to a significant demand for skilled roboticists across industry and academia. This demand has sparked a need for robotics courses in higher education, spanning all levels of undergraduate and graduate experiences. Incorporating real robot platforms into such courses and curricula is effective for conveying the unique challenges of programming embodied agents in real-world environments and sparking student interest. However, teaching with real robots remains challenging due to the cost of hardware and the development effort involved in adapting existing hardware for a new course. In this paper, we describe the design and evolution of the MBot platform, and the underlying principals of scalability and flexibility which are keys to its success.
Stein Variational Belief Propagation for Multi-Robot Coordination
Nov 28, 2023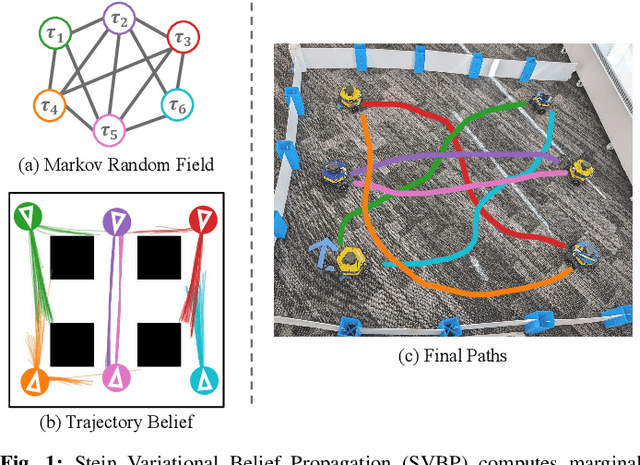
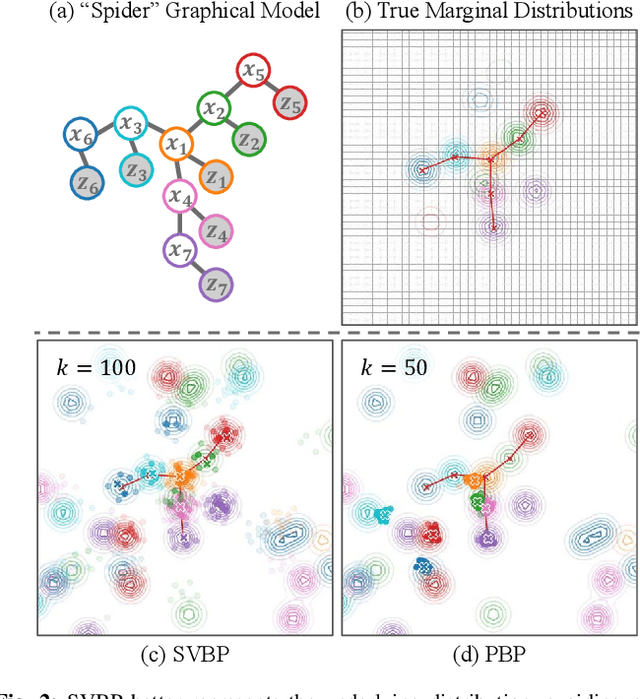
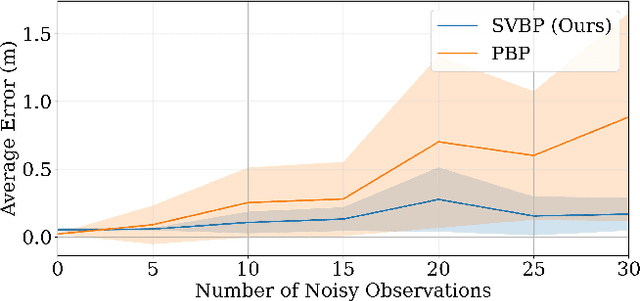
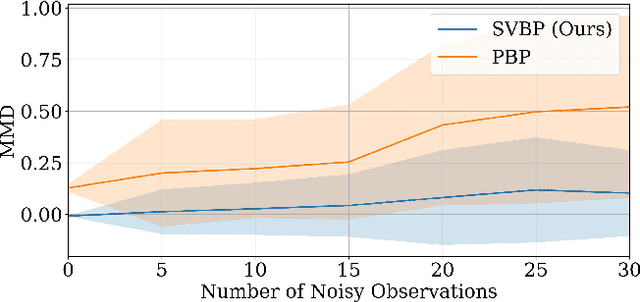
Decentralized coordination for multi-robot systems involves planning in challenging, high-dimensional spaces. The planning problem is particularly challenging in the presence of obstacles and different sources of uncertainty such as inaccurate dynamic models and sensor noise. In this paper, we introduce Stein Variational Belief Propagation (SVBP), a novel algorithm for performing inference over nonparametric marginal distributions of nodes in a graph. We apply SVBP to multi-robot coordination by modelling a robot swarm as a graphical model and performing inference for each robot. We demonstrate our algorithm on a simulated multi-robot perception task, and on a multi-robot planning task within a Model-Predictive Control (MPC) framework, on both simulated and real-world mobile robots. Our experiments show that SVBP represents multi-modal distributions better than sampling-based or Gaussian baselines, resulting in improved performance on perception and planning tasks. Furthermore, we show that SVBP's ability to represent diverse trajectories for decentralized multi-robot planning makes it less prone to deadlock scenarios than leading baselines.
The Michigan Robotics Undergraduate Curriculum: Defining the Discipline of Robotics for Equity and Excellence
Aug 14, 2023The Robotics Major at the University of Michigan was successfully launched in the 2022-23 academic year as an innovative step forward to better serve students, our communities, and our society. Building on our guiding principle of "Robotics with Respect" and our larger Robotics Pathways model, the Michigan Robotics Major was designed to define robotics as a true academic discipline with both equity and excellence as our highest priorities. Understanding that talent is equally distributed but opportunity is not, the Michigan Robotics Major has embraced an adaptable curriculum that is accessible through a diversity of student pathways and enables successful and sustained career-long participation in robotics, AI, and automation professions. The results after our planning efforts (2019-22) and first academic year (2022-23) have been highly encouraging: more than 100 students declared Robotics as their major, completion of the Robotics major by our first two graduates, soaring enrollments in our Robotics classes, thriving partnerships with Historically Black Colleges and Universities. This document provides our original curricular proposal for the Robotics Undergraduate Program at the University of Michigan, submitted to the Michigan Association of State Universities in April 2022 and approved in June 2022. The dissemination of our program design is in the spirit of continued growth for higher education towards realizing equity and excellence. The most recent version of this document is also available on Google Docs through this link: https://ocj.me/robotics_major
TransNet: Transparent Object Manipulation Through Category-Level Pose Estimation
Jul 23, 2023



Transparent objects present multiple distinct challenges to visual perception systems. First, their lack of distinguishing visual features makes transparent objects harder to detect and localize than opaque objects. Even humans find certain transparent surfaces with little specular reflection or refraction, like glass doors, difficult to perceive. A second challenge is that depth sensors typically used for opaque object perception cannot obtain accurate depth measurements on transparent surfaces due to their unique reflective properties. Stemming from these challenges, we observe that transparent object instances within the same category, such as cups, look more similar to each other than to ordinary opaque objects of that same category. Given this observation, the present paper explores the possibility of category-level transparent object pose estimation rather than instance-level pose estimation. We propose \textit{\textbf{TransNet}}, a two-stage pipeline that estimates category-level transparent object pose using localized depth completion and surface normal estimation. TransNet is evaluated in terms of pose estimation accuracy on a large-scale transparent object dataset and compared to a state-of-the-art category-level pose estimation approach. Results from this comparison demonstrate that TransNet achieves improved pose estimation accuracy on transparent objects. Moreover, we use TransNet to build an autonomous transparent object manipulation system for robotic pick-and-place and pouring tasks.